Zahlen können von Computern ausschließlich im Binären Zahlensystem gespeichert und verarbeitet werden. Dabei ergibt sich folgendes Problem: 011100111100001110111100110000111001111100001010 - Handelt es sich hier um *eine* Zahl oder um mehrere? Und wenn es sich um mehrere handelt, wo hört die eine auf und fängt die nächste an? In den folgenden Beispielen werden Striche zur Abgrenzung einzelner Zahlen verwendet: 011-100111-1000-01110111-10011000-011100111-11000010-10 011-100-111-100-001-110-111-100-110-000-111-001-111-100-001-010 ?
Zur Lösung dieses Problems hat sich in der Computertechnologie durchgesetzt, pro zu speichernder Zahl jeweils eine identische Anzahl von Ziffern des binären Zahlensystems zu verwenden, nämlich acht. Eine Einheit von acht Ziffern wird als "Byte" bezeichnet. Da mit einer achtstelligen binären Zahl maximal 256 Zahlen (0-255) dargestellt werden können, müssen höhere Zahlen unter Verwendung des Vielfachen eines Bytes gespeichert werden - auch, wenn eine Zahl beispielsweise mit neun oder zehn binären Ziffern dargestellt werden könnte. Um oben skizziertes Problem zu umgehen, müssten nun in einem definierten System alle Zahlen mit der Anzahl an Bytes kodiert werden, die für die Darstellung der höchsten im System vorkommenden Zahl erforderlich ist. Im Fall von Unicode, dessen - derzeit - höchste Zahl 100001111111111111101 (= dezimal 1114109) nur mit drei Bytes dargestellt werden kann (Durch "Aufnullen" nach links: 00010000 11111111 11111101), würde das bedeuten, dass *alle* im System verwendeten Zahlen mit jeweils drei Bytes gespeichert werden müssten. Da wenigstens bei der Verwendung westeuropäischer Schriftsysteme in den meisten Fällen Zahlen verwendet werden, die mit nur einem Byte darstellbar sind, würde es zu einer enormen Platzverschwendung kommen. Um dies zu vermeiden, wurde das UTF-8-System entwickelt, das Zahlen mit einer variablen Anzahl von Bytes abbildet:
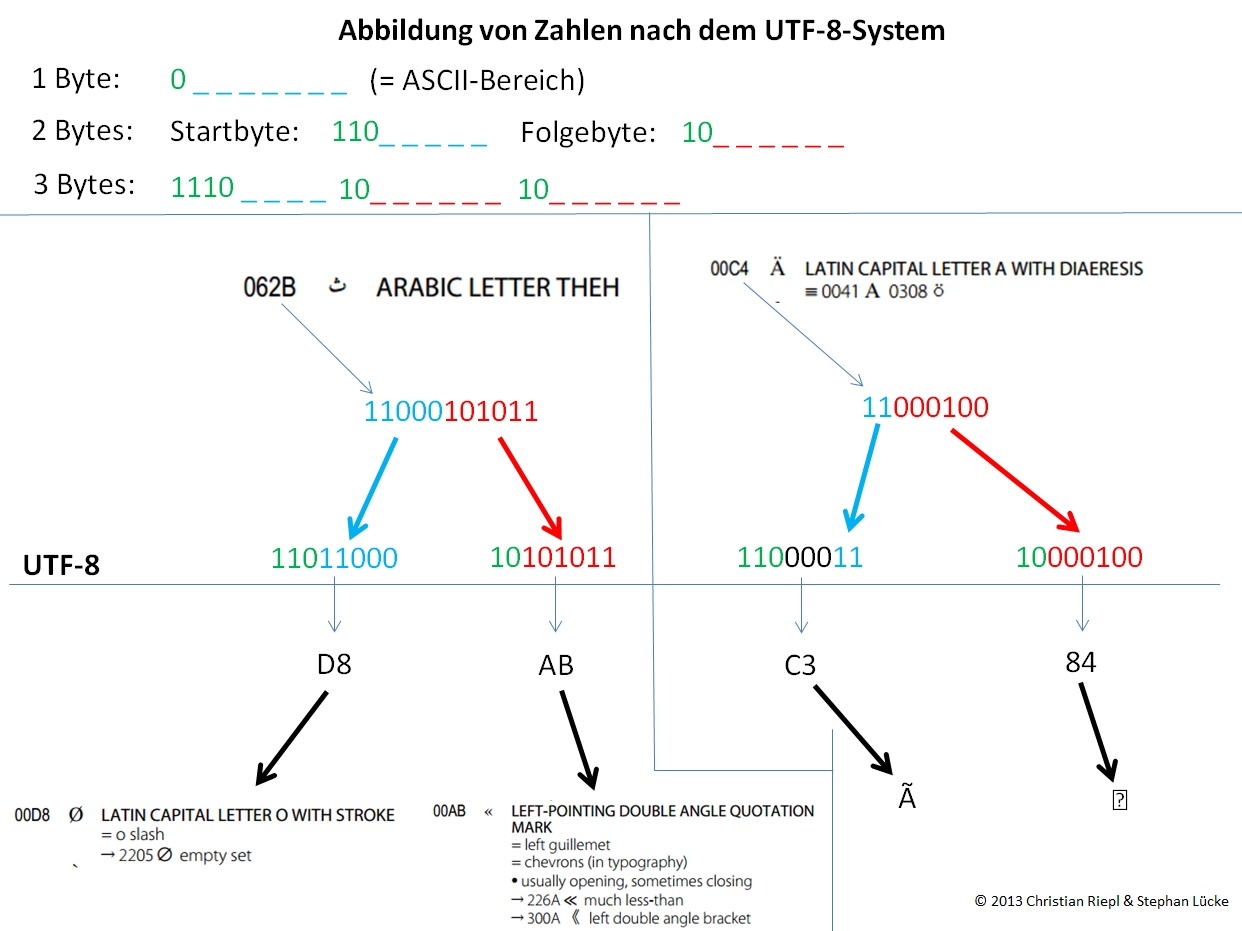
N:SharesWebDHLehrehtml/wp content/uploads/2015/11/1446726278 Utf8
In UTF-8 kodierte Texte können unter Umständen beschädigt oder gar zerstört werden. Dies geschieht dann, wenn ein in UTF-8 kodierter Text von einem Programm interpretiert wird, das die Zeichenkodierung mit einer variablen Anzahl von Bytes ignoriert und grundsätzlich jedes einzelne Byte als ein eigenes Zeichen darstellt. Der folgende Text beispielsweise wurde mit - sehr wahrscheinlich unterschiedlichen - Mailprogrammen hin- und hergeschickt:
Liebe Frau ###, jetzt hat es geklappt. Anbei das kleine awk-Programm sowie die Tokenliste in csv-Struktur. Ich importiere die Datei jetzt auch noch in Ihre neue Datenbank und benenne die Tabelle mit "tokens". Viele Grüße Stephan Lücke
Das ü (Unicode-Codepoint 11111100 = fc) im Wort Grüße wird nach UTF-8 durch die Bytefolge 11000011 10111100 (c3 bc) kodiert. Das erste Byte ist nach der Unicode-Codepage dem "LATIN CAPITAL LETTER A WITH TILDE", das zweite der "VULGAR FRACTION ONE QUARTER" zugeordnet, weswegen sich die sinnlose Zeichenfolge ü anstelle des ü ergibt.