Für großräumig angelegte perzeptive Untersuchungen bietet sich der Einsatz von Webtechnologien und Datenerhebung durch Crowdsourcing an. Einige unterschiedlich dimensionierte und thematisch unterschiedlich perspektivierte Projekte werden im Folgenden kurz vorgestellt.
1. Metropolitalia
Das Projekt Metropolitalia (vgl. Krefeld & Bry & Lücke 2012) entstand als sprachwissenschaftliche Erweiterung des bereits sehr erfolgreich laufenden kunstgeschichtlichen Projekts Artigo von Hubertus Kohle und François Bry; beide bildeten den Rahmen einer gemeinsamen Plattform mit dem programmatischen Titel play4science: Die theoretische Absicht bestand darin, den Nutzen von spielerisch angelegten Oberflächen für die Gewinnung wissenschaftlicher Daten auszuloten; solche mit crowdsourcing operierenden Spiele laufen unter der von Louis von Ahn geprägten Bezeichnung gwap (game with a purpose).
Im Fall von Metropolitalia bestand die Absicht darin, Merkmale des Regionalitalienischen (Primärdaten) sowie ihre womöglich mehrdimensionale variationslinguistische Markierung (Metadaten) zu erheben (vgl. zur Variationslinguistik Krefeld 2020); dazu sollte eine Kombination von auto- und heteroperzeptiven Strategien eingesetzt werden. Weiterhin sind die für die Datenerhebung eingesetzten Spiele so konzipiert, dass die erhobenen Daten mit zunehmender Laufzeit durch das Spiel selbst auch validiert werden.
Das leitende Grundprinzip bestand darin,
- den medialen Rahmen, d.h. die Anonymität der Nutzer rückhaltlos zu akzeptieren;
- möglichst wenige, leicht verständlich formulierte metasprachliche Kategorien vorzugeben;
- möglichst verlässliche Ergebnisse zu erzielen.
Sowohl die Erhebung wie die Dokumentation wurden über eine interaktive kartographische Oberfläche gesteuert und visualisiert.
1.1. Erhebung von Primärdaten
Eine spezielle Funktion (INVIA UN'ESPRESSIONE) dient der Eingabe von Primädaten, die - wenn möglich - mit einer standarditalienischen Übersetzung versehen werden müssen ('L'espressione signifca: ...'). Die vorgeschlagene Form muss sodann durch Klick auf einer interaktiven Karte Italiens und des Tessin verortet werden; dazu werden vier unterschiedliche Granulierungsstufen angeboten, die jeweils je nach Genauigkeit des sprachlichen Wissens gewählt werden können:
| Granulierungsstufen | |||
| 1 | 2 | 3 | 4 |
| Schweiz | Kanton Tessin | Gemeinden (merkwürdiger Weise nicht ganz vollständig) | |
| Norditalien | Regionen | Provinzen | |
| Mittelitalien | |||
| Süditalien | |||
| Sardinien | |||
Grundsätzlich ist damit also auch die Eingabe von lokaldialektalen Daten möglich. Die Nutzer können sich registrieren; sie werden jedoch nach keinerlei biographischer Information gefragt. Um das Spiel in Gang zu setzen war eine kritische Masse an Beispielen nötig, die vorab aus der linguistischen Literatur zum Regionalitalienischen übernommen und in die Datenbank eingegeben worden war.
1.2. Erhebung von Metadaten
Der Nutzer sieht einen Ausdruck, der vom System randomisiert ausgewählt wird. Mit diesem Beispiel, dessen Bedeutung er sich zeigen lassen kann, müssen die folgenden Operationen durchgeführt werden:
- Verortung auf der Karte gemäß einer der vier Granulierungsstufen durch Klicken;
- Einschätzung des Bekanntheitsgrades in der Sprechergemeinschaft durch einen Schieberegler;
- Feststellung der markierten Elemente, d.h. der auffälligen Varianten des jeweiligen Beispiels durch Klicken; diese Operation wird mit dem Hinweis versehen, wie andere Spieler die Markiertheit desselben Elements eingeschätzt haben;
- Zuordnung der Markiertheitsdimensionen GESCHLECHT, ALTER und BILDUNG durch Klicken, wie auf dem folgenden Bild:
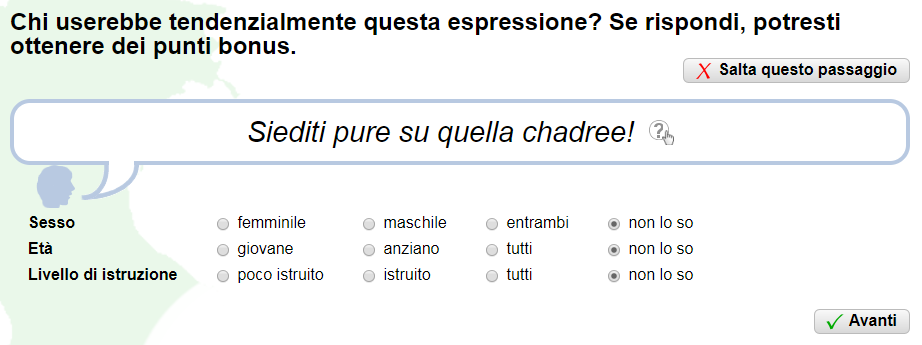
Metropolitalia - Annotierung gemäß drei unterschiedlicher Dimensionen der Markiertheit
Es gibt also keinerlei authentische Herkunft, weder der Beispiele noch der Informanten, jenseits der medialen Oberfläche; daher wurde konsequenterweise auch darauf verzichtet, die von den Spielern vorgenommene Zuordnung als richtig oder falsch zu qualifizieren; es wird einzig ein Abgleich mit den anderen Einschätzungen gegeben, wie das folgende Bild zeig (vgl. recognize):
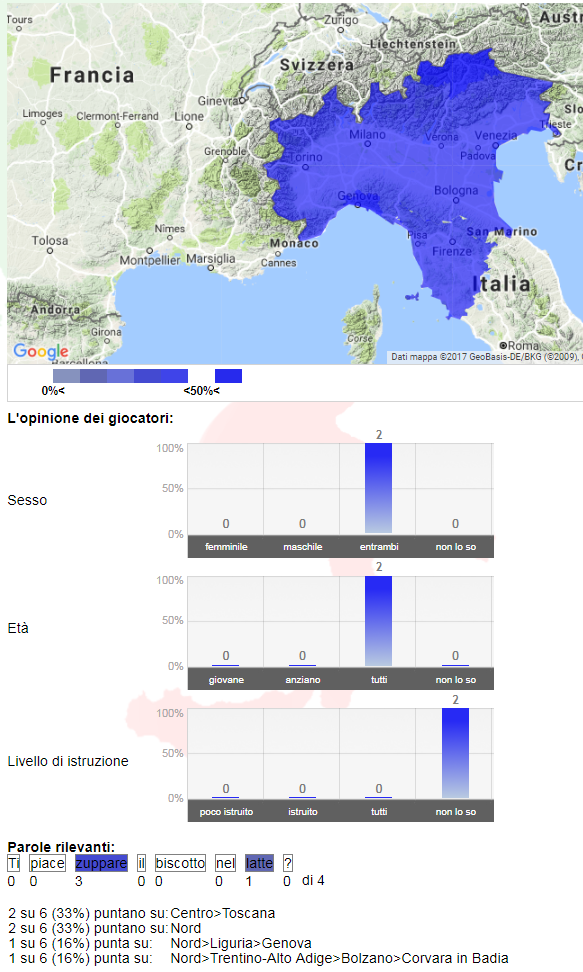
In Metropolitalia erzeugte Metadaten
1.3. Fazit
Der Grundgedanke, auf der Grundlage der Neuen Medien eine Art sich selbst validierender Online-Dokumentation einzurichten, trägt sicherlich. Weniger leicht ist die Sichtbarkeit des Spiels in der Flut des Internetangebots und seine Attraktivität für mögliche Spieler (=Informanten) abzusehen; der Spielverlauf in Metropolitalia ist zwar im Hinblick auf das sprachwissenschaftlich gewünschte Ergebnis gut durchdacht, aber offensichtlich aus Sicht des potentiellen Spielers ein wenig künstlich; überhaupt muss man, gerade nach den aktuellen Erfahrungen aus anders ausgerichteten Projekten (vgl. die Funktion Mitmachen! in VerbaAlpina) feststellen, dass sich der Spielgedanke für den Bereich der Sprache als nicht sehr zielführend erwiesen hat. Vielversprechender erscheint es, den möglichen Interessenten aus der crowd zu signalisieren, wie wertvoll ihr sprachliches Wissen für die Wissenschaft ist. Sprecher wollen ernst genommen werden (was attraktive Oberflächen keineswegs ausschließt).
Technisch unzulänglich sind fehlende Visualierungen des Gesamtdatenbestands und vom Raum (Region, Gemeinde usw.) ausgehende Abfragemöglichkeiten. Nicht bewährt hat sich im Nachhinein die Nutzung des kommerziellen Dienstes Google Maps für die Kartierung; die Entscheidung hing womöglich davon ab, dass die entsprechenden Open Source-Dienste, wie zum Beispiel OpenStreetMap (Link), noch nicht hinreichend entwickelt waren. Die Datenbank wurde leider isoliert konzipiert und passt gerade nicht in die allgemeine Lehr- und Forschungsumgebung in der z.B. der vorliegende Text zugänglich gemacht wurde; auch eine frei zugängliche und nutzerfreundliche Webschnittstelle zur direkten Datenbankabfrage bzw. -einsicht fehlt.
2. Accenti urbani
Im Zusammenhang mit Metropolitalia wurde im Rahmen einer Magisterarbeit (vgl. Cramerotti 2011) ein anderes, bescheiden dimensioniertes Projekt durchgeführt, das sich als sehr erfolgreich erwies. In Accenti urbani sollte die Erkennbarkeit und Akzeptanz italienischer Stadtakzente getestet werden. Es wurden ausschließlich Metadaten erhoben, die sehr sorgfältig ausgewertet wurden.
2.1. Getestete Daten
Ganz im Sinne der digital humanities wurden die getesteten Daten nicht eigens aufgenommen, sondern es wurde eine kleine Auswahl aus dem im Internet bereits vorhandenen und sehr gut geeigneten auditiven Korpus CLIPS von Federico Albano Leoni 2004 zu Grunde gelegt. Dort findet sich ein Teilkorpus mit Dialogen von Sprechern aus 15 italienischen Städten (BARI, BERGAMO, CAGLIARI, CATANZARO, FIRENZE, GENOVA, LECCE, MILANO, NAPOLI, PALERMO, PARMA, PERUGIA, ROMA, TORINO, VENEZIA). Pro Stadt wurden zufällig zwei kurze Dialoge ausgesucht, in denen sich die SprecherInnen jeweils Wegbeschreibungen auf fiktiven Plänen geben mussten (und so keinen Hinweis auf ihren realen Ort geben können). Die Probanden des Perzeptionstests haben die doppelte Aufgaben, den jeweiligen Akzent in drei Kategorien zu bewerten
- 🙂
- 😐
- 🙁
und anschließend die Hörproben auf einer interaktiven Italienkarte in den vorgegebenen Städten zu verorten; im Unterschied zu Metropolitalia gibt es hier also richtige und falsche Zuweisungen. Die Ergebnisse aus vier Wochen (22.6.-21.7.2011) wurden ausgewertet.
"Insgesamt haben 562 Spieler das Spiel Accenti Urbani gespielt. Da [...] die Angabe der Spielerherkunft freiwillig ist, haben nicht alle Spieler diese Information preisgegeben. Insgesamt haben 437 Spieler ihre Herkunft nach der vierten Runde genannt. Für die Spielerherkunft ergibt sich folgende Verteilung: 387 Spieler stammen aus Italien, 4 Spieler kommen aus der Schweiz und die restlichen 46 Spieler haben die Frage nach der ihrer Herkunft mit Sonstiges (d.h. weder aus Italien noch aus der Schweiz) beantwortet.Für eine detaillierte und unverfälschte Auswertung sind jedoch nur solche Spieler relevant, die aus Italien stammen und zudem zumindest spezifiziert haben, aus welcher Region sie kommen. Von den 387 italienischen Spielern sind das insgesamt 360 Spieler, die diese Kriterien erfüllen und somit die Basis für die Auswertung des Spiels Accenti Urbani bilden." (Cramerotti 2011, 66f.)
Das Spiel läuft übrigens immer noch; bis zum 7.11.2017 wurden 20.458 Runden gespielt, davon 5.335 mit richtiger Erst-, 3.132 mit richtiger Zweit- und 2.829 mit richtiger Drittzuweisung. Im Jahre 2017 kamen (ebenfalls bis zum 7.11.) immerhin noch 319 Spielrunden zustande, 2016 waren es insgesamt 840.1
Die wichtigsten Ergebnisse werden im Folgenden angedeutet:
- Eine Korrelation zwischen der Herkunft der Probanden und der positiven Bewertung der 15 Stadtdialekte ist offensichtlich; grosso modo gilt die Regel: je geringer die geographische Entfernung, desto positiver ist die Wahrnehmung. Hier einige Beispiele mit süditalienischen Stimuli:
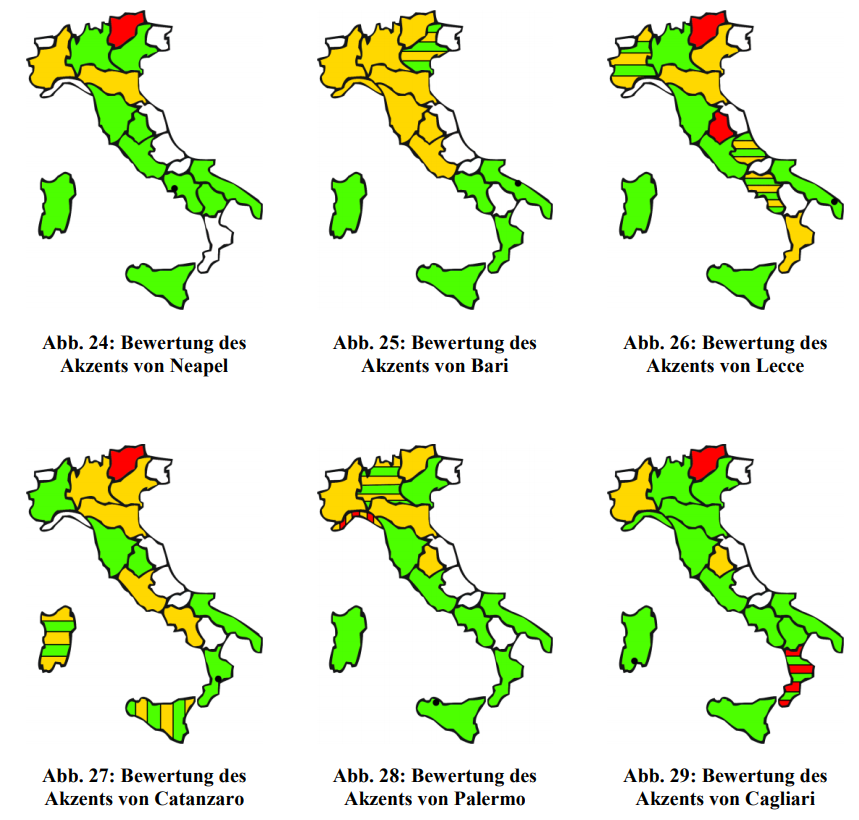
Probandenherkunft und Bewertung (grün = 🙂 gelb = 😐 rot = 🙁 und • = Herkunft des getesteten Stimulus (aus: Cramerotti 2011, 75)
- Auch die Erkennbarkeit nimmt grosso modo mit zunehmender Entfernung ab, wie das Beispiel von Lecce auf der folgenden Karte exemplarisch zeigt:
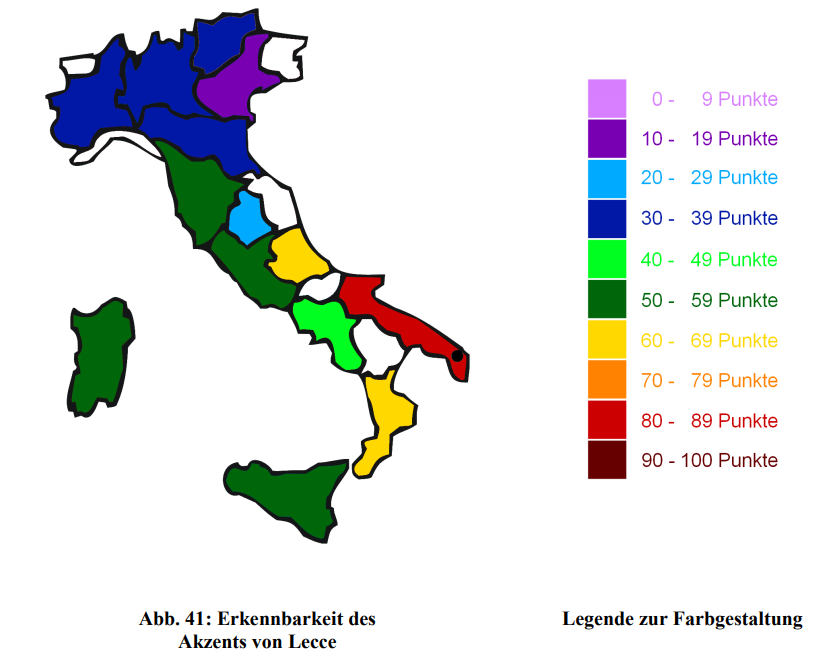
Geographische Entfernung und Erkennbarkeit (aus: Cramerotti 2011, 94)
Das gilt aber nicht, oder nur noch in ganz abgeschwächter Weise für die sehr bekannten Akzente, wie z.B. für den römischen:
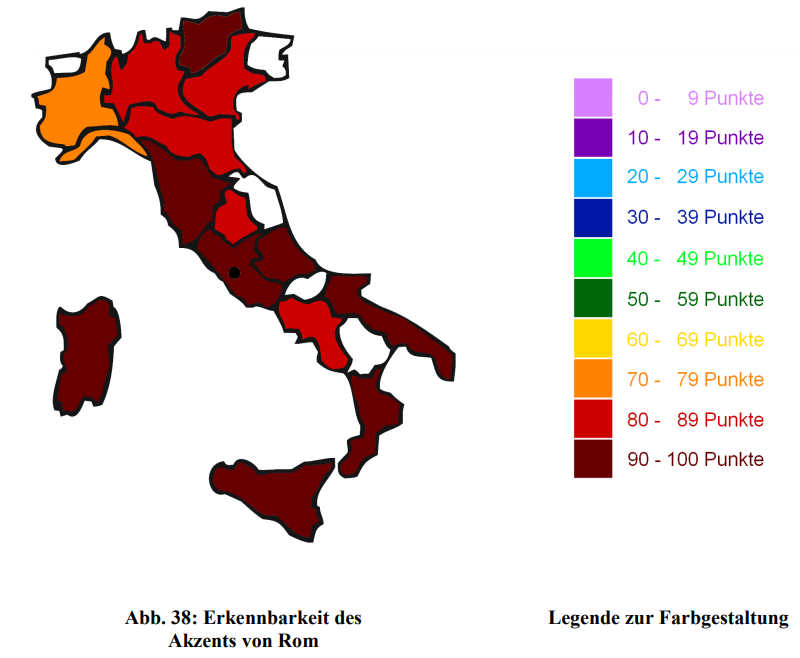
Erkennbarkeit des römischen Akzents (Cramerotti 2011, 93)
- Unverkennbar ist auch die zuverlässige Erkennbarkeit der Großräume; sie geht gerade aus den Fehlzuordnungen klar hervor; die beiden folgenden Karten zeigen zwar, dass innerhalb von Norditalien nicht grundsätzlich eine strenge Korrelation von geographischer Nähe und Erkennbarkeit zu beobachten ist, dass aber auch bei Fehlzuordnungen von Städten die großräumige Zugehörigkeit zum Norden eindeutig erkannt wird.
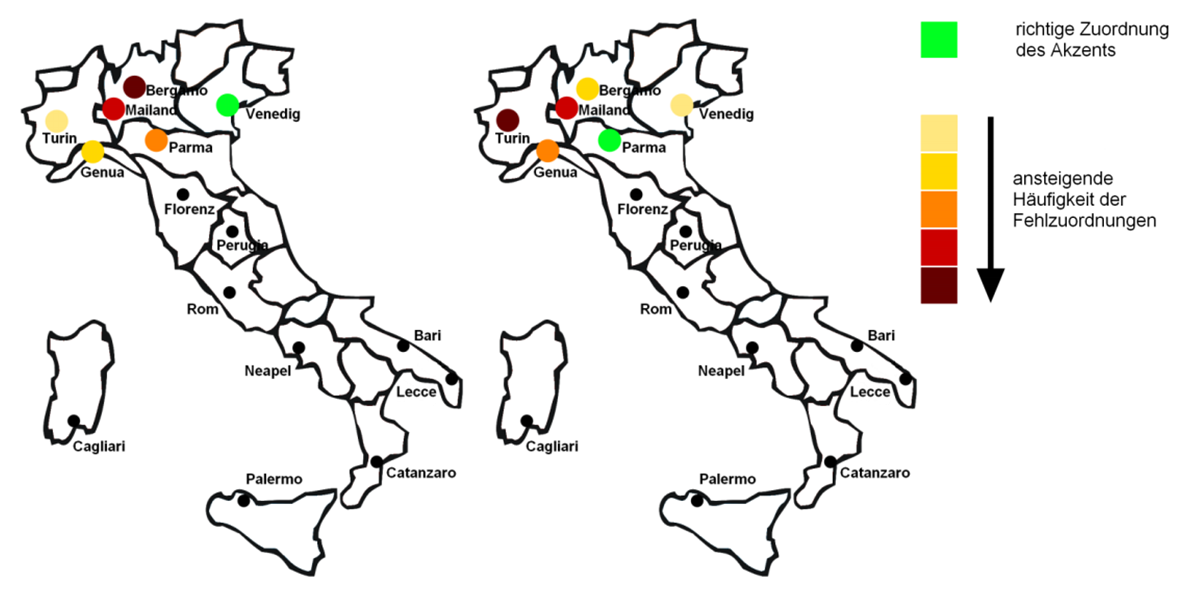
links: Venedig | rechts: Parma - Fehlzuordnungen mit richtiger Erkennung des Großraums (aus: Cramerotti 2011, 105)
Es wäre weiterhin sehr interessant, Erkennbarkeit und Bewertung systematisch im Zusammenhang zu untersuchen und zu fragen, ob das Unbekannte spontan nicht als positiv perzipiert wird. Als sehr schlecht erkennbar - selbst in der städtischen Autoperzeption - erweist sich der Akzent von Genua; damit einher geht seine weithin neutrale Bewertung:
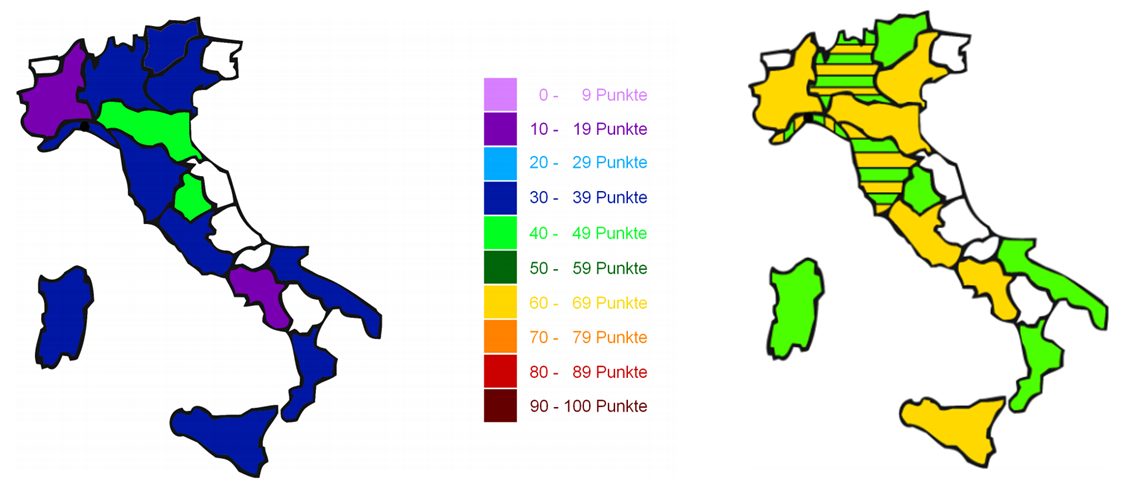
Genua - links Erkennbarkeit (aus: Cramerotti 2011, 92) und rechts Bewertung (aus: Cramerotti 2011, 74)
Die folgenden Kartenserien zeigen, dass dieser Effekt bei Probanden aus dem Trentino-Alto Adige besonders ausgeprägt ist; nicht nur schwache (oben dunkelblau), sondern bereits eingeschränkte Erkennbarkeit (oben gelb) korreliert mit nicht nur neutraler, sondern negativer Bewertung (unten rot). Genauso verhalten sich die Probanden aus Umbrien bei der Perzeption des Stimulus aus Lecce (oben hellblau unten rot):
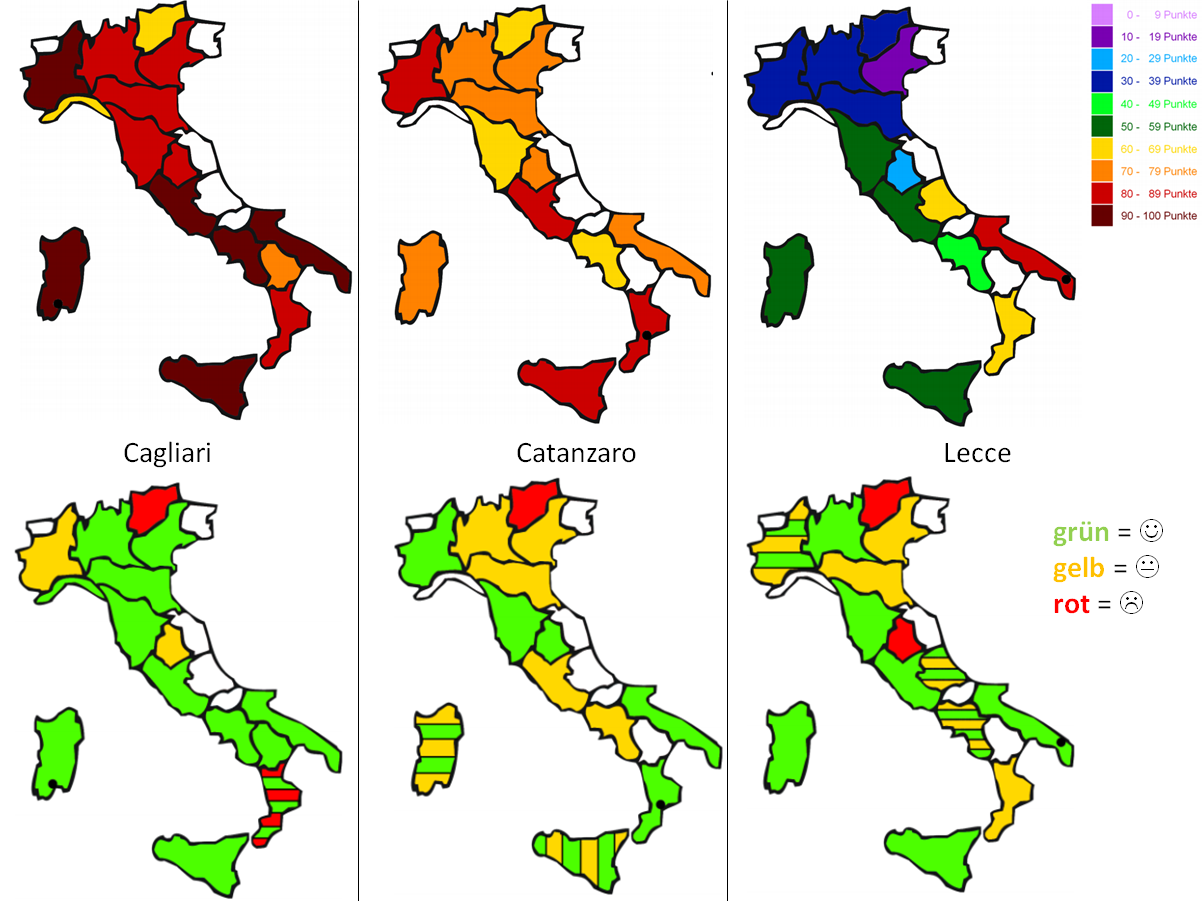
oben: Erkennbarkeit (aus: Cramerotti 2011, 95) - unten: Bewertung (aus: Cramerotti 2011, 75)
3. L-2 Akzente
Der L2-Erwerb gehört zwar zu den stark beforschten Bereichen, aber in kommunikationsräumlicher Perspektive ist die Problematik bislang kaum untersucht worden (vgl. Marotta 2008 and Marotta & Boula de Mareüil 2010). Hier stellen sich mehrere grundsätzliche Fragen:
- Sind L2-Akzente im Sprachwissen der L1-Sprecher repräsentiert?
- Sind L1-Sprecher in der Lage L2-Akzente zu erkennen und - wenn ja - welche?
- Impliziert ein L2-Akzent eine lokale/regionale Färbung durch Akkomodation an die lokal/regional markierten Varietäten/Varianten der L1-Sprecher, so dass der Wohnort in Italien erkennbar ist?
Einen ersten, quantitativ noch nicht hinreichend abgesicherten Eindruck gibt die Magisterarbeit von Julia Matzinger 2015, auf die hier nur ein Schlaglicht geworfen wird. Die wichtigsten Ergebnisse stecken in nuce in den beiden folgenden Tabellen2:
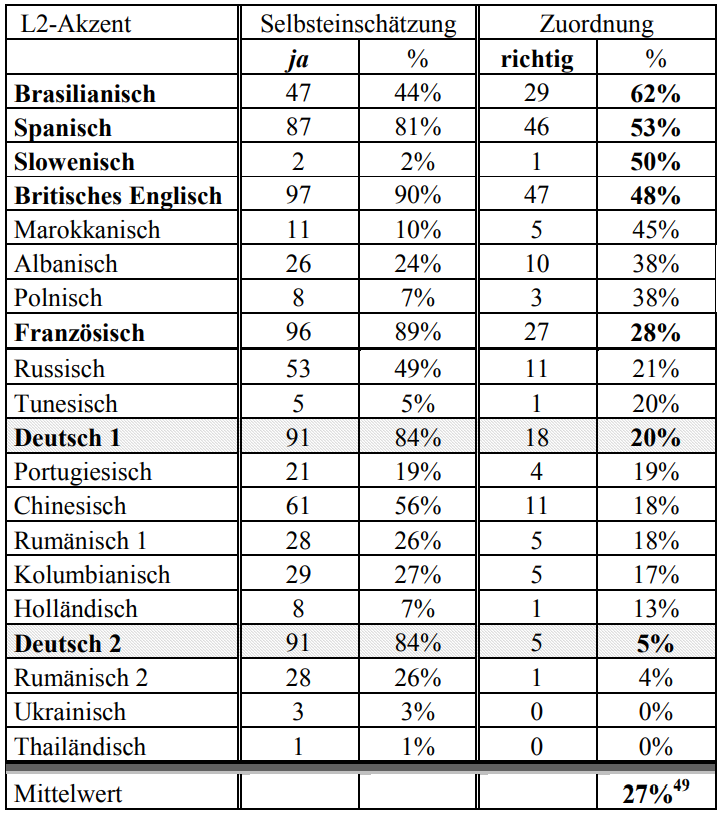
Divergenz von positiver Selbsteinschätzung und Perzeptionsleistung; n=108 (Matzinger2015, 68)
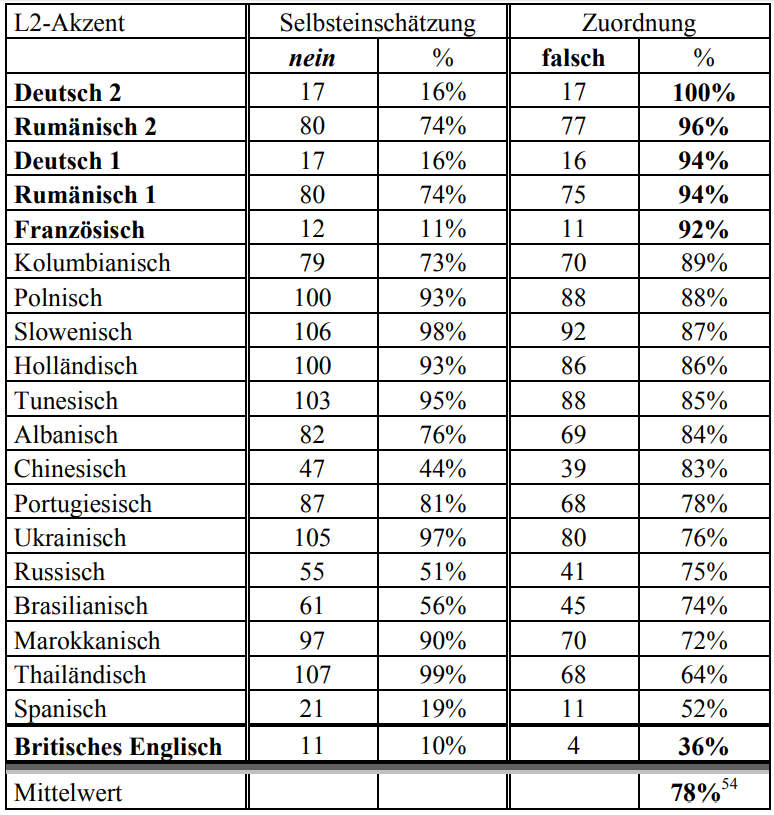
Divergenz von negativer Selbsteinschätzung und Perzeptionsleistung; n=108 (Matzinger2015, 70)
Es zeigt sich in den beiden folgenden Tabellen
- wie unzuverlässig die mentalen Repräsentationen sind, denn sie weichen vor allem im Fall vermeintlich positiver Erkennfähigkeit oft extrem von der tatsächlichen Perzepionsleistung ab (speziell im Hinblick auf das Deutsche, Britische Englisch, Französische und Spanische);
- wie wenig die Repräsentationen und die Perzeptionsleistungen mit der tatsächlichen Präsenz der L2-Sprecher korrelieren:
"Erstaunlich ist, dass L2-Akzente mit hoher Präsenz in Italien, wie beispielsweise Rumänisch (Ausländeranteil 21,2%), Albanisch (Ausländeranteil 10,6%) und Marokkanisch (Ausländeranteil 9,9%) erst in der unteren Hälfte der Tabelle mit 26%, 24% und 10% auftauchen. Anzunehmen wäre, dass die Probanden genau von diesen L2-Akzenten mentale Repräsentationen besitzen, weil sie häufiger mit ihnen in Kontakt kommen als mit anderen L2-Akzenten." (Matzinger 2015, 66f.)