1. Datenmodellierung/-strukturierung
1.1. Was ist "Datenmodellierung"?
Datenmodellierung ist die "Definition und Spezifikation der in einem Informationssystem zu verwaltenden Objekte, ihrer für die Informationszwecke erforderlichen Attribute und der Zusammenhänge zwischen den Informationsobjekten" (https://de.wikipedia.org/wiki/Datenmodellierung)
Andere Formulierung: Unterscheidung zwischen Daten und Metadaten. Metadaten sind Daten, die andere Daten (=Primärdaten) beschreiben. Die Gesamtheit aller Metadaten ist gegliedert in einzelne Attribute bzw. Eigenschaften.
Entscheidende Frage: Welche Einheiten ("Entitäten") werden erkannt und welche ihrer Eigenschaften sind relevant?
Als Ergebnis der Datenmodellierung liegen "strukturierte Daten" vor.
1.2. Beispiel 1
Gegeben seien mehrere archäologische Fundobjekte:
ein Schwert ein Helm eine Münze
Mögliche Modellierung:
Metadaten: ID, Kategorie (Waffe, Zahlungsmittel), Gewicht, Material, Fundort_Gemeindegebiet, Fundort_Längengrad, Fundort_Breitengrad.
Unterschiedliche Datenformate (= Möglichkeiten der Abbildung) (mit fiktiven Werten):
z.B. (Pseudo-)XML:
Blau = Metadatenkategorien, Grün = Werte, Rot = Primärdaten:
<xml> <meine_Fundobjekte> <Fundobjekt ID="1" Kategorie="Waffe" Gewicht="1.5 kg" Material="Eisen" Fundort_Gemeindegebiet="Grünwald" Fundort_Laengengrad="11.345" Fundort_Breitengrad="47.876"> Schwert </Fundojekt> <Fundobjekt ID="2" Kategorie="Verteidigungswaffe" Gewicht="0.748 kg" Material="Bronze" Fundort_Gemeindegebiet="Weilheim" Fundort_Laengengrad="11.3" Fundort_Breitengrad="47.234"> Helm </Fundojekt> <Fundobjekt ID="3" Kategorie="Zahlungsmittel" Gewicht="4 g" Material="Silber" Fundort_Gemeindegebiet="Grünwald" Fundort_Laengengrad="11.345" Fundort_Breitengrad="47.876"> Münze </Fundojekt> </meine_Fundobjekte> </xml>
Nicht selten werden XML-Daten ohne Zeilenumbrüche und Einrückungen präsentiert. Sie sind dann sehr schwer zu lesen:
<xml><meine_Fundobjekte><Fundobjekt ID="1" Kategorie="Waffe" Gewicht="1.5 kg" Material="Eisen" Fundort_Gemeindegebiet="Grünwald" Fundort_Laengengrad="11.345" Fundort_Breitengrad="47.876">Schwert</Fundojekt> <Fundobjekt ID="2" Kategorie="Verteidigungswaffe" Gewicht="0.748 kg" Material="Bronze" Fundort_Gemeindegebiet="Weilheim" Fundort_Laengengrad="11.3" Fundort_Breitengrad="47.234">Helm</Fundojekt> <Fundobjekt ID="3" Kategorie="Zahlungsmittel" Gewicht="4 g" Material="Silber" Fundort_Gemeindegebiet="Grünwald" Fundort_Laengengrad="11.345" Fundort_Breitengrad="47.876">Münze</Fundojekt></meine_Fundobjekte></xml>
weitere Möglichkeit: als Tabelle (= "relationales Datenformat"; "Relation" = Tabelle):
| ID | Bezeichnung | Kategorie | Gewicht | Material | Fundort_ Gemeindegebiet |
Fundort_ Laengengrad |
Fundort_ Breitengrad |
| 1 | Schwert | Waffe | 1.5 kg | Eisen | Grünwald | 11.345 | 47.876 |
| 2 | Helm | Verteidigungswaffe | 0.748 kg | Bronze | Weilheim | 11.3 | 47.234 |
| 3 | Münze | Zahlungsmittel | 4 g | Silber | Grünwald | 11.345 | 47.876 |
Es gibt zahlreiche weitere Datenformate für die Abbildung von strukturierten Daten. Erwähnt sei noch das sog. JSON-Format (JavaScript Object Notation):
{
"ID": 1,
"Bezeichnung": "Schwert",
"Kategorie": "Waffe",
"Gewicht": "1.5 kg",
"Material": "Eisen",
"Fundort_Gemeindegebiet": "Grünwald",
"Fundort_Laengengrad": 11.345
"Fundort_Breitengrad": 47.876
}
{
"ID": 2,
"Bezeichnung": "Helm",
"Kategorie": "Verteidigungswaffe",
"Gewicht": "0.748 kg",
"Material": "Bronze",
"Fundort_Gemeindegebiet": "Weilheim",
"Fundort_Laengengrad": 11.3
"Fundort_Breitengrad": 47.234
}
{
"ID": 3,
"Bezeichnung": "Münze",
"Kategorie": "Zahlungsmittel",
"Gewicht": "4 g",
"Material": "Silber",
"Fundort_Gemeindegebiet": "Grünwald",
"Fundort_Laengengrad": 11.345
"Fundort_Breitengrad": 47.876
}
Merke: Es gibt nie "die eine", verbindliche Modellierung; sie ist abhängig von den verfolgten Zielen
Strukturierte Daten können normalerweise von einem Format in ein anderes überführt werden. Das geht mal besser, mal schlechter: Gut: relational => XML, schlecht: XML => relational (Tool: XSLT - Extensible Stylesheet Language Transformations)
Übung: Modellieren Sie den folgenden, dem Bayerischen Denkmal-Atlas entnommenen Eintrag und bilden Sie ihn in relationalem Format ab. Verwenden Sie dazu ein Tabellenkalkulationsprogramm wie z.B. Microsoft Excel oder LibreOffice Calc (im dhvlab verfügbar):

Eintrag im Bayerischen Denkmal-Atlas (https://geoportal.bayern.de/denkmalatlas/searchResult.html?koid=214700&objtyp=boden)
Derselbe Inhalt als elektronischer Text zum Kopieren:
Geoinformation
Reg.Bez., Lkr. Oberbayern, Berchtesgadener Land
Gde., Gmkg. Bad Reichenhall, Karlstein
Denkmalliste Download Denkmäler in Bad Reichenhall
Bodendenkmal
Denkmalnummer D-1-8243-0049
Beschreibung Siedlung der Bronzezeit, Siedlung und Brandgräber der Urnenfelderzeit, Siedlung der Hallstattzeit und der späten Latènezeit sowie der römischen Kaiserzeit.
Verfahrensstand Benehmen hergestellt.
1.3. Modellierung von 1:n-Beziehungen im relationalen Datenformat
Zur Vermeidung von Redundanzen sollten Entitäten, die in einer Tabelle häufiger vertreten sind, in eine eigene Tabelle ausgegliedert werden. Die Zuordnung zwischen den dann zwei Tabellen wird üblicherweise mit einer identifizierenden Nummer vorgenommen.
Im obigen Beispiel würde es sich anbieten, die Entität der Gemeinden in einer eigenen Tabelle zu speichern, da auf einem Gemeindegebiet mehrere Fundstellen vorhanden sein können. Daraus resultieren zwei Tabellen, eine enthält die Informationen zu den Fundobjekten, die andere die zu den Gemeinden. Die Datensätze in der Tabelle Gemeinden erhalten wiederum einen Identifikator (ID).
Tabelle Fundobjekte
| ID | Bezeichnung | Kategorie | Gewicht | Material | ID_Fundort |
| 1 | Schwert | Waffe | 1.5 kg | Eisen | 1 |
| 2 | Helm | Verteidigungswaffe | 0.748 kg | Bronze | 2 |
| 3 | Münze | Zahlungsmittel | 4 g | Silber | 1 |
Tabelle Gemeinden
| ID | Fundort_ Gemeindegebiet |
Fundort_ Laengengrad |
Fundort_ Breitengrad |
| 1 | Grünwald | 11.345 | 47.876 |
| 2 | Weilheim | 11.3 | 47.234 |
Die Verbindung der auf die Tabellen verteilten Daten erfolgt schließlich mit einer Join-Operation.
In der Datenbanksprache SQL würde der entsprechende Befehl ("Statement") folgendermaßen lauten:
select * from Fundobjekte join Gemeinden on Fundobjekte.ID_Fundort = Gemeinden.ID ;
1.4. Modellierung von m:n-Beziehungen im relationalen Datenformat
Das Bayerische Landesamt für Denkmalpflege verwendet für die Verwaltung der Bodendenkmäler ein System von Aktennummern und Denkmalnummern. Die Aktennummern beziehen sich auf Einzelmaßnahmen wie z.B. Grabungen, Zufallsfunde oder auch Überfliegungen. Mehrere dieser mit den Aktennummern verbundenen Befunde können jedoch zu ein und demselben Bodendenkmal gehören, das durch eine eigene Denkmalnummer identifiziert wird. Gleichzeitig ist es möglich, dass bei einer Maßnahme Befunde erfasst werden, die zu unterschiedlichen Bodendenkmälern (etwa aus verschiedenen Epochen) gehören. Das bedeutet, dass eine Aktennummer einer beliebigen Anzahl (m) von Denkmalnummern zugeordnet sein kann. Umgekehrt kann eine Denkmalnummer sich auf eine beliebige Anzahl (n) von Aktennummern beziehen. Ein solches Verhältnis wird als m:n-Beziehung bezeichnet. Im relationalen Datenmodell muss eine m:n-Beziehung mit einer Zwischentabelle realisiert werden. Im folgenden Beispiel werden der Übersichtlichkeit halber fiktive Akten und Denkmalnummern verwendet. Aktennummern sind markiert durch das Praefix A-, Denkmalnummern durch das Praefix D-
Tabelle Aktennummern
| Aktennummer | Maßnahme |
| A-1 | Notgrabung |
| A-2 | Überfliegung |
| A-3 | Streufund |
| A-4 | Grabung des BLFD |
Tabelle Denkmalnummern
| Denkmalnummer | Beschreibung |
| D-1 | Viereckschanze |
| D-2 | Oppidum |
| D-3 | Opfergrube |
Verknüpfungstabelle
| Aktennummer | Denkmalnummer |
| A-1 | D-1 |
| A-3 | D-1 |
| A-3 | D-3 |
| A-4 | D-2 |
Durch Verknüpfung der drei Tabellen können die Daten zu einer Tabelle vereinigt werden:
2. Relationale Datenbanken
EisenzeitDigital (EZD) verwaltet die Daten in relationalem Format in einer relationalen Datenbank.
2.1. Warum eine Datenbank?
- Eine Datenbank erlaubt die Verwaltung und Analyse von strukturierten Daten
- Strukturierte Daten in einer Datenbank sind nicht gebunden an eine spezifische Anwendung
- Beispiel: Daten können in QGIS visualisiert werden, daneben aber auch in Web-GIS wie Open Streetmap oder Google Maps; Datenbank erlaubt auch arithmetische/statistische Analysen der Daten;
- Strukturierte Daten sind vorteilhaft im Hinblick auf Nachhaltigkeit (Voraussetzung: Umfangreiche Dokumentation, Ablage der Daten bei geeigneten Institutionen; Stichwort: Forschungsdatenmanagement)
- Daten können mit anderen Daten im selben Datenbanksystem kombiniert werden (Heuristik!)
2.2. Grundsätzliches zu relationalen Datenbanken
Relationale Datenbank = Sammlung von einer oder mehreren Tabellen (auch Excel- oder csv-Dateien)
- Tabelle="Relation"
- Zeilen = Datensätze, Tupel
- Spalten = Attribute, Eigenschaften
Die Definition von Zeilen und Spalten erfolgt durch sog. "Separatoren" (eindeutige Zeichen, die in den eigentlichen Daten nicht vorkommen dürfen oder entsprechend "maskiert" werden müssen): Beispiel: Zeilenumbruch (= x0a = \n) trennt Zeilen, Tabulator (= x09) trennt Spalten
/var/cache/html/dhlehre/html/wp content/uploads/2017/05/1494320005 Beispiel tabelle vim
Dieselbe Tabelle in ihrer "wahren" Gestalt:
$ od -t x1 beispiel_tabelle_vim.csv 6e 61 6d 6e 09 6c 6e 67 09 6c 61 74 0a 4d 61 6e 63 68 69 6e 67 09 31 31 2c 35 30 35 31 32 34 09 34 38 2c 37 32 30 33 38 35 38 0a
2.2.1. Datenbankmanagementsysteme (DBMS) für relationale Datenbanken:
- MySQL (online)
- Access (client)
- Filemaker (client)
- Postgres (online)
- Oracle Database
- DBase
- ... => https://de.wikipedia.org/wiki/Liste_der_Datenbankmanagementsysteme
DBMS erleichtern bzw. ermöglichen den Umgang mit relationalen Daten(banken)
2.2.2. Grundlegende Operationen über relational strukturierten Daten
- Selektion: Auswahl/Filterung von Zeilen/Datensätzen
- Projektion: Auswahl von Spalten/Attributen
- Join: Horizontale Verknüpfung von Tabellen
- Union: Vertikale Verknüpfung von Tabellen
Die Datenanalyse erfolgt nach den Regeln der relationalen Algebra in der Sprache SQL
2.3. Die Sprache SQL (Structered Query Language)
- Anfänge im Jahr 1975
- Angelehnt an das Englische
- Standardisiert bei der Internationalen Organisation für Normung (ISO; SQL=ISO/IEC 9075), liegt in mehreren "Dialekten" mit teils spezifischen Erweiterungen vor
- deklarativ (nicht prozedural)
- Gliederung in Teilbereiche:
- Data Manipulation Language (DML): Daten lesen, schreiben, ändern, löschen
- Data Definition Language (DDL): Datenstrukturen anlegen, ändern
- (Data Control Language [DCL]: Verwaltung von Zugriffsrechten)
- (Transaction Control Language [TCL]: Ausführen von Kommandos (commit, rollback))
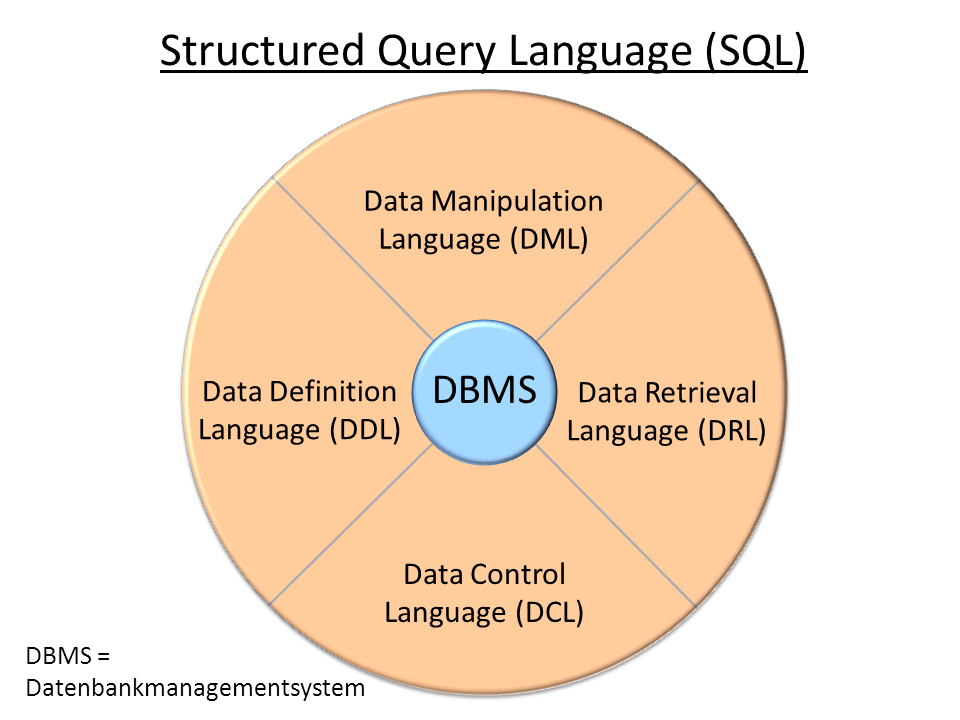
Gliederung der Structured Query Language - Quelle: Von Bagok - Eigenes Werk, CC BY-SA 3.0, https://commons.wikimedia.org/w/index.php?curid=17822175
2.3.1. Möglichkeiten des Zugriffs auf MySQL-Datenbanken:
- Web-Interfaces (z.B. phpMyAdmin [= PMA])
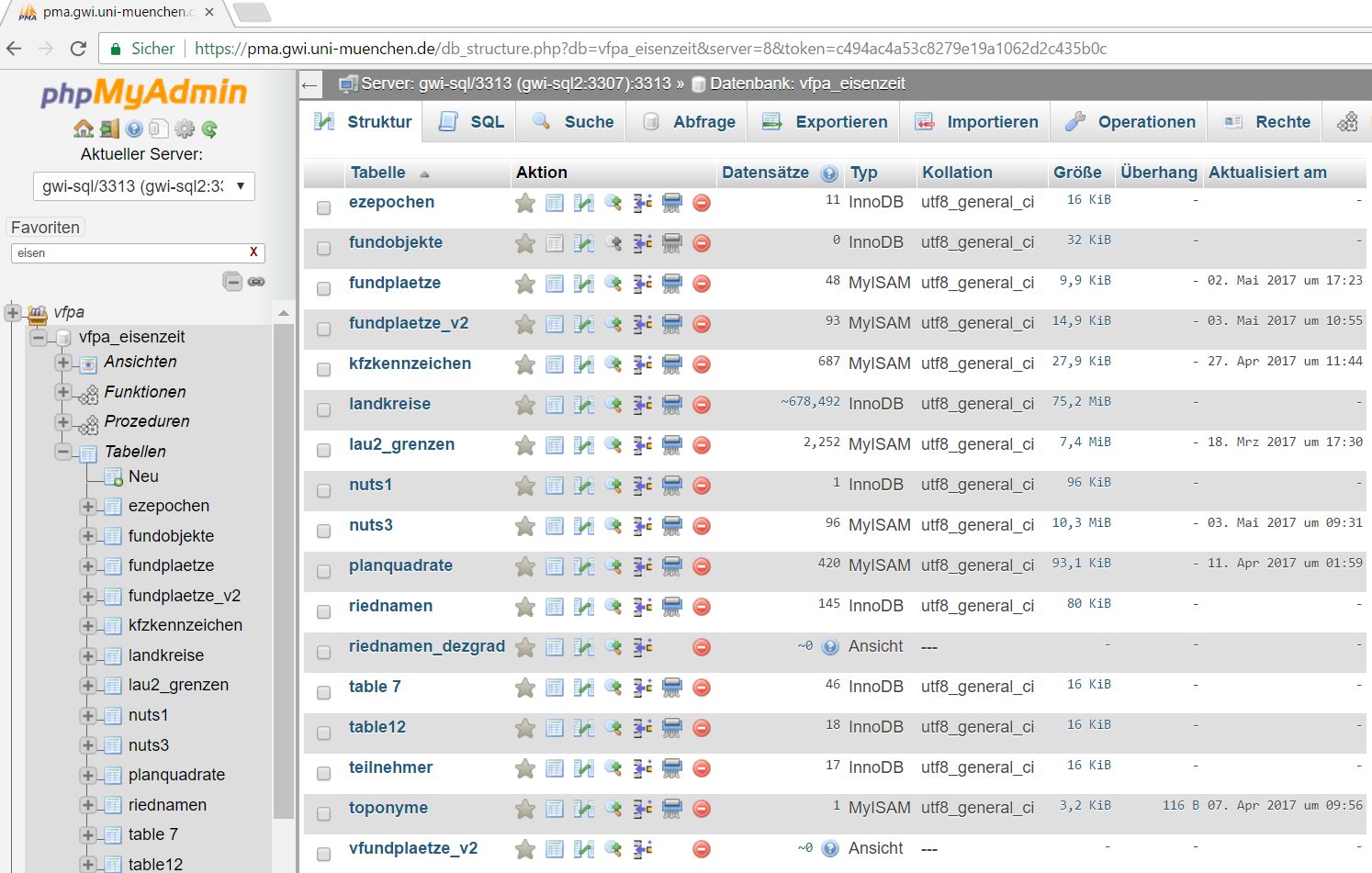
Ansicht der Datenbank vfpa_eisenzeit im generischen Web-Interface PhpMyAdmin (PMA)
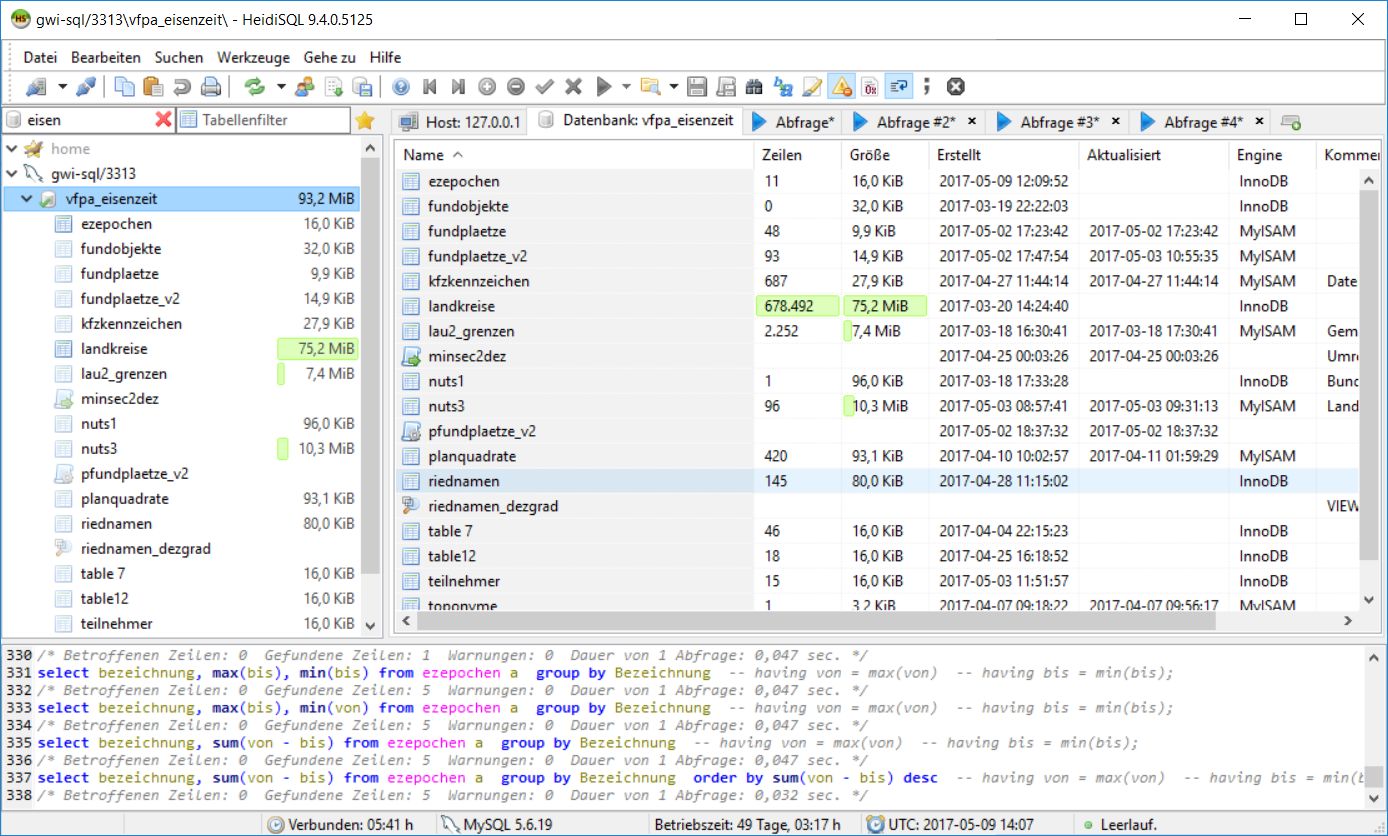
Die Datenbank vfpa_eisenzeit in Heidisql
- Kommandozeile (Win, Linux, Mac)
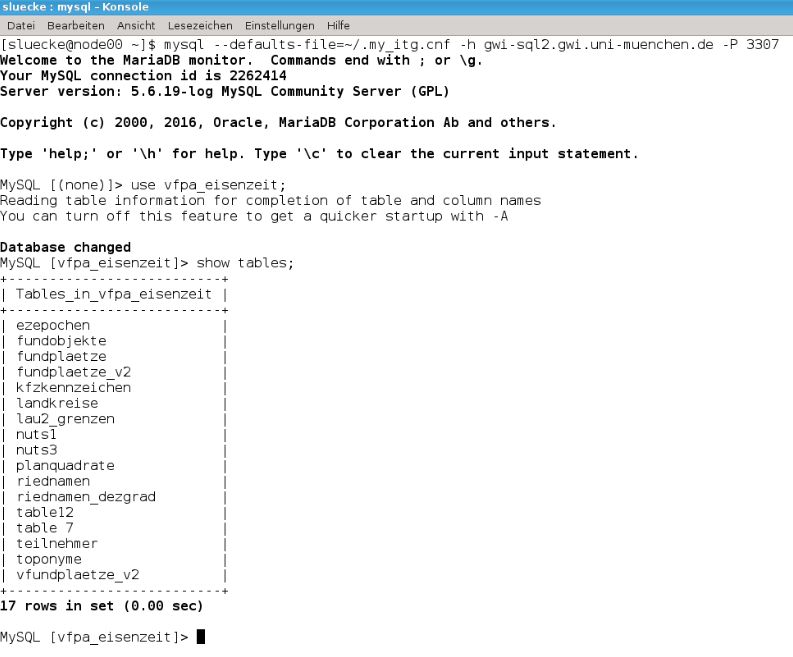
Die Tabellen einer älteren Version der Datenbank vfpa_eisenzeit in der Bash
2.4. Die EZD-Datenbank
- Adresse: https://pma.gwi.uni-muenchen.de:8888/db_structure.php?server=9&db=vfpa_eisenzeit;
- Benutzername: Eisenzeitdigital (Die Kennung hat ausschließlich Leserechte)
- Passwort: Manch1ng
Das Kommando zur Verbindung mit der Datenbank vfpa_eisenzeit von der Kommandozeile aus lautet:
mysql -u Eisenzeitdigital -pManch1ng -s -h gwi-sql.gwi.uni-muenchen.de -P 3315 -D vfpa_eisenzeit --execute "[sql-statement]" Beispiel mit sql-Statement (select * from v_daten_sose17_abgeschlossen;): mysql -u Eisenzeitdigital -pManch1ng -s -h gwi-sql.gwi.uni-muenchen.de -P 3315 -D vfpa_eisenzeit --execute "select * from v_daten_sose17_abgeschlossen;"
2.5. Einsatz der Datenbanksprache SQL (DML)
2.5.1. Die wichtigsten Kommandos der DML:
- select: wählt Datensätze aus
- update: verändert Datensätze
- insert: Fügt neue Datensätze ein
- delete: Löscht einzelne Datensätze
- truncate: Leert eine Tabelle
- drop: Löscht eine Tabelle
Beispiel:
-- Abfrage des Inhalts der Tabelle fisdaten18
select * from fisdaten18;
2.5.2. Grundsätzliches:
- Die Groß-/Kleinschreibung von Kommandos ist irrelevant.
- Tabellen- und Feldnamen können zwischen sog. Backticks ( ` - nicht zu verwechseln mit dem einfachen Anführungszeichen! S. dazu diesen Beitrag: Backticks, Hochkommata, Anführungszeichen … (ITG/slu)) geschrieben werden. Dies *muss* gemacht werden, wenn die Namen Leerzeichen enthalten oder für SQL missverständlich sind (z.B. `Alter` in einer Personentabelle)!
- Kommentare können durch --[Leerzeichen] (zwei Minuszeichen, gefolgt von einem Leerzeichen; bezieht sich jeweils nur auf eine Zeile) oder /* ... */ (mehrere Zeilen) kenntlich gemacht werden
- Zeilenumbrüche und Leerzeichen können beliebig in den Code eingesetzt werden (empfehlenswert wegen Übersichtlichkeit!)
- Ein SQL-Kommando wird Statement genannt
- Statements werden stets mit einem Semikolon (;) abgeschlossen
- Statements sind in funktionale Einheiten gegliedert, die man "Klauseln" nennt (z.B. select-Klausel, where-Klausel etc.). Die Reihenfolge der Nennung dieser Klauseln unterliegt einer Regel, die unbedingt einzuhalten ist. Andernfalls wird eine Fehlermeldung ausgegeben:
-- Kommentar: Klauseln und deren Reihenfolge: select [Feldliste] from [eine oder mehrere Tabellen] where [Filterkriterien] group by [Gruppierungsanweisung] having [Kriterien basierend auf den Rückgabewerten von Funktionen] order by [Sortierungsanweisung] limit [Begrenzung der Anzahl der auszugebenden Datensätze]
Beispiel:
select teil1, group_concat(concat(sigle, ' ', teil1, teil2)) as Epochen from ezepochen where Bezeichnung like '%Hallstattzeit%' group by teil1 having count(*) > 1 order by bis asc limit 1 ;
2.5.3. Einfache Selektionen
Ein Tipp vorab: Legen Sie sich eine Textdatei an, in der Sie komplexe SQL-Statements speichern. Verwenden Sie dazu einen Editor wie Gvim oder Notepad++ (nicht Word oder den Windows-eigenen Editor!). Geben sie dem Dateinamen die Extension ".sql" (z.B. abfragen.sql). Dies bewirkt in den meisten Editoren eine farbliche Paraphrasierung der Syntaxstrukturen des SQL-Codes (sog. Syntax Highlighting). Alternativ oder zusätzlich können SQL-Statements auch in einer eigenen Datenbank-Tabelle abgelegt werden (z.B. queries). Diese sollte auch Spalten enthalten, die die einzelnen Statements erläutern.
- Die Auswahl von Zeilen einer Tabelle nennt man Selektion
- Die Selektion erfolgt durch die Verwendung einer where-Klausel mit Bedingungen.
2.5.3.1. Vergleichsoperatoren in der where-Klausel:
- = (identisch)
- != (ungleich, nicht identisch)
- like (Trunkierung mit Wildcards % [beliebige Anzahl beliebiger Zeichen] und _ [genau ein beliebiges Zeichen])
- not like (ungleich)
- > (größer als; bei Zahlen)
- < (kleiner als; bei Zahlen)
- between [zahl] and [zahl] (jeweils inklusive)
- in ('string1', 'string2', zahl, ...) (Werteliste)
- is null (Prüfung auf sog. NULL-Wert in einem Feld)
- rlike (Suche nach regulären Ausdrücken)
- ... [weitere]
2.5.3.2. Beispiele
- In PMA können über den Reiter "SQL" beliebige Statements in der Datenbank ausgeführt werden:
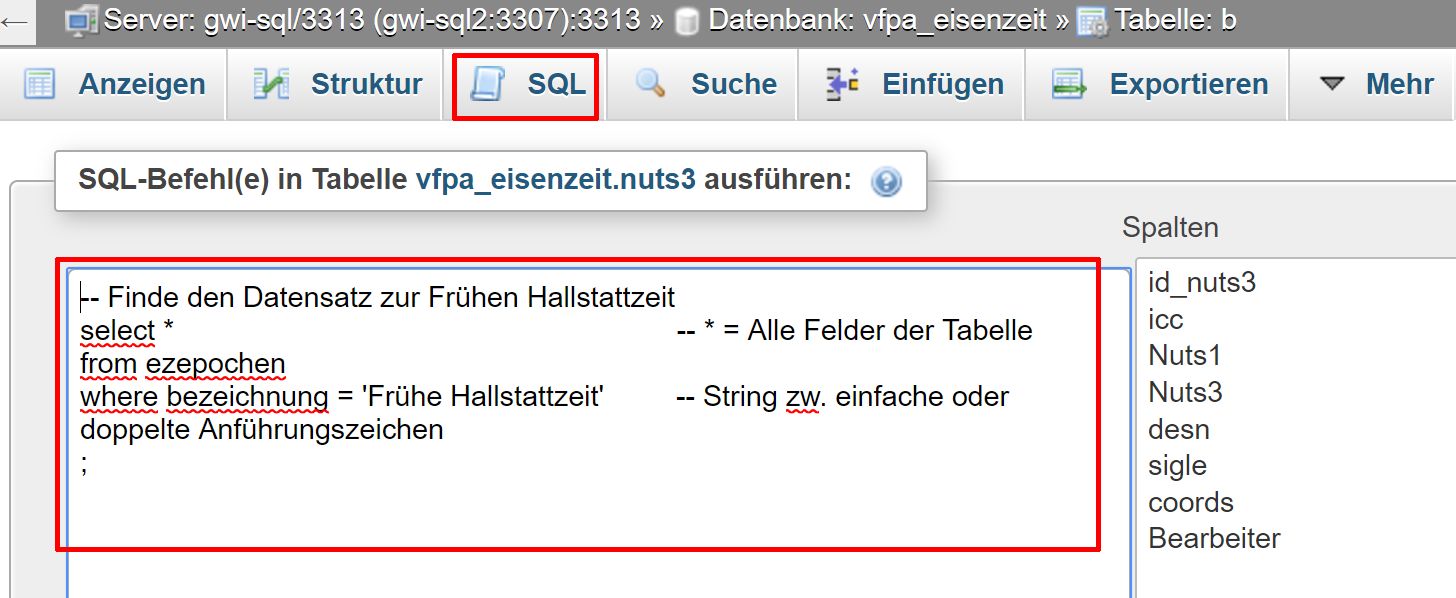
/var/cache/html/dhlehre/html/wp content/uploads/2017/05/1497987272 Pma sql fenster
- Vorgefertigte Statements können mittels copy/paste in das Abfragefenster eingefügt und durch Klick auf "OK" ausgeführt werden.
-- Finde den Datensatz zur Frühen Hallstattzeit select * -- * = Alle Felder der Tabelle from ezepochen where bezeichnung = 'Frühe Hallstattzeit' -- String zw. einfache oder doppelte Anführungszeichen ;
-- Finde alle Datensätze zur Späten Hallstattzeit select * from ezepochen where bezeichnung = 'Späte Hallstattzeit' ;
-- Finde alle Datensätze zur Latènezeit select * from ezepochen where bezeichnung like '%Latènezeit%' -- "Wildcard": % -> Trunkierung ;
- Suchkriterien können mit Hilfe der Operatoren "and" und "or" miteinander kombiniert werden
- "and" und "or" folgen den Regeln der Boolschen Algebra (https://de.wikipedia.org/wiki/Boolesche_Algebra) und bilden "Boolsche Ausdrücke". Konkret bedeutet das z.B., dass der Operator "or" verwendet werden muss, wenn man alle Datensätze erhalten möchte, die im Feld `Bezeichnung` den Wert "Latènezeit" besitzen, *und* alle Datensätze, die im Feld `Bezeichnung` den Wert "Hallstattzeit" aufweisen:
-- Finde alle Datensätze, die der Latènezeit oder der Hallstattzeit zugeordnet sind select * from ezepochen where bezeichnung like '%Latènezeit%' or bezeichnung like '%Hallstattzeit%' ;
Die Verwendung von "and" in diesem Beispiel würde bedeuten, dass der Wert in dem Feld *beide* Bedingungen zugleich erfüllen müsste: Es müsste "Hallstattzeit" *und* "Latènezeit" enthalten.
- Die Negation von Filterkriterien erfolgt, je nach verwendetem Operator, durch den Zusatz "not" oder "!":
/* Finde alle Datensätze, die nicht der Latènezeit und gleichzeitig der Subperiode 3 zugeordnet sind */ select * from ezepochen where bezeichnung not like '%Latènezeit%' and teil2 != 3 ;
2.5.4. Kollationen
Für jede Textspalte einer MySQL-Tabelle wird automatisch eine Kollation festgelegt. Für Unicode-kodierte Texte sind die Kollationen utf8_general_ci und utf8_unicode_ci weit verbreitet. Diese Kollation wirkt sich auf Sortierungs- und Suchvorgänge aus. Es existiert eine Reihe von Kollationen, die länderspezifische Sortierungsregeln implementieren (z.B. utf8_danish_ci, utf8_estonian_ci, ...). "ci" steht dabei jeweils für "case insensitive", d.h. Groß-/Kleinschreibung bleibt unberücksichtigt. So findet z.B. die Suche nach "weg" u.a. "Weg" und "weg".
Bestehende Kollationen können Stringsuchen
2.5.5. Projektionen: Auswahl, Wiederholung und Änderung der Reihenfolge von Spalten
- Bei einer Selektion können einzelne Spalten/Felder ausgewählt werden
- Die Spalten einer Tabelle können beliebig oft wiederholt werden
- Die Reihenfolge von Spalten kann geändert werden
- Die Spalten können unter einem anderen Namen ausgegeben werden (sog. Korrelatsnamen)
- Es können auch einfache Zeichenketten als zusätzliche Spalten ausgegeben werden
- Die Liste der Feldnamen ist kommagetrennt, hinter dem letzten Feldnamen vor der from-Klausel darf kein Komma stehen
2.5.5.1. Beispiele:
/* Zeig nur bestimmte Felder des Abfrageergebnisses "Finde alle Datensätze, in denen der String 'hallstatt' vorkommt" */ select zeit, -- Beginn Feldliste koid, gde as Gemeinde, Landkreis, Kurzbeschreibung -- Ende Feldliste from fisdaten18 where kurzbeschreibung like '%hallstatt%' ;
-- Zeig Beginn und Ende von HA D3 select Bezeichnung, von, bis -- Projektion: Auswahl einzelner Felder; hinter dem letzten KEIN KOMMA from ezepochen where sigle like 'HA' and teil1 like 'D' -- Kombination mehrerer Kriterien mit and und or and teil2 like '3' ;
-- Einbettung der Daten in Text select 'Die' as text1, -- Das "as" legt den Kolumnentitel fest (= sog. Korrelatsname) Bezeichnung, -- Korrelatsnamen können auch für Tabellen vergeben werden '(' as text2, sigle, teil1, teil2, ') dauerte von' as text3, von, 'bis' as text4, bis, ' - ' as text5, sigle, teil1, teil2 from ezepochen as `Epochen der Eisenzeit` -- Korrelatsname für Tabelle `ezepochen` ;
2.5.6. Gruppierungen
Daten können gruppiert werden. Zu diesem Zweck müssen ein oder mehrere Felder angegeben werden, nach deren Werten gruppiert werden soll. Sämtliche Datensätze/Zeilen, die in dem oder den Feld(ern) identische Werte bzw. Wertkombinationen aufweisen, werden zu einer Gruppe zusammengefasst. In der Ergebnistabelle wird dann jeweils nur der erste Vertreter einer Gruppe dargestellt. Man kann es sich so vorstellen, dass all die anderen Mitglieder der Gruppe gleichsam "hinter" dem ersten Vertreter stehen.
Mit Hilfe von Gruppierungen lässt sich gut rechnen. So können z.B. die Anzahl von Mitgliedern einer Gruppe (Funktion [zu Funktionen s.u.] count(*)), Maximal- (max()), Minimal- (min()) und Durchschnittswerte (avg()) festgestellt werden.
Die Gruppierung erfolgt in SQL über das Statement "group by".
Beispiele:
-- Ermittle die Anzahl von Teilepochen pro Bezeichnung select Bezeichnung, count(*) as `Anzahl Teilepochen` -- Die Funktion count(*) ermittelt die Anzahl from ezepochen -- der Gruppenmitglieder group by Bezeichnung ;
-- Ermittle die Anzahl von Hauptstrukturen select count(*) as Anzahl, hauptstruktur from bf_fundplaetze a group by hauptstruktur order by count(*) desc ;
-- Anzahl eisenzeitliche Fundplätze pro Landkreis select landkreis, count(*) as `Anzahl eisenzeitliche Fundplätze` from fisdaten18 group by landkreis ; -- Die Tabelle `fisdaten18` enthält ausschließlich Fundplätze aus der Eisenzeit. Eine -- Filterung nach "Eisenzeit" ist daher nicht nötig
Übung: Ermitteln Sie die Anzahl von Fundplätzen im Landkreis Deggendorf!
2.5.7. Einsatz von Funktionen
(My)SQL verfügt über eine ganze Reihe von Funktionen
-- Beispiel select gde, ' (', landkreis, '; ', kurzbeschreibung, ')', concat(gde,' (',landkreis,'; ', kurzbeschreibung,')') from fisdaten18 ;
- Unterscheidung zwischen verschiedenen Arten (z.B. Stringfunktion, numerische Funktionen, geometrischen Funktionen ["spatial analysis"], Gruppierungsfunktionen, Datum- und Zeitfunktionen etc.)
- Eine Funktion ist eine Art "Automat", dem man Daten übergeben kann und der diese verarbeitet und ein Ergebnis erzeugt (sog. "Rückgabewert")
- Funktionen haben stets den gleichen Aufbau: Sie bestehen aus einem Namen und einem Paar runder Klammern, zwischen die die sog. "Argumente" oder auch "Parameter" (= die Daten, die der Funktion übergeben werden) geschrieben werden müssen. Zwischen dem Namen der Funktion und der öffnenden Klammer darf *kein* Leerzeichen stehen.
- Jede Funktion hat eine klar definierte Art und Anzahl von Argumenten, die der Funktion übergeben werden müssen. Bei Nichteinhaltung erfolgt eine Fehlermeldung.
- Funktionen können in fast allen "Klauseln" eines SQL-Statements verwendet werden (also in der Feld-Liste, der where-Klausel, der group-by-Klausel etc.)
- Funktionen können "geschachtelt" werden, d.h. der Rückgabewert einer Funktion kann als Parameter an eine weitere Funktion übergeben werden.
- Vollständige Listen der MySQL-Funktionen finden sich auf der Dokumentationsseite von MySQL:
- String-Funktionen: https://dev.mysql.com/doc/refman/5.7/en/string-functions.html
- mathematische/numerische Funktionen: https://dev.mysql.com/doc/refman/5.7/en/numeric-functions.html
- Spatial-analysis-Funktionen: https://dev.mysql.com/doc/refman/5.7/en/spatial-function-reference.html
- Gruppierungsfunktionen: https://dev.mysql.com/doc/refman/5.7/en/group-by-functions.html
- Datum- und Zeitfunktionen: https://dev.mysql.com/doc/refman/5.7/en/date-and-time-functions.html
ACHTUNG: Nicht alle MySQL-Funktionen funktionieren in allen MySQL-Versionen. Gerade die Spatial-Analysis-Funktionen sind relativ jung und können unter Umständen auf älteren MySQL-Versionen nicht laufen (Auf https://pma.gwi.uni-muenchen.de ist derzeit [Mai 2017] MySQL 5.6.19 installiert).
Einige häufiger gebrauchte Funktionen:
- concat(): Konkateniert Zeichenketten
- concat_ws(): Konkateniert Zeichenketten und schreibt zwischen die Glieder einen Separator ("ws"= with separator)
- count(): Zählt die Mitglieder einer Gruppe
- group_concat(): Konkateniert die Mitglieder einer Gruppe
- substring();
- substring_index(): Zerlegt Strings gemäß einem frei wählbaren Separator in Einzeilteile
- st_within(): Prüft, ob ein geometrisches Objekt innerhalb eines anderen liegt
- round(): Rundet Zahlen kaufmännisch
- replace(): Nimmt Ersetzungen in Strings vor
2.5.7.1. Beispiele:
-- Funktion concat(); select 'Eisenzeit', 'Digital', concat('Eisenzeit', 'Digital');
-- Einbettung von Daten in Text select concat( 'Die ', Bezeichnung, ' (', sigle, teil1, teil2, ') dauerte von ', von, ' bis ', bis, ' - ', sigle, teil1, teil2 ) as Text from ezepochen ;
/* Erzeuge eine Liste sämtlicher Epochenkürzel, chronologisch absteigend geordnet Gruppierungsfunktion ohne group-by-Klausel gruppiert alle Datensätze einer Tabelle */ select group_concat(sigle, ' ', teil1, teil2 order by von asc separator '; ') from ezepochen ;
/* Schachtelung von Funktionsaufrufen. Eine beliebige Anzahl beliebiger Funktionen kann "geschachtelt" werden. Das bedeutet, dass das "Ergebnis" (eigtl. "Rückgabewert") einer Funktion einer weiteren Funktion als "Argument" übergeben werden kann. */ -- Beispiel 1: Die Funktion stellt einen String invertiert dar. -- Zweifache Anwendung von reverse() stellt den String wieder "normal" dar": select 'Latène', reverse('Latène'), reverse(reverse('Latène')); -- Beispiel 2: Schachtelung von mehr als zwei Funktionen -- concat(): konkateniert Strings; upper() verwandelt sie in Versalien; -- char_length ermittelt die Anzahl von Zeichen eines Strings select a.gde,' (',a.landkreis,')', concat(a.gde,' (',a.landkreis,')'), upper(concat(a.gde,' (',a.landkreis,')')), char_length(upper(concat(a.gde,' (',a.landkreis,')'))) from fisdaten18 a ; -- Beispiel 3: Mehrfache Verwendung der replace()-Funktion (Ersetzung): select 'aber' as `los geht's`, replace('aber','a','o') step1, replace(replace('aber','a','o'),'b','d') step2, replace(replace(replace('aber','a','o'),'b','d'),'o','O') step3 ; -- Zur besseren Lesbarkeit dieselbe Abfrage anders strukturiert: select 'aber' as `los geht's`, replace( 'aber','a','o' ) step1, replace( replace('aber','a','o'), 'b','d' ) step2, replace( replace( replace( 'aber','a','o' ), 'b','d' ), 'o','O') step3 ;
[
2.5.7.2. Selbst definierte Funktionen
Funktionen können auch selbst definiert werden. Das folgende Beispiel zeigt eine selbst erzeugte Funktion, die eine geographische Positionsangabe in Grad, Minuten und Sekunden in eine Dezimaldarstellung umrechnet. Dafür gilt grundsätzlich folgender Algorithmus:
- Sekunden durch 60 dividieren,
- Minuten hinzuaddieren,
- Ergebnis durch 60 dividieren,
- Grad hinzuaddieren
Die Definition einer entsprechenden MySQL-Funktion sieht dann so aus (die eigentliche Rechnvorschrift ist rot gesetzt):
show create function minsec2dez;
-- Ergebnis:
CREATE DEFINER=`u1`@`141.84.155.0/255.255.255.0` FUNCTION `minsec2dez`(
`degminsec` VARCHAR(50)
) RETURNS decimal(17,14)
DETERMINISTIC
COMMENT 'Umrechnung Geodaten im Minuten/Sekunden-Format in Dezimalgrad'
BEGIN
return
(substring_index(degminsec,' ',-1)/60
+ substring_index(substring_index(degminsec,' ',2),' ',-1)) / 60
+ substring_index(degminsec,' ',1)
;
END
Aufruf der Funktion:
select minsec2dez('48 05 16');
-- Ergebnis: 48.08777777777778
]
2.5.8. Verknüpfung von Tabellen (Joins)
Datenbanktabellen können dergestalt miteinander verknüpft werden, dass jede Zeile der einen mit jeder Zeile der anderen Tabelle kombiniert werden (sog. Kartesisches Produkt).
{kind=link}
Gegeben seien zwei Tabellen mit Namen X und Y. Das Kartesische Produkt wird folgendermaßen erzeugt:
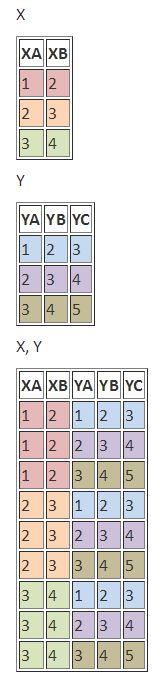
/var/cache/html/dhlehre/html/wp content/uploads/2017/05/1497433731 Kreuzprodukt; Quelle: https://wiki.selfhtml.org/wiki/Datenbank/Einf%C3%BChrung_in_Joins
In SQL wird der entsprechende Join mit folgender Syntax erzeugt:
select * from X join Y;
Sofern für die Verknüpfung der beiden Tabellen eine Bedingung gestellt wird, spricht man von einem "Equi Join". Im folgenden Beispiel wird als Bedingung vorgegeben, dass die Werte in den Spalten XA und YA sowie in XB und YB identisch sein sollen. Das Ergebnis sieht dann wie folgt aus:
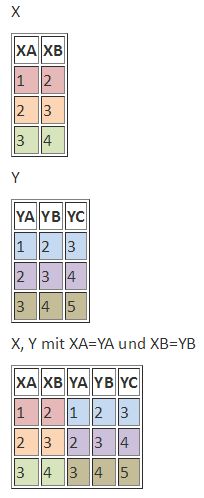
/var/cache/html/dhlehre/html/wp content/uploads/2017/05/1497434221 EquiJoin; Quelle: https://wiki.selfhtml.org/wiki/Datenbank/Einf%C3%BChrung_in_Joins
In SQL-Syntax wird der Equi-Join so erzeugt:
select * from X join Y on X.XA=Y.YA and X.XB=Y.YB;
Beispiel aus der Datenbank vfpa_eisenzeit:
Join der Tabellen `demo_join` und `ezepochen`.
Die Tabelle demo_join enthält eine einzige Spalte mit nur zwei Zeilen:
select * from demo_join; -- Ergebnis: HA BR
ezepochen besteht aus 6 Spalten und 11 Zeilen:
select * from ezepochen; -- Ergebnis: Frühe Hallstattzeit | 800 | 620 | HA | C | Späte Hallstattzeit | 620 | 530 | HA | D | 1 Späte Hallstattzeit | 530 | 510 | HA | D | 2 Späte Hallstattzeit | 510 | 450 | HA | D | 3 Frühlatènezeit | 450 | 380 | LT | A | Frühlatènezeit | 380 | 320 | LT | B | 1 Frühlatènezeit | 320 | 250 | LT | B | 2 Mittellatènezeit | 250 | 200 | LT | C | 1 Mittellatènezeit | 200 | 150 | LT | C | 2 Spätlatènezeit | 150 | 60 | LT | D | 1 Spätlatènezeit | 60 | 15 | LT | D | 2
Der "bedingungslose" Join der beiden Tabellen (= kartesisches Produkt) kombiniert jede Zeile der linken Tabelle (= demo_join) mit jeder Zeile der rechten Tabelle (= ezepochen). Da die Tabelle demo_join 3 und die Tabelle ezepochen 11 Zeilen hat, entstehen insgesamt 2 * 11 = 22 Zeilen sowie 7 Spalten (1 + 6):
-- select * from demo_join join ezepochen ; -- Ergebnis (der Fettsatz markiert Zeilen, in denen der Wert in der -- ersten und in der fünften Spalte übereinstimmen): HA | Frühe Hallstattzeit | 800 | 620 | HA | C | BR | Frühe Hallstattzeit | 800 | 620 | HA | C | HA | Späte Hallstattzeit | 620 | 530 | HA | D | 1 BR | Späte Hallstattzeit | 620 | 530 | HA | D | 1 HA | Späte Hallstattzeit | 530 | 510 | HA | D | 2 BR | Späte Hallstattzeit | 530 | 510 | HA | D | 2 HA | Späte Hallstattzeit | 510 | 450 | HA | D | 3 BR | Späte Hallstattzeit | 510 | 450 | HA | D | 3 HA | Frühlatènezeit | 450 | 380 | LT | A | BR | Frühlatènezeit | 450 | 380 | LT | A | HA | Frühlatènezeit | 380 | 320 | LT | B | 1 BR | Frühlatènezeit | 380 | 320 | LT | B | 1 HA | Frühlatènezeit | 320 | 250 | LT | B | 2 BR | Frühlatènezeit | 320 | 250 | LT | B | 2 HA | Mittellatènezeit | 250 | 200 | LT | C | 1 BR | Mittellatènezeit | 250 | 200 | LT | C | 1 HA | Mittellatènezeit | 200 | 150 | LT | C | 2 BR | Mittellatènezeit | 200 | 150 | LT | C | 2 HA | Spätlatènezeit | 150 | 60 | LT | D | 1 BR | Spätlatènezeit | 150 | 60 | LT | D | 1 HA | Spätlatènezeit | 60 | 15 | LT | D | 2 BR | Spätlatènezeit | 60 | 15 | LT | D | 2
Ein inner join entsteht, wenn für die Verknüpfung der beiden Tabellen eine Bedingung formuliert wird:
select * from demo_join join ezepochen on demo_join.sigle = ezepochen.sigle ; -- Das Ergebnis enthält nur Zeilen, in denen die Bedingung erfüllt ist -- (entspricht den fett gesetzten Zeilen im Beispiel davor): HA | Frühe Hallstattzeit | 800 | 620 | HA | C | HA | Späte Hallstattzeit | 620 | 530 | HA | D | 1 HA | Späte Hallstattzeit | 530 | 510 | HA | D | 2 HA | Späte Hallstattzeit | 510 | 450 | HA | D | 3
Das Ergebnis des inner join eliminiert Zeilen der linken Tabelle, deren Wert im Bedingungsfeld keine Entsprechung in der rechten Tabelle haben. Daher fehlt im Ergbnis die Zeile mit dem Wert 'BR' in der linken Tabelle. Um auch solche Zeilen anzuzeigen, muss ein left outer join verwendet werden:
select * from demo_join left join ezepochen on demo_join.sigle = ezepochen.sigle ; -- Ergebnis (die Zeile mit dem Wert, der in der linken Tabelle keine Entsprechung -- aufweist, enthält in den Spalten aus der rechten Tabelle sog. NULL-Werte): HA | Frühe Hallstattzeit | 800 | 620 | HA | C | HA | Späte Hallstattzeit | 620 | 530 | HA | D | 1 HA | Späte Hallstattzeit | 530 | 510 | HA | D | 2 HA | Späte Hallstattzeit | 510 | 450 | HA | D | 3 BR | NULL | NULL | NULL | NULL | NULL | NULL
Der Wert 'LT' im Feld Sigle in der rechten Tabelle hat keine Entsprechung im Feld sigle der linken Tabelle. Um auch diese Datensätze anzeigen zu lassen, muss ein right outer join verwendet werden:
-- right outer join select * from demo_join right join ezepochen on demo_join.sigle = ezepochen.sigle ; -- Ergebnis (diesmal finden sich die NULL-Werte in der Spalte der linken Tabelle): HA | Frühe Hallstattzeit | 800 | 620 | HA | C | HA | Späte Hallstattzeit | 620 | 530 | HA | D | 1 HA | Späte Hallstattzeit | 530 | 510 | HA | D | 2 HA | Späte Hallstattzeit | 510 | 450 | HA | D | 3 NULL | Frühlatènezeit | 450 | 380 | LT | A | NULL | Frühlatènezeit | 380 | 320 | LT | B | 1 NULL | Frühlatènezeit | 320 | 250 | LT | B | 2 NULL | Mittellatènezeit | 250 | 200 | LT | C | 1 NULL | Mittellatènezeit | 200 | 150 | LT | C | 2 NULL | Spätlatènezeit | 150 | 60 | LT | D | 1 NULL | Spätlatènezeit | 60 | 15 | LT | D | 2
2.5.9. Weiteres Beispiel (Join der Tabellen bf_fundplaetze und bf_perioden)
Die Tabelle bf_fundplaetze enthält Daten zu den Fundplätzen in Bayern. Zwischen diesen Daten und denen der Tabelle bf_perioden besteht der folgende logische Bezug: Die Daten im Feld bf_fundplaetze.periode beziehen sich auf die Daten im Feld bf_perioden.id_perioden. Möchte man nun einen Bezug zwischen den Hauptstrukturen der Fundplätze (bf_fundplaetze.hauptstruktur) und den in Jahreszahlen angegebenen Periodengrenzen in der Tabelle bf_perioden herstellen, so müssen die beiden Tabellen in folgender Weise miteinander "gejoint" werden:
-- strict join der Tabellen bf_fundplaetze und bf_perioden select * from bf_fundplaetze a -- a = Korrelatsname der Tabelle bf_fundplaetze join bf_perioden b -- b = Korrelatsname der Tabelle bf_perioden on a.periode=b.id_perioden ;
Das vorgeführten Beispiel liefert nur solche Datensätze aus der Tabelle bf_fundplätze, die im Feld periode einen entsprechenden Wert im Feld id_perioden der Tabelle bf_perioden aufweisen. Ein solcher Join wird "inner join" (auch: strict join) genannt.
Bei Joins empfiehlt es sich, immer Korrelatsnamen für die Tabellen zu verwenden, um den Schreibaufwand zu reduzieren. Ohne Korrelatsnamen müsste die Join-Bedingung lauten:
... on bf_fundplaetze.periode = bf_perioden.id_perioden
Möchte man sämtliche Datensätze der Tabelle bf_fundplätze geliefert bekommen, unabhängig davon, ob Entsprechungen in der anderen Tabelle vorliegen, so muss man einen sog. "outer join" durchführen. Dies erfolgt im vorliegenden Beispiel durch den Zusatz "left" vor dem Schlüsselwort "join". "Left" bezieht sich dabei auf die Reihenfolge, in der die Tabellen im Statement genannt werden. Diese Reihenfolge bestimmt auch die Reihenfolge der Kolumnen im Abfrageergebnis: Die Kolumnen der im Statement erstgenannten Tabelle erscheinen links von denen der danach genannten Tabelle:
-- left outer join der Tabellen bf_fundplaetze und bf_perioden select * from bf_fundplaetze a left join bf_perioden b on a.periode=b.id_perioden ;
Analog zum gezeigten Left-outer-Join gibt es auch den right-outer-Join, der sämtliche Datensätze der *rechten* Tabelle zeigt, auch wenn es für sie keine Werteentsprechungen in der linken Tabelle gibt:
-- right outer join der Tabellen bf_fundplaetze und bf_perioden select * from bf_fundplaetze a right join bf_perioden b on a.periode=b.id_perioden ;
Die Datensätze, die *keine* Werteentsprechungen in der jeweils anderen Tabelle besitzen, weisen in der Ergebnistabelle in den Spalten der Tabelle mit den fehlenden Entsprechungen sog. NULL-Werte auf. Möchte man gerade die Datensätze ohne Werteentsprechungen auffinden, kann nach eben diesen NULL-Werten filtern. Zu diesem Zweck muss der Vergleichsoperator "is" verwendet werden:
-- Filterung nach NULL-Werten select * from bf_fundplaetze a right join bf_perioden b on a.periode=b.id_perioden where a.periode is null ;
Gerade bei Joins kommt es vor, dass die Ergebnistabelle durch eine große Anzahl von Spalten sehr unübersichtlich ist. Für bessere Übersichtlichkeit bietet es sich an, mit Hilfe einer Projektion nur ausgewählte, relevante Spalten ausgeben zu lassen. Da nicht ausgeschlossen werden kann, dass die beiden verknüpften Tabellen Spalten mit identischen Namen besitzen, kann/muss dabei der Name der jeweiligen Tabelle mit angegeben werden:
-- Auswahl einzelner Spalten (Projektion) select a.periode, b.id_perioden, b.von, b.bis from bf_fundplaetze a right join bf_perioden b on a.periode=b.id_perioden where a.periode is null ;
Es können auch Tabellen "gejoint" werden, die sich in unterschiedlichen Datenbanken auf einem MySQL-Server befinden. Die Syntax zur Adressierung erweitert dabei das bereits vorgestellte Schema "[NameTabelle].[NameFeld]" nach links um den Namen der Datenbank:
[NameDatenbank].[NameTabelle].[NameFeld]
Hierzu ein Beispiel. Die Daten der Tabellen `fisdaten18_1` in der Datenbank `vfpa_eisenzeit` und `commune` in der Datenbank `archeolocalis` sind über das in beiden Tabellen vorhandene Feld `codeCommune` logisch aufeinander bezogen. Ein sinnvoller Join dieser beiden Tabellen könnte z.B. so aussehen:
-- rot = Datenbank | blau = Tabelle | grün = Feld select vfpa_eisenzeit.fisdaten18_1.aktennummer, archeolocalis.commune.nomCommune, vfpa_eisenzeit.fisdaten18_1.landkreis, archeolocalis.commune.wkb from vfpa_eisenzeit.fisdaten18_1 join archeolocalis.commune on vfpa_eisenzeit.fisdaten18_1.codeCommune = archeolocalis.commune.codeCommune ; -- Anstelle der umständlichen on-Klausel am Ende wäre hier, da die Felder -- in beiden Tabellen den selben Namen haben, auch die Verwendung -- der using()-Funktion möglich: ... using(codeCommune)
Übung: Erzeugen Sie einen *sinnvollen* Join der beiden Tabellen bf_fundplaetze und bf_orte!
Ein komplexeres Beispiel: Ermittle alle Orte aus der Tabelle bf_orte, die innerhalb des Perimeters des Landkreises Altötting liegen. Zu diesem Zweck wird in der on-Klausel festgelegt, dass der Wert der Koordinaten des Gemeindemittelpunkts (Feld: bf_orte.center) innerhalb des Polygons des Landkreises Altötting liegen muss. Da die Daten zu den Grenzen der Landkreise in einer eigenen Tabelle gespeichert sind (nuts3 => "Nomenclature des unités territoriales statistiques" => https://de.wikipedia.org/wiki/NUTS), müssen die beiden Tabellen "gejoint" werden. Da die Geokoordinaten in der Tabelle bf_orte im WKT-Format gespeichert sind, müssen vor dem Join mit Hilfe der Funktion geomfromtext() noch in das WKB-Format umgewandelt werden:
select
*
from bf_orte a
join nuts3 b
on st_within(geomfromtext(a.center),b.coords)
where b.nuts3 like 'Altötting'
;
ACHTUNG: Joins sind unter Umständen sehr rechenintensiv, und die entsprechenden Abfragen dauern teilweise sehr lange. Um Joins zu beschleunigen, kann man die Felder, über die "gejoint" wird, mit einem Index belegen (in etwa vergleichbar mit dem Index in einem gedruckten Buch):
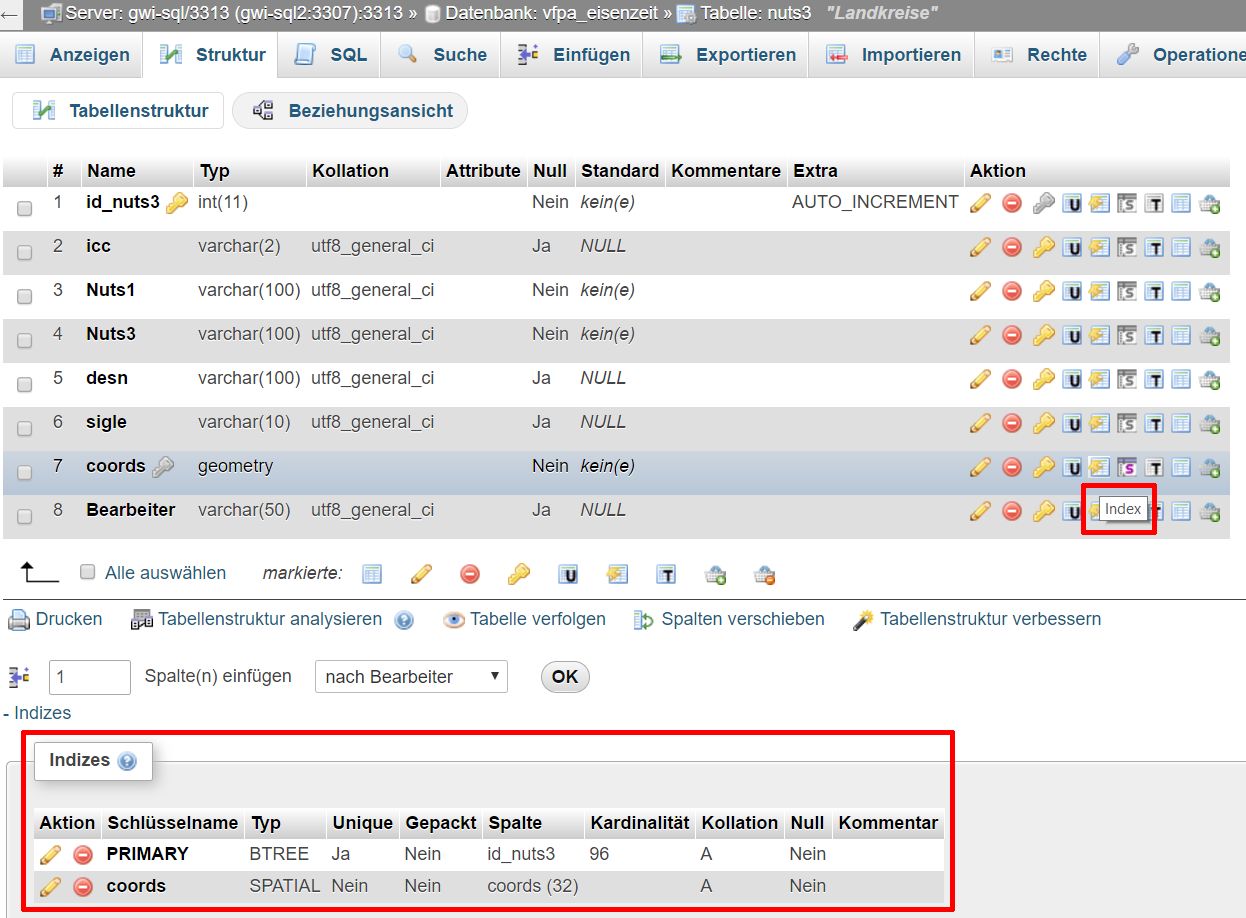
/var/cache/html/dhlehre/html/wp content/uploads/2017/05/1497963308 Mysql indices
2.5.10. Unterabfragen (Subqueries)
Jedes select-Statement erzeugt als Ergebnis wiederum eine Tabelle. Diese kann als sog. Unterabfrage (engl. subquerie) erneut mit einem select-Statement abgefragt werden. Die Unterabfrage wird durch Klammerung definiert und muss einen Korrelatsnamen erhalten. Dies erfolgt durch das Wort "as" und einen nachfolgenden, im Prinzip frei wählbaren, Namen.
Einfachstes Beispiel:
select * from (select * from ezepochen) sq -- Unterabfrage; sq ist der frei wählbare Korrelatsname ;
Unterabfragen können z.B. nützlich sein, wenn es darum geht, Join-Abfragen zu beschleunigen. Das o.a. im Zusammenhang mit den Joins genannte Beispiel, in dem es darum geht zu ermitteln, welche Gemeinden innerhalb des Landkreises Altötting liegt, kann dadurch beschleunigt werden, dass man zunächst aus der Tabelle nuts3 nur das Polygon des Landkreises Altötting herausfiltert und das Ergebnis dieser Abfrage dann mit der Tabelle bf_orte joint:
select b.* from ( select * from nuts3 a where a.nuts3 like 'Altötting' ) sq join bf_orte b on st_within(st_geomfromtext(b.center),sq.coords) ;
Unterabfragen können auch verwendet werden, um in einer where-Klausel eine Werteliste mit dem Operator "in" zu erzeugen:
-- select id_orte, gemeinde, hauptstruktur, ausgrabung from bf_fundplaetze where id_orte in ( select id_orte from bf_orte where gemeinde like 'München' or gemeinde like 'Straßl%' or gemeinde like 'Buch%' ) ;
Unterabfragen sind besonders wichtig beim Rechnen mit Daten.
2.5.11. Views
MySQL bietet die Möglichkeit, Abfragen in Form virtueller Tabellen, sog. "Views", gleichsam "einzufrieren".
Zur Erzeugung eines Views generiert man zunächst eine Abfrage, die ein gewünschtes Ergebnis liefert. Diese Abfrage kann ausgewählte Zeilen (Selektion) und Spalten (Projektion) aus einer einzigen Tabelle oder aber einem Verbund (Join) zweier oder mehrer Tabellen darstellen. Das Abfrageergebnis kann dann durch das Statement "create or replace view [frei_wählbarer_Name_des_Views] as" in einen View verwandelt werden.
Beispiel:
create or replace view `meinErsterView` as
select
vfpa_eisenzeit.fisdaten18_1.aktennummer,
archeolocalis.commune.nomCommune,
vfpa_eisenzeit.fisdaten18_1.landkreis,
st_astext(archeolocalis.commune.wkb) as wkt
from vfpa_eisenzeit.fisdaten18_1
join archeolocalis.commune using(codeCommune)
;
Nach Erzeugung des Views erscheint er in der Liste der Tabellen der Datenbank. In PMA sind alle Views unter der Kategorie "Ansichten" versammelt.
Views können, mit gewissen Einschränkungen, genauso behandelt werden wie "normale" Tabellen. So können sie mit select-Statments abgefragt und über join-Statements auch in Tabellenverbünde eingebunden werden:
select * from meinersterview join fisdaten18_2 on meinersterview.aktennummer =fisdaten18_2.aktennummer collate utf8_unicode_ci ;
Beim Abfragen eines Views wird dieser unmittelbar aus dem dahinterstehenden select-Statement neu generiert. Es handelt sich also nicht um eine reale, persistente Tabelle, sondern eben nur um eine virtuelle. Sämtliche Änderungen, die in den dahinterliegenden realen Tabellen erfolgen, spiegeln sich daher jeweils unmittelbar im View wider.
Da Views lediglich virtuelle Tabellen sind, können die darin angezeigten Daten nicht geändert werden (update-Statements führen zu einer Fehlermeldung).
Ein Nachteil von Views ist deren "Trägheit". Die Abfrage eines Views dauert stets länger als die einer hinsichtlich Datenbestand und Struktur identischen realen Tabelle. Gerade bei mehrfacher Einbindung von Views in komplexe, geschachtelte Abfragen, können daher Performance-Probleme auftreten.
2.5.12. Rechnen mit SQL
MySQL kennt die gängigen arithmetischen Operatoren:
- + (Addition)
- - (Subtraktion)
- * (Multiplikation)
- / (Division)
select 1 + 1; select (2 + 2.5) / 3; -- ACHTUNG: Als "Komma" muss ein Punkt verwendet werden!
-- Zeig die Epoche mit der längsten Dauer select *, concat(von-bis,' Jahre') as Dauer -- arithmetischer Operator: Minus (-) from ezepochen order by von-bis desc -- desc = descending; asc = ascending limit 1 ;
-- Errechne die Dauer der Einzelepochen und gib sie sortiert aus select bezeichnung, sum(von - bis) as Dauer -- "Dauer" = sog. Korrelatsname from ezepochen a group by Bezeichnung order by sum(von - bis) desc ;
Darüberhinaus stehen in MySQL zahlreiche mathematische Funktionen wie z.B. die Winkelfunktionen (Sinus, Cosinus, Tangens etc.) zur Verfügung.
/* Berechnung des Abstands zw. zwei Längengraden auf dem 47sten Breitengrad in Kilometern 6371 = Erdradius in Kilometern Die MySQL-Funktion pi() gibt den Wert von Pi aus (auf 15 Nachkommastellen genau). Die Multiplikation der Gradangabe mit pi/180 ist nötig, um den Radiant zu errechnen, der von der MySQL-Funktion cos() als Argument verlangt wird. Zur Berechnung der Distanz an anderen Breitengraden einfach die 47 ersetzen. */ select cos(47*pi()/180)*6371*2*pi()/360 ;
Es sind auch Berechnungen mit Zahlenwerten möglich, die das Ergebnis von Unterabfragen mit Gruppierungen darstellen. In diesem Fall, also wenn eine Unterabfrage nur eine Zahl liefert, mit der gerechnet werden soll, darf die Unterabfrage KEINEN Korrelatsnamen erhalten.
-- Beispiel -- Errechne den Anteil der Latène-Fundplätze an der Gesamtzahl -- eisenzeitlicher Fundplätze in Bayern select (select count(*) from fisdaten18 a where a.zeit like '%latène%') -- Unterabfrage OHNE Korrelatsname! / (select count(*) from fisdaten18 a) as `Anteil Latène-Fundplätze an der Gesamtzahl eisenzeitlicher Fundplätze in Bayern` ;
2.6. Anfertigung von Sicherheitskopien
2.6.1. Sicherung von einzelnen Tabellen oder ganzen Datenbanken mit PMA als SQL-Dump
- Fertigen Sie in regelmäßigen Abständen Sicherungen Ihrer Datenbank an, speziell dann, wenn Sie "riskante" Operationen mit den Statements der Data Manipulation Language (DML) wie update, delete, insert, truncate oder drop durchführen
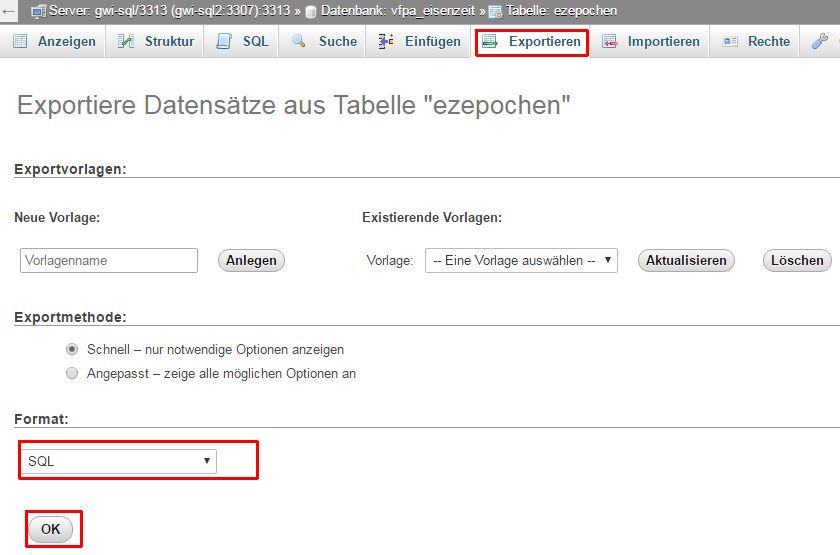
PMA-Formular für den Export von Daten
- Wählen Sie entweder eine ganze Datenbank oder eine einzelne Tabelle aus. Entsprechend erfolgt die Sicherung
- Klicken Sie auf den Reiter "Exportieren"
- Wählen Sie als Format "SQL" aus (ist meist default/vorausgewählt)
- Klicken Sie auf "OK"
- Der Browser lädt die Daten in Form einer Textdatei im SQL-Syntax herunter (befindet sich dann im Downloadordner Ihres Rechners)
- Der Name der Datei entspricht dem des gesicherten Datenbankobjekts, also der Datenbank oder der Tabelle, und besitzt die Extension .sql
- Benennen Sie die Datei um, indem Sie an den Namen als Suffix das aktuelle Datum in der Form _JJJJMMTT anhängen (Beispiel: ezepochen_20170515.sql)
Die SQL-Datei enthält sämtliche SQL-Statements, die für die Definition der Datenbank und/oder Tabelle(n) erforderlich sind:
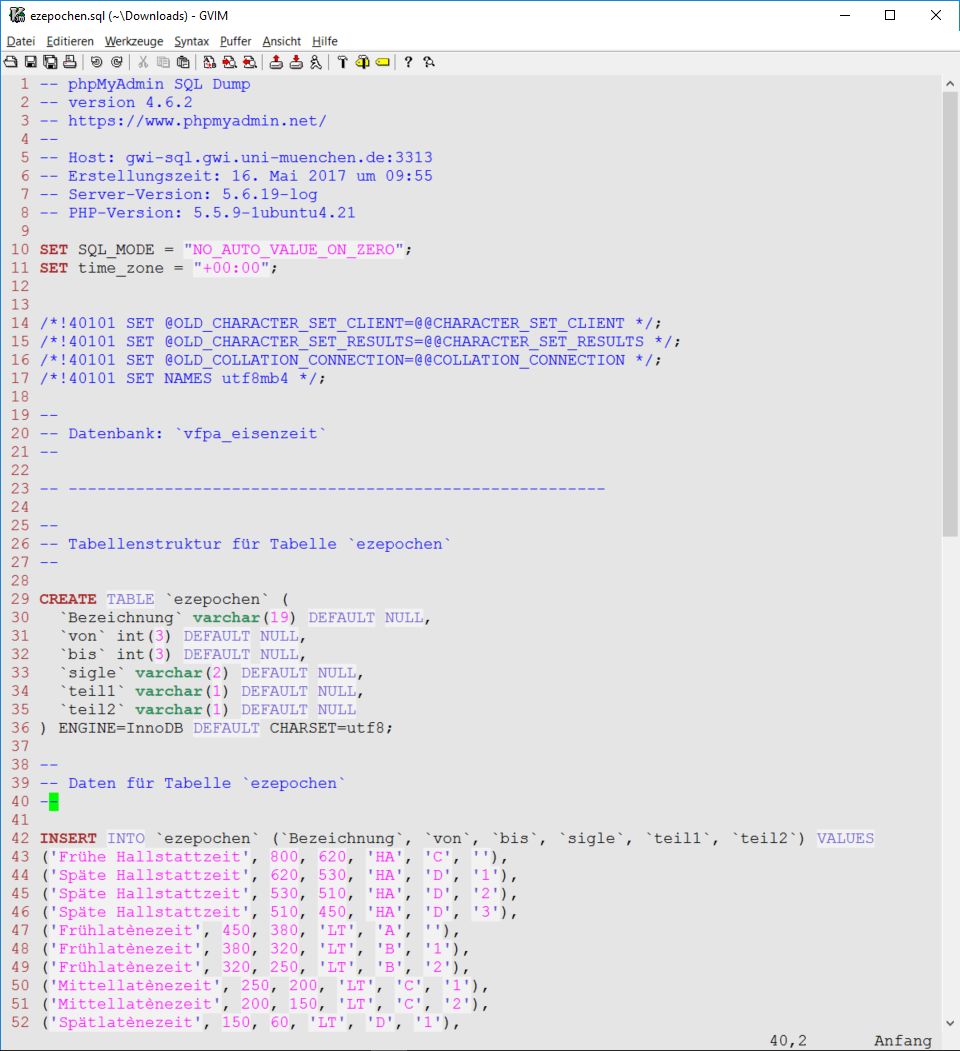
Beispiel eines Sql-Dumps
2.6.2. Export von Abfrageergebnissen als csv
- Über den Reiter "Exportieren" können Daten auch im csv-Format exportiert werden (etwa für den Import in Excel oder andere Tabellenkalkulationsprogramme; deren Stärke gegenüber MySQL ist die Erzeugung von Grafiken bzw. Diagrammen)
- Nach Auswahl von "Exportieren" unter "Format:" den Punkt "CSV" auswählen
- Unter "Exportmethode" den Punkt "Angepasst – zeige alle möglichen Optionen an" anklicken
- Unter "Formatspezifische Optionen:" folgende Werte Eintragen: "Spalten getrennt mit:" -> \t; "Spalten eingeschlossen von:" -> [leer; Anführungszeichen löschen]; "Spaltennamen in die erste Zeile setzen" -> Haken setzen
- Nach Klick auf OK wird die Datei vom Browser heruntergeladen und im Download-Verzeichnis abgelegt
- Die heruntergeladene csv-Datei mit einem Editor (Gvim, Notepad++ etc.; nicht Word!) öffnen, mit der Tastenkombination ctrl+a (Windows-Rechner) den kompletten Inhalt markieren, mit ctrl-c in den Zwischenspeicher nehmen, Tabellenkalkulationsprogramm (z.B. Excel) öffnen und mit ctrl+v den Inhalt der Zwischenablage in das leere Dokument einfügen
2.7. Anlage einer neuen Datenbanktabelle
Es gibt grundsätzlich mehrere Methoden, eine neue Datenbanktabelle anzulegen. In der Praxis geschieht das zumeist in zwei untschiedlichen Weisen: Entweder man legt eine Tabelle in PMA manuell an, d.h. man trägt Feld für Feld die erforderlichen Angaben in ein PMA-Formular ein, oder man bereitet eine csv-Datei vor, die zumindest exemplarisch ein gewisses Quantum an Daten in der gewünschten Struktur enthält, und nutzt die Import-Funktion von PMA. Letztere Variante ist die empfehlenswertere. PMA legt dann eine Tabelle mit genau der Anzahl an Spalten der importierten Datei an und definiert die einzelnen Felder passend zur Art der importierten Daten.
Generell sind bei der Anlage einer neuen Tabelle folgende Punkte zu beachten:
- Pro Tabelle nur *eine* Entität (Entität: Gruppe von Objekten mit identischen Merkmalskategorien)
- Pro Entität nur *eine* Tabelle
- Tabellen- und Spaltennamen ohne Sonder- und Leerzeichen (der Unterstrich kann als Ersatz für Leerzeichen verwendet werden: id_fundort )
- Tabellen- und Spaltennamen nur in Kleinbuchstaben
- Tabellen- und Spaltennamen möglichst kurz und sytematisch
- Tabellen- und Spaltennamen "sprechend" (nicht: a01, a02 etc.)
- Tabellen- und Spaltennamen aus Sicht von SQL nicht missverständlich (Alter -> engl. "ändern" !)
2.7.1. Anlage einer Datenbanktabelle mit der Import-Funktion von PMA
Entwurf, am einfachsten in Excel:
Tabellentwurf in einem Tabellenkalkulationsprogramm (z.B. Excel) (Download der Beispieldatei)
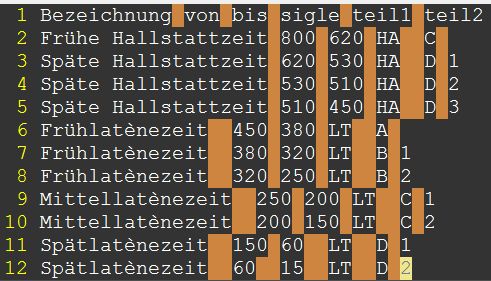
Der Inhalt der Excel-Tabelle wird am einfachsten mit der Copy/Paste-Methode in einen Texteditor (z.B. Vim) übertragen und von dort dann als csv-Datei abgespeichert. Als Feldtrenner werden dabei automatisch Tabulatorzeichen (\t) eingetragen. Die erste Zeile der csv-Datei sollte die Spaltennamen enthalten, die auch in der Datenbanktabelle verwendet werden sollen. Beim Import über PMA kann dann angegeben werden, dass die erste Zeile der csv-Datei die Spaltennamen enthält.
Inhalt der Datei Ezepochen.csv (download)
Nach dem Abspeichern der csv-Datei ruft man das Importieren-Formular von PMA auf:
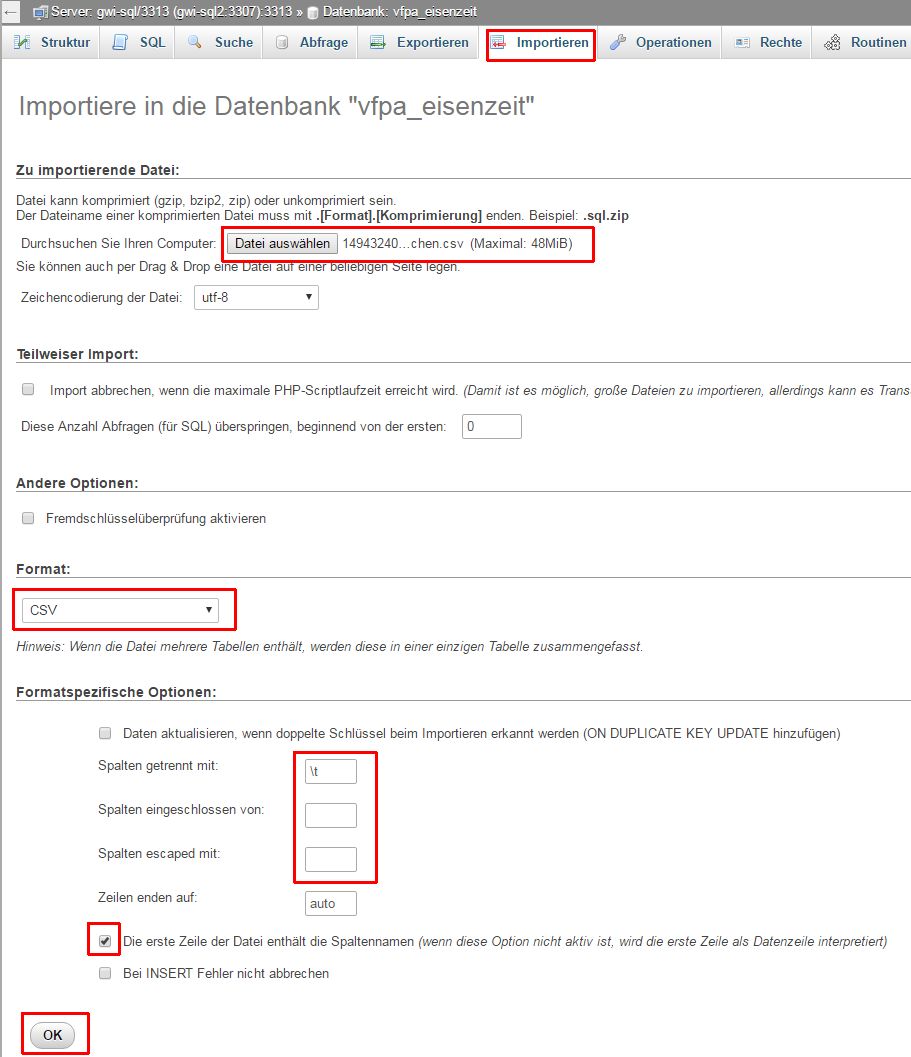
Importformular von PMA
- Wichtig: Zunächst durch Klicken auf das entsprechende Symbol im Objektbaum am linken Fensterrand die Datenbank auswählen, in der die Tabelle erzeugt werden soll (dunkelgrau hinterlegte Leiste am oberen Rand des Fensters beachten; dort muss als letzter Eintrag die Datenbank gelistet sein, es darf *keine Tabelle* innerhalb der Datenbank ausgewählt sein!)
- csv (= "character separated values"): Jede Zeile enthält eine identische Anzahl von Spalten
- als Feldtrenner empfiehlt sich der Tabstop/Tabulator (Schreibweise: \t)
- Die Datei sollte die Extension ".csv" besitzen
- "Datei auswählen" anklicken und csv-Datei im Dateisystem auswählen
- Bei "Spalten getrennt mit: " den Tabulator in der Schreibweise "\t" eintragen
- Bei "Spalten eingeschlossen von:" das doppelte Anführungszeichen entfernen
- Bei "Die erste Zeile der Datei enthält die Spaltennamen" gegebenenfalls einen Haken setzen
- Alle anderen Einstellungen bleiben normalerweise unverändert
- Auf "OK" klicken.
- Die Datei wird importiert und in einer Datenbanktabelle mit einem "generischen" Namen (z.B. `table 1` abgelegt. Diese Tabelle kann/muss sodann umbenannt werden. Dazu muss zunächst die entsprechende Tabelle angewählt werden. Anschließend klickt man auf den Reiter "Operationen" und trägt im Formular "Tabellenoptionen" den gewünschten Tabellennamen ein.
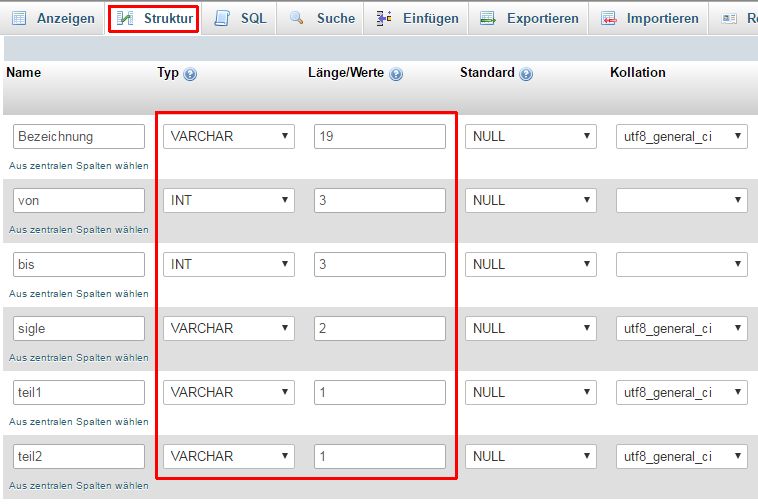
Überprüfung und Korrektur von automatisch erzeugten Felddefinitionen in PMA
- Abschließend müssen über den Reiter "Struktur" noch die generischen Spaltennamen (`col 1`, `col 2` ...) in geeignete Namen geändert werden. Dieser Schritt entfällt, wenn die importierte csv-Datei bereits die gewünschten Namen enthalten hatte und die entsprechende Option beim Import angegeben worden war.
- In jedem Fall müssen die Definitionen der Tabellenfelder angepasst werden. Neben dem Datentyp ist dabei vor allem auf dessen Dimensionierung (s. unten) zu achten. Beim Import mit PMA geben die längsten Werte in einer Spalte jeweils die Dimension der entsprechenden Spalte vor. Sollten später in die Felder neue Daten mit einer größeren Länge eingetragen werden, werden diese ohne Warnung abgeschnitten.
- ACHTUNG: Für den Import von größeren csv-Dateien (erfahrungsgemäß schon ab ca. 5 MB) ist PMA nicht geeignet, es kommt zu Fehlermeldungen. Größere Dateien werden am besten über die Kommandozeile (s.o.) mit Hilfe des Programms mysqlimport eingelesen.
2.7.2. Manuelle Anlage einer Tabelle in MySQL
Alternativ kann eine Tabelle in PMA auch manuell angelegt werden. Dazu klickt man im Objektbaum auf der linken Seite in der Rubrik "Tabellen" auf "Neu":
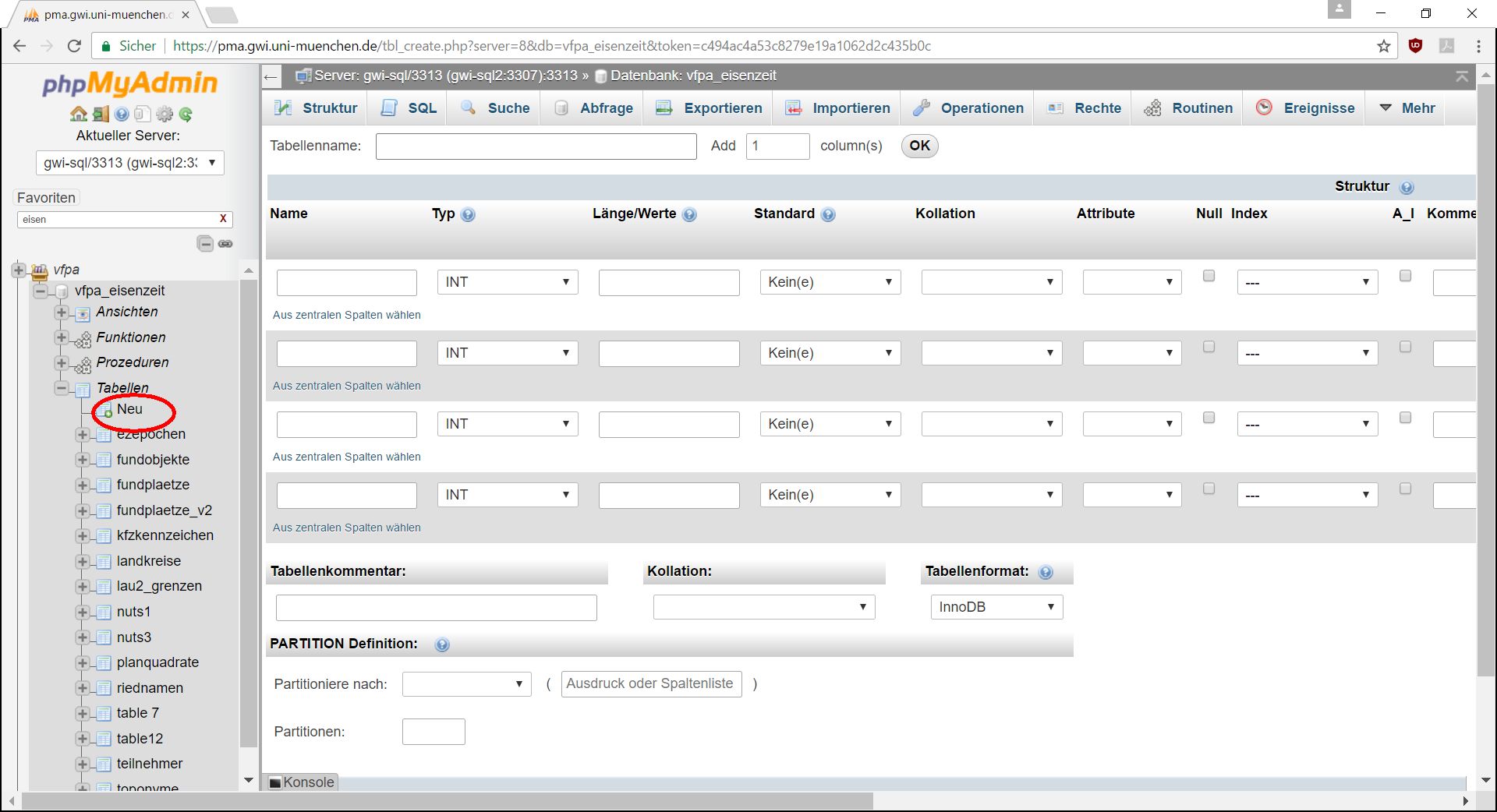
PMA-Formular für das Anlegen einer neuen Tabelle
2.7.3. Festlegung von Datentyp und Felddimension
Anders als in Tabellenkalkulationsprogrammen (z.B. Microsoft-Excel, LibreOffice-Calc usw.) muss in praktisch allen Datenbankmanagementsystemen und so eben auch in MySQL bei der Anlage einer Tabelle nicht nur die Anzahl und Benennung der einzelnen Spalten festgelegt werden, sondern auch die Art der Daten, die in einem Feld gespeichert werden sollen. MySQL kennt eine Reihe von unterschiedlichen Datentypen. Die am häufigsten verwendeten Datentypen sind die folgenden:
- varchar: beliebige Zeichenketten ("Strings") bis maximal 65535 Zeichen Länge, auch kürzer (Unterschied zu Datentyp text); "var" steht dabei nicht für "beliebige" Zeichen, sondern bezieht sich darauf, dass pro gespeichertem Wert kein fester Speicherplatz verwendet wird, sondern je nach Einzelwert genau so viel Speicher verwendet wird, wie für die Speicherung der Zeichenkette notwendig ist.
- int: positive Ganzzahlen (engl. "integer", dt. "natürliche Zahlen") inkl.
- enum: Auswahllisten
- geometry: Geometrische Daten im WKB-Format
Weitere, normalerweise etwas seltener verwendete Datentypen:
- decimal: Dezimalzahlen
- char: beliebige Zeichenketten („Strings“); feste Breite im Speicher
- text: Zeichenketten bis maximal 65535 Zeichen Länge
- longtext: Zeichenketten bis maximal 4 GB Zeichen Länge
- date: Datum (yyyy-mm-dd)
- datetime: (yyyy-mm-dd 00:00:00)
Versucht man, in ein Datenbankfeld Werte einzugeben, die nicht zur Felddefinition passen, so werden diese Daten entweder fehlerhaft oder auch gar nicht in dieses Feld eingetragen. Eine Fehlermeldung erfolgt normalerweise nicht.
2.7.3.1. Dimensionierung
Bestimmte Datentypen erfordern die Angabe der maximalen Feldbreite:
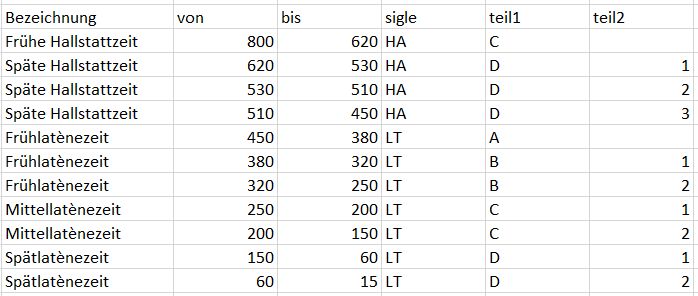
-- "create" ist ein "statement" aus der Data Definition Language (DDL) CREATE TABLE `ezepochen` ( `Bezeichnung` varchar(19) DEFAULT NULL, `von` int(3) DEFAULT NULL, `bis` int(3) DEFAULT NULL, `sigle` varchar(2) DEFAULT NULL, `teil1` varchar(1) DEFAULT NULL, `teil2` varchar(1) DEFAULT NULL ) ENGINE=InnoDB DEFAULT CHARSET=utf8 ;
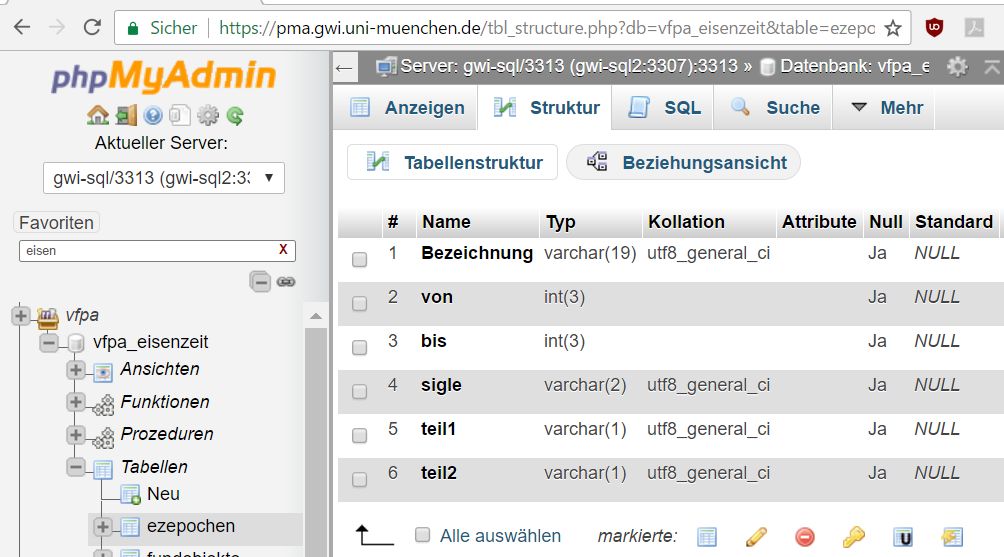
Anzeige von Felddefinitionen in PMA
Auf die bei der Felddefinition angegebene Maximallänge von Zeichenketten (Strings) ist bei der Eingabe von Daten besonders zu achten. Ist das Feld beispielsweise als varchar(10) definiert, können in dieses Feld nur Zeichenketten mit einer maximalen Anzahl von zehn Zeichen eingetragen werden. Längere Zeichenketten werden einfach nur bis zum zehnten Zeichen gespeichert, der Rest ohne Fehlermeldung abgeschnitten. Es empfiehlt sich, varchar-Felder, gemessen an den erwartbar dort abzulegenden Daten, lieber deutlich überzudimensionieren. Grundlage kann häufig nur eine grobe Abschätzung der zu erwartenden Maximallänge sein.
Den zu speichernden Daten nicht-adäquate Felddefinitionen können auch noch andere unerwünschte Effekte haben. So lassen sich z.B. Ganzzahlen durchaus in varchar-Felder eintragen, bei Sortierung der Daten werden die Zahlen dann jedoch nicht korrekt arithmetisch geordnet:
-- Tabellendefinition: CREATE TABLE `demo_felder` ( `zahl` varchar(3) DEFAULT NULL ) ENGINE=InnoDB DEFAULT CHARSET=utf8 ; -- Das Feld enthalte die Werte 1, 9, 10 select * from demo_felder a order by a.zahl ; -- Sortierergebnis 1 10 9
In einer bestehenden Datenbanktabelle ...
- können jederzeit neue Spalten hinzugefügt werden
- mehrere bestehende Spalten zu neuen Spalten zusammengeführt werden
Die entsprechenden Operationen können in PMA über den Reiter "Struktur" -> "Spalte(n) einfügen" durchgeführt werden:
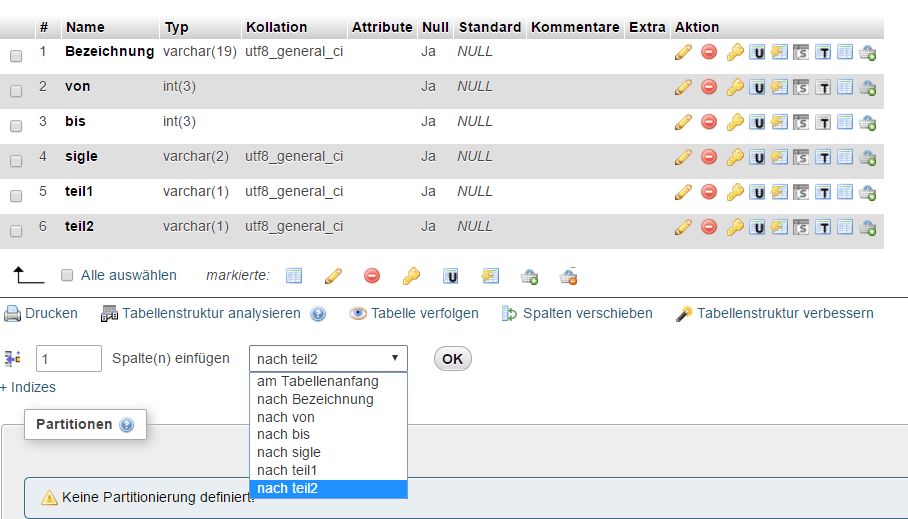
Hinzufügen einer neuen Spalte zu einer bestehenden Tabelle in PMA
2.8. Die Datenbank vfpa_eisenzeit
- Angelegt im Frühjahr 2017
- Adresse: https://pma.gwi.uni-muenchen.de:8888/db_structure.php?server=9&db=vfpa_eisenzeit (Eisenzeitdigital; Manch1ng)
- Datenquellen: Fachinformationssystem (FIS) des Bayerischen Landesamts für Denkmalpflege (BLFD) sowie Recherchen der Studenten von EZD1 und EZD-Beteiligten; Datenbank BaseFer (Kooperationsvereinbarung beabsichtigt)
- Die Datenbank stellt den Kern der Datensammlung und -verwaltung dar
- Schnittstellenkonzept für Übernahme, Weitergabe (z.B. an BaseFer) und Verwendung (Programme: QGIS, Google Maps, R etc.)
2.8.1. Struktur und Tabellen in vfpa_eisenzeit
Die Datenbank vfpa_eisenzeit enthält zahlreiche Tabellen, viele davon haben rein technisch/administrative Bedeutung. Die wichtigsten Tabellen sind:
2.8.1.1. Tabelle daten_sose17
- Die Tabelle `daten_sose17` besitzt die endgültige Datenstruktur, in der auch die Daten von EZD2 (SoSe 18) und andere, bislang noch nicht umstrukturierte Daten, vorliegen sollen
- enthält die Daten aus dem Seminar EZD1, überprüft und ggf. korrigiert von Robin Franke
- enthält eine Sammlung von eisenzeitlichen Fundplätzen, die nach Periode und Hauptstruktur unterschieden werden.
- Mittelbare Georeferenzierung durch Zuweisung der Fundplätze zu den Gemeinden, innerhalb derer Gemarkung die Fundplätze liegen (Feld `id_orte`) - Keine Speicherung der genauen Polygondaten der Fundplätze auf dem Gemeindegebiet!
- Fundplätze, die mehreren Perioden und/oder Hauptstrukturen zugeordnet werden können, erscheinen in der Tabelle mehrfach, also in mehreren Datensätzen. Die Zugehörigkeit zu ein und demselben Fundplatz ergibt sich aus der Nummerierung im Feld nr_fundplatz
- nicht selbsterklärende Spalten:
- id_fundplaetze: Identifiziert einen Fundplatz, der am Ort bezüglich seiner Periode und der Hauptstruktur distinkt ist
- nr_fundplatz: gruppiert Fundplätze unterschiedlicher Periode und Hauptstruktur zu einem Fundplatz
- id_orte: bezieht sich auf die Gemeindenummer in der Tabelle archeolocalis.Commune
- denkmalnummer: Sofern es sich um ein Bodendenkmal handelt, vergibt das BLFD eine Denkmalnummer. Nicht jede Fundstelle wird zum Bodendenkmal erklärt und erhält somit auch keine Denkmalnummer
- blfd_koid: Technischer Identifikator im FIS des BLFD
- blfd_aktennummer: Aktennummer des BLFD. Diese Nummer bezieht sich auf eine Maßnahme (Ausgrabung, Luftbild ...). Mehrere Aktennummern können zu einer Denkmalnummer zusammengefasst sein, aber nicht jede Aktennummer muss einer Denkmalnummer zugeordnet sein.
2.8.1.2. Tabelle fisdaten18
- enthält Daten aus dem Fachinformationssystem (FIS) des BLFD aus dem April 2018
- umfasst eisenzeitliche Fundstellen in ganz Bayern
- ist eigentlich ein sog. "view", der die Daten aus den beiden Tabellen fisdaten18_1 und fisdaten18_2 kombiniert
- mehrperiodige Fundstellen tauchen in der Tabelle in mehreren Datensätzen auf
- nicht selbsterklärende Spalten:
- codeCommune: Gemeindenummer nach archeolocalis.commune.codeCommune (= von BaseFer verwendete Datenbank mit Geoinformationen)
- Gemeindenummer nach Eurostat (Link: http://ec.europa.eu/eurostat/cache/GISCO/geodatafiles/COMM-01M-2013-SH.zip)
- aktennummer: Aktennummer des BLFD. Diese Nummer bezieht sich auf eine Maßnahme (Ausgrabung, Luftbild ...). Mehrere Aktennummern können zu einer Denkmalnummer zusammengefasst sein, aber nicht jede Aktennummer muss einer Denkmalnummer zugeordnet sein.
- wkb_geom: Fläche (Polygon) der Fundstelle im WKB-Format (s.u.)
Zentrales Feld der Tabelle ist die Aktennummer. Jede Aktennummer bezieht sich auf eine Maßnahme, die zu einem Befund mit Bezug zur Eisenzeit geführt hat. Im Fall, dass sich bei einer Maßnahme Befunde ergeben haben, die sich auf mehr als eine eisenzeitliche Periode und/oder mehr als eine Hauptkategorie beziehen, taucht die entsprechende Aktennummer in mehr als einem Datensatz in der Tabelle auf. Ein Beispiel: Die Aktennummer E-2007-24887-2_0-1 bezieht sich auf eine Fundstelle in der Gemeinde Alteglofsheim im Landkreis Regensburg. Bei der entsprechenden Maßnahme wurden eine Siedlung aus der späten Latènezeit festgestellt sowie ein Einzelfund konstatiert, der zwar ebenfalls aus der späten Latènezeit stammt, jedoch offenkundig nicht der Siedlung zugordnet werden konnte. Entsprechend existieren in der Tabelle fisdaten18 zwei Datensätze, die die beiden Befunde getrennt verzeichnen:
select aktennummer, concat(a.gde, ' (Landreis ', a.landkreis, ')') as Gemeinde, zeit, typ from fisdaten18 a where aktennummer like 'E-2007-24887-2_0-1' ;
NO QUERY GIVEN!
Ein weiteres Beispiel: Ein Siedlungsfund aus dem Landkreis Straubing-Bogen, der sich über zwei Perioden erstreckt und auf den sich die Aktennummer E-2007-17076-1_0-0 bezieht, taucht ebenfalls zweimal in der Tabelle fisdaten18 auf:
NO QUERY GIVEN!
Umgekehrt ist es jedoch auch möglich, dass ein Fundplatz, der ein und derselben Periode und einer identischen Hauptstruktur angehört, in der Tabelle fisdaten18 mehreren Aktennummern zugeordnet ist, weil die Befunde aus mehreren unterschiedlichen Maßnahmen stammen. Ein gutes Beispiel ist das Oppidum bei Manching. Befunde, die der latènezeitlichen Phase dieses Oppidums zuzuordnen sind, stammen aus insgesamt neun verschiedenen Maßnahmen:
select a.aktennummer, a.gde, zeit, typ from fisdaten18 a where a.gde like 'Manching' and zeit like 'Jüngere Eisenzeit/Latènezeit' and typ like 'Oppidum' ;
NO QUERY GIVEN!
2.8.2. Geokoordinaten in vfpa_eisenzeit
- Geokoordinaten werden im Koordinatenbezugssystem WGS84 (EPSG-Code: 4326; EPSG = European Petroleum Survey Group Geodesy) gespeichert
- Die Geokoordinaten werden in der Datenbank im WKT- (Well Known Text) oder WKB-(Well Known Binary) Format abgespeichert.
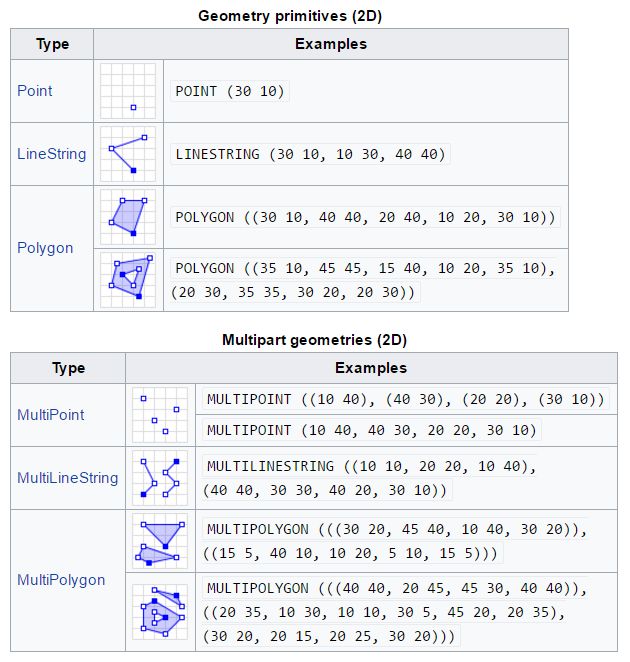
POINT(11 47) -> select geomfromtext('POINT(11 47)') ->
-> 0x00000000010100000000000000000026400000000000804740
- WKT- und WKB-Format können mit Hilfe von MySQL-Funktionen wechselseitig ineinander überführt werden:
-- Beispiel: Koordinaten von München in der Datenbank Archeolocalis: select a.nomCommune as Name, a.xCommune as lng, a.yCommune as lat from commune a where a.nomCommune like 'München' ; -- Ergebnis: München | 11.54219 | 48.15328 -- Erzeugung von WKT: select a.nomCommune as Name, concat('POINT(',a.xCommune, ' ', a.yCommune, ')') as WKT from commune a where a.nomCommune like 'München' -- Ergebnis: München | POINT(11.54219 48.15328) -- Erzeugung von WKB aus WKT: select a.nomCommune as Name, st_geomfromtext(concat('POINT(',a.xCommune, ' ', a.yCommune, ')')) as WKB from commune a where a.nomCommune like 'München' ; -- Ergebnis: München | 0x000000000101000000BD6F7CED99152740C190D5AD9E134840 -- Erzeugung von WKT aus WKB: select a.nomCommune as Name, st_astext(st_geomfromtext(concat('POINT(',a.xCommune, ' ', a.yCommune, ')'))) as WKT from commune a where a.nomCommune like 'München' ; -- Ergebnis: München | POINT(11.54219 48.15328)
2.9. Analyse der Daten
2.9.1. Häufigkeit der einzelnen Fundepochen bezogen auf die Gemeindegebiete innerhalb eines Landkreises
- Einfache Gruppierung
SELECT
gemeinde,
periode,
count(*) as Anzahl
FROM `daten_sose18_labuser_mhinnen_tmaier`
group by gemeinde, periode
;
2. Darstellung als Pivot-Tabelle
select substring_index(a.gemeinde,' | ',1) as Gemeinde, ifnull(b.Anzahl,0) as HA, ifnull(c.Anzahl,0) as HAC, ifnull(d.Anzahl,0) as HAD, ifnull(e.Anzahl,0) as LT, ifnull(f.Anzahl,0) as LTA, ifnull(g.Anzahl,0) as LTB, ifnull(h.Anzahl,0) as LTC, ifnull(i.Anzahl,0) as LTD1, ifnull(j.Anzahl,0) as LTD2, ifnull(b.Anzahl,0) + ifnull(c.Anzahl,0) + ifnull(d.Anzahl,0) as Hallstatt_gesamt from ( SELECT DISTINCT gemeinde FROM `daten_sose18_labuser_mhinnen_tmaier` ) a left join ( SELECT gemeinde, count(*) as Anzahl FROM `daten_sose18_labuser_mhinnen_tmaier` where periode like 'HA' group by gemeinde ) b on a.gemeinde=b.gemeinde left join ( SELECT gemeinde, count(*) as Anzahl FROM `daten_sose18_labuser_mhinnen_tmaier` where periode like 'HAC' group by gemeinde ) c on a.gemeinde=c.gemeinde left join ( SELECT gemeinde, count(*) as Anzahl FROM `daten_sose18_labuser_mhinnen_tmaier` where periode like 'HAD' group by gemeinde ) d on a.gemeinde=d.gemeinde left join ( SELECT gemeinde, count(*) as Anzahl FROM `daten_sose18_labuser_mhinnen_tmaier` where periode like 'LT' group by gemeinde ) e on a.gemeinde=e.gemeinde left join ( SELECT gemeinde, count(*) as Anzahl FROM `daten_sose18_labuser_mhinnen_tmaier` where periode like 'LTA' group by gemeinde ) f on a.gemeinde=f.gemeinde left join ( SELECT gemeinde, count(*) as Anzahl FROM `daten_sose18_labuser_mhinnen_tmaier` where periode like 'LTB' group by gemeinde ) g on a.gemeinde=g.gemeinde left join ( SELECT gemeinde, count(*) as Anzahl FROM `daten_sose18_labuser_mhinnen_tmaier` where periode like 'LTC' group by gemeinde ) h on a.gemeinde=h.gemeinde left join ( SELECT gemeinde, count(*) as Anzahl FROM `daten_sose18_labuser_mhinnen_tmaier` where periode like 'LTD1' group by gemeinde ) i on a.gemeinde=i.gemeinde left join ( SELECT gemeinde, count(*) as Anzahl FROM `daten_sose18_labuser_mhinnen_tmaier` where periode like 'LTD2' group by gemeinde ) j on a.gemeinde=j.gemeinde ;
Eine Antwort