L1 interferierte lautliche Merkmale beim Italienischerwerb deutscher Lerner
|
|
1. Einleitung: Gegenstand und Aufbau der Arbeit
L’accent du pays où l’on est né demeure dans l’esprit et dans le coeur, comme dans le langage.
– François de La Rochefoucauld
Diese Worte von François de La Rochefoucauld besagen, dass der Akzent eines Landes, und damit auch der einer jeden Person, im Geiste und im Herzen mit sich getragen wird und auch in der Sprache selbst wiedergefunden werden kann. Dass der Akzent des Heimatlandes vor allem in einer Fremdsprache vorgefunden werden kann, können auch Fremdsprachenlerner bestätigen, die vor der Herausforderung stehen, eine neue Sprache zu erlernen und sich neue lautliche Gewohnheiten ebendieser anzueignen. Zum Erwerb einer Fremdsprache gehört nämlich nicht nur das Erlernen und die korrekte Anwendung der Grammatik, sondern auch die Adaption ihrer Prosodie und Aussprache. Das Ziel vieler Fremdsprachenlerner ist es, sich in einer neuen Sprache verständigen zu können, etwas über die Bräuche und Sitten eines Landes zu erfahren und sich im Ausland ohne große Kommunikationsprobleme bewegen zu können. Mit der Dauer des Fremdsprachenerwerbs steigen aber oft die Ziele der Lerner und es wird nicht nur mehr der Wunsch geäußert, sich im Land der Wahl lediglich verständigen zu können, sondern vielmehr fließend eine Sprache zu sprechen und nicht mehr als Ausländer anhand der Aussprache erkannt zu werden. Jeder Muttersprachler würde bei der Äußerung eines solchen Wunsches vermutlich sagen, dass ein gewisser Akzent immer wahrgenommen werden könne und es jahrzehntelanger Übung bedürfe, um diesem Ziel nahe zu kommen. Ob dies stimmt, soll unter anderem in dieser Arbeit untersucht werden.
Im Fokus dieser Arbeit stehen Interferenzen bei lautlichen Merkmalen im Italienischen, die bei dessen Erwerb durch die Muttersprache Deutsch entstehen. Ziel dieser Arbeit ist es, zu ermitteln, anhand welcher lautlicher Merkmale deutsche Italienischlerner allgemein und speziell in Hinblick auf ihr Herkunftsland von italienischen Muttersprachlern erkannt werden und bei welchen lautlichen Merkmalen die größten Unterschiede im Vergleich zu italienischen Muttersprachlern festgestellt werden können. Um Antworten auf diese Fragen geben zu können, wurden im Zuge dieser Arbeit Sprachaufnahmen von deutschen Muttersprachlern, die Italienisch lernen oder studieren und aus Deutschland, Österreich und der Schweiz stammen, aufgenommen, analysiert und in einen Online-Perzeptionstest integriert, über welchen italienische Muttersprachler Aussagen darüber treffen konnten, ob sie Unterschiede in der Aussprache der deutschen Italienischlerner feststellen können und falls ja, wo ebendiese Unterschiede in der Aussprache der deutschen Sprecher vorzufinden sind. Gleichzeitig sollten die italienischen Muttersprachler bei Bearbeitung des Perzeptionstests versuchen, die deutschen Sprecher ihrem Herkunftsland zuzuordnen.
Für den Aufbau dieser empirischen Studie, deren Konzeption und Durchführung im Laufe dieser Arbeit in detaillierter Weise beschrieben und erläutert werden wird, wurde auf Wissen aus den Bereichen Fremdsprachenerwerb, Varietätenlinguistik, Phonetik und Phonologie sowie Perzeptive Linguistik zurückgegriffen. Diese linguistischen Disziplinen bilden die Basis der späteren empirischen Untersuchung und stellen aus diesem Grund auch den theoretischen Hintergrund dieser Arbeit dar, der im Vorfeld behandelt werden soll. Da sich die spätere empirische Untersuchung nicht nur mit Sprechern aus Deutschland, sondern auch mit Sprechern aus Österreich und der Schweiz beschäftigt, wird im Kapitel über den Fremdsprachenerwerb, das den Einstieg in den theoretischen Hintergrund bildet, kurz über den Erwerb von Fremdsprachen in dem jeweiligen Schulsystem gesprochen werden und darauf eingegangen werden, wie verschiedene demographische Merkmale der Lerner und der Zeitpunkt des Fremdsprachenerwerbs Einfluss auf Interferenzen in der zu erlernenden Fremdsprache nehmen können. Die Erkenntnisse dieses Kapitels werden dann für die Erstellung des Fragebogens, der bei der Aufnahme der Audiodateien den Probanden vorgelegt und ebenfalls für die Auswertung der Daten herangezogen werden wird, verwendet werden. Im Anschluss daran wird auf die Plurizentrizität der deutschen Sprache eingegangen werden und im Zuge dessen erläutert werden, warum die Länder Deutschland, Österreich und Schweiz für die folgende empirische Studie über L1 interferierte lautliche Merkmale beim Italienischerwerb deutscher Lerner ausgewählt wurden. Diese Ausführungen werden in den folgenden Kapiteln, die sich sowohl mit dem Lautsystem der deutschen Sprache als auch mit dem Lautsystem der italienischen Sprache beschäftigen, zusätzlich vertieft werden. Im Vordergrund wird dabei die Darstellung und Erläuterung der zwei Lautsysteme stehen, im Zuge derer explizit auf die Vokal- und Konsonantenrealisation im Deutschen und Italienischen eingegangen werden wird. Dabei wird allerdings nicht nur auf Differenzen zwischen dem deutschen und italienischen Lautsystem eingegangen, sondern auch darüber diskutiert werden, zu welchen lautlichen Interferenzen es in welchen deutschsprachigen Ländern kommen könnte und welche lautlichen Differenzen bereits in der deutschen Sprache zwischen Deutschland, Österreich und der Schweiz festgestellt werden können. Den Abschluss des theoretischen Hintergrundes wird ein Einblick in die Perzeptive Linguistik bilden, der die Vorteile eines perzeptiven Vorgehens darstellen soll und der außerdem darüber aufklären wird, warum ein perzeptiver Ansatz für diese empirische Untersuchung gewählt wurde.
Nachdem die theoretische Basis für die empirische Untersuchung geschaffen wurde, wird in den folgenden Kapiteln zunächst die Konzeption und Durchführung der Sprachaufnahmen erläutert werden, zu denen die Erstellung der Wortliste und der Trägersätze, die Auswahl der Sprechbedingung sowie der deutschsprachigen Probanden und die Durchführung der Sprachaufnahmen an sich zählt. Daraufhin wird außerdem auf die genaue Konzeption und Durchführung des Online-Perzeptionstests eingegangen werden, dessen Auswertung den Kern der Analyse darstellen wird. Die Komplikationen, die während der Durchführung des Online-Perzeptionstests entstanden sind, werden ebenfalls diskutiert und mit den ermittelten Ergebnissen in Verbindung gebracht werden. Die Gesamtauswertung des Online-Perzeptionstests wird sich zum einen in eine Analyse der perzipierten lautlichen Differenzen, die sich in erster Linie auf die Grapheme stützt, die im Zuge des Perzeptionstests ausgewählt werden konnten, gliedern und zum anderen in eine detaillierte Darstellung der Länderzuordnung, die zeigen soll, ob italienische Muttersprachler deutschsprachige Sprecher anhand lautlicher Merkmale erkennen, unterscheiden und ihrem Herkunftsland zuweisen können. Im Anschluss an die Auswertung des Online-Perzeptionstests werden die am häufigsten markierten Grapheme nochmals einer Analyse mit Praat unterzogen werden, die sprecherspezifisch gestaltet sein wird und gezielt Aufschlüsse darüber geben soll, bei welchen Probanden und bei welchen Wörtern welche lautlichen Interferenzen und Realisationen von Lauten festgestellt werden können. Den Abschluss dieser Arbeit wird ein Vergleich und die Interpretation der gewonnenen Ergebnisse aus dem Online-Perzeptionstest und der linguistischen Analyse der Sprachaufnahmen darstellen. Neben der Zusammenfassung der Ergebnisse und der Beantwortung der Eingangsfragen sowie der aufgestellten Hypothesen, werden auch eine kurze Methodenkritik sowie Ausblicke auf weitere Forschungsmöglichkeiten gegeben werden.
Wendet man sich dem aktuellen Forschungsstand zu, ist zu sehen, dass zwar schon seit längerer Zeit Studien im Bereich des Fremdsprachenerwerbs, die sich mit L1 interferierten Merkmalen beschäftigen, wie beispielsweise die Studie von Bhela (1999), die sich in erster Linie mit Interferenzen in Hinblick auf syntaktische Strukturen befasst, existieren und auch Studien vorliegen, die sich mit den sprachlichen Unterschieden von deutschen Sprechern aus Deutschland, Österreich und der Schweiz auseinandersetzen, wie unter anderem die Studie von Ulbrich (2002), die sich mit der Intonation deutscher Sprecher beschäftigt, jedoch Studien zu L1 interferierten lautlichen Merkmalen beim Italienischerwerb deutscher Sprecher noch nicht vorzufinden sind und aus diesem Grund Daten zu ebendiesem Forschungsthema erhoben werden sollen.
Nichtsdestotrotz können ähnliche Studien mit Blick auf andere Sprachen, wie beispielsweise Französisch oder Deutsch, vorgefunden werden, die bereits Einblicke in L1 interferierte lautliche Merkmale bieten. Eine vergleichbare Studie wurde beispielsweise von Gärtig/Rocco (2018) konzipiert, die im Zuge ihres soziophonetischen Projekts Salzburg-Triest Untersuchungen zur L1- und L2-Phonetik und -Phonologie junger italienischer Deutschlerner durchgeführt haben. Es handelt sich in diesem Fall um eine Studie, die den Fremdsprachenerwerb des Deutschen von italienischen Muttersprachlern aufzeigt, ebenfalls regionale phonetische Interferenzen von Lernern in einer Fremdsprache analysiert und zudem Aussagen über die Perzeption ebendieser trifft. In der empirischen Untersuchung von Gärtig/Rocco (2018) stehen neben allgemeinen italienischen Interferenzen also auch spezielle regionale Interferenzen in Hinblick auf die deutsche Sprache sowie Perzeptionsexperimente, die unter anderem Aufschluss über den Zusammenhang von Bewertungen der Aussprache der Fremdsprachenlerner und Einschätzungen der Sprachkompetenz der Lerner oder Attribuierung von sozialen Eigenschaften ebenjener geben sollen, im Vordergrund (vgl. Gärtig/Rocco 2018, 118-119). Die Studie von Gärtig/Rocco zeigt, dass die Frage nach L1 interferierten lautlichen Merkmalen in einer Fremdsprache in der derzeitigen Forschung sehr aktuell ist und verschiedenste Herangehensweisen in Hinblick auf die Beantwortung der zahlreichen Fragen, die sich in Bezug auf interferierte Merkmale in einer Fremdsprache stellen, existieren.
Überdies haben sich Pustka/Meisenburg (2017) mit deutschen Lernern und ihrer Aussprache des Französischen beschäftigt und herausgefunden, dass deutsche Französischlerner unter anderem Schwierigkeiten bei der Realisation von nasalen Vokalen aufzeigen, bei ihnen oftmals Interferenzen in Hinblick auf den Schwa-Laut festgestellt werden können und die Phoneme /t/, /p/ sowie /k/, die im Deutschen vorwiegend vor initialen Vokalen aspiriert ausgesprochen werden, im Französischen ebenfalls von einer Aspiration begleitet werden (vgl. Pustka/Meisenburg 2017, 133-134). Diese Untersuchung von Pustka/Meisenburg (2017) geben erste Hinweise auf Interferenzerscheinungen, die auch bei deutschen Italienischlernern auftreten könnten. Ob sich diese Beobachtungen und Interferenzen, die sich auf deutsche Lerner der französischen Sprache beziehen, aber tatsächlich auch in Bezug auf deutsche Italienischlerner feststellen lassen können, wird die spätere empirische Untersuchung zeigen.
Diese Arbeit knüpft also an unterschiedliche Studien an, die sich bereits auf die ein oder andere Weise mit L1 interferierten lautlichen Merkmalen in einer Fremdsprache beschäftigt haben. Die Originalität dieser Arbeit liegt in der Analyse L1 interferierter lautlicher Merkmale beim Italienischerwerb deutscher Lerner, die aus Deutschland, Österreich und der Schweiz stammen und demzufolge nicht nur allgemeine deutsche Interferenzen im Italienischen abbilden, sondern auch spezielle regionale Interferenzen aufzeigen werden. Durch den gewählten perzeptiv-linguistischen Ansatz werden zudem Aussagen über den Italienischerwerb deutscher Lerner getroffen werden können, die nicht nur auf Analysen von Sprachaufnahmen beruhen, sondern darüber hinaus die Wahrnehmung der italienischen Muttersprachler selbst miteinbeziehen.
2. Theoretischer Hintergrund
Zu Beginn dieser Arbeit soll über den theoretischen Hintergrund und die Theorien gesprochen werden, die die Basis der späteren empirischen Untersuchung bilden. Anfänglich wird deswegen auf den Fremdsprachenerwerb an sich eingegangen und diskutiert werden, welche Möglichkeiten des Fremdsprachenerwerbs in den deutschsprachigen Ländern Deutschland, Österreich und der Schweiz existieren, welche Vorteile und Nachteile in Hinblick auf das Alter der Fremdsprachenlerner bestehen und welche demographisch unabhängigen Faktoren die deutschsprachigen Italienischlerner in ihrer Aussprache beeinflussen.
Im Anschluss daran wird zudem auf die Plurizentrizität der deutschen Sprache eingegangen und aufgezeigt werden, welche Eigenschaften der unterschiedlichen Variationen der deutschen Sprache auf die Probanden einwirken und welche Auswirkungen diese auf die Aussprache der Sprecher der Länder Deutschland, Österreich und der Schweiz haben könnten. Um diese Auswirkungen später auf phonetischer Ebene untersuchen zu können, wird außerdem das deutsche sowie das italienische Lautsystem beschrieben und erläutert werden. Die Frage, inwieweit sich die Vokal- und Konsonantenrealisation zum einen innerhalb der deutschen Sprache und zum anderen im Vergleich zur italienischen Sprache unterscheidet, wird dabei im Vordergrund stehen und soll erste Hinweise darauf geben, welche phonetischen Unterschiede in der Aussprache der aufzunehmenden deutschsprachigen Italienischlerner auftreten könnten.
2.1. Fremdsprachenerwerb
Fremdsprachen sind ein wichtiger Bestandteil unserer heutigen internationalen Gesellschaft und werden deswegen bereits spätestens ab der Grundschule gelehrt. Kinder in Deutschland kommen so schon in frühen Jahren in Kontakt mit den Fremdsprachen Englisch oder Französisch und auf weiterführenden Schulen wird später außerdem die Möglichkeit geboten, weitere Sprachen, wie beispielsweise Spanisch oder Italienisch, zu erlernen (vgl. Krings 2016, 23-24). In Österreich wird ebenfalls ab der ersten Schulstufe eine lebende Fremdsprache, darunter beispielsweise Englisch oder Italienisch sowie Kroatisch oder Tschechisch, in den Schulunterricht eingebunden und auch auf den weiterführenden Schulen werden die Fremdsprachenkenntnisse der Schüler weiter ausgebaut (vgl. Bundesministerium für Bildung, Wissenschaft und Forschung 2018). Diesen frühzeitigen Erwerb einer Fremdsprache kann man auch in der polyglotten Schweiz beobachten, die in einigen Kantonen sogar einen zweisprachigen bzw. immersiven Unterricht anbietet (vgl. Schweizerische Konferenz der kantonalen Erziehungsdirektoren 2018).
Der Fremdsprachenerwerb kann als essenziell angesehen werden, wenn es darum geht, ein Land, seine Bewohner und seine Kultur zu verstehen, da die Sprache die Kultur eines Landes widerspiegelt und man durch den Erwerb einer Fremdsprache Konzepte verstehen kann, die in einer anderen Mentalität vorhanden sind. Wichtig bei der Diskussion um Fremdsprachen sind vor allem klare Definitionen der Begriffe Muttersprache, Zweitsprache und Fremdsprache. Als Muttersprache oder L1 einer Person, wird diejenige Sprache aufgefasst, die in der Kindheit zuerst erlernt, in der Familie gesprochen und für die erstmalige Sozialisation sowie für die Entwicklung des Denkens herangezogen wird. Aus soziologischer Sicht muss die Muttersprache nicht der Nationalsprache des Landes entsprechen, aus dem eine Person stammt, sondern kann beispielsweise auch einer regionalen Varietät einer Sprache entsprechen, die mehr oder weniger weit von der offiziellen Sprache des Herkunftslandes entfernt ist (vgl. Luise 2006, 42).
Die Zweitsprache bezeichnet hingegen normalerweise eine Sprache, die zwar nach der Muttersprache erlernt wird, aber Verwendung im Geburtsland findet, wohingegen der Begriff Fremdsprache für eine Sprache verwendet wird, die vor allem in der Schule oder in einer anderen Lehrinstitution vermittelt wird und im alltägliche Leben keine direkte Verwendung findet (vgl. Diadori 2011, XIII & Luise 2006, 42-43). Folglich wird im weiteren Verlauf dieser Arbeit das Italienische als Fremdsprache bezeichnet werden, sofern Bezug auf deutsche Lerner und ihren Italienischerwerb genommen wird, und der Begriff Muttersprache nach seiner erbrachten Definition Verwendung finden.
Es wird viel darüber diskutiert, wann der optimale Zeitpunkt für das Erlernen einer Fremdsprache ist, und tatsächlich können sowohl bei jüngeren als auch bei älteren Lernern positive sowie negative Aspekte in Hinblick auf den Fremdsprachenerwerb beobachtet werden (vgl. Vogel/Vogel 1975, 38-40). Während jüngere Lerner beispielsweise Vorteile in Bezug auf die phonische Repräsentation haben und intuitiv Regeln auf Ebene der Syntax und Morphologie erfassen können, zeigen ältere Lerner unter anderem häufig eine höhere lexikalische Differenzierbarkeit auf und besitzen eine höhere kognitive Kontrolle, die zum Beispiel hilfreich bei der Selbstkorrektur von Fehlern oder der Vermeidung von Interferenzen sein kann (vgl. Vogel/Vogel 1975, 39). Nachteile können bei den jüngeren Lernern hingegen in Zusammenhang mit der kognitiven Kontrolle konstatiert werden, die häufig zu Interferenzen führt, und bei den älteren Lernern können, im Gegensatz zu den jüngeren Lernern, oftmals Schwierigkeiten bei der phonischen Repräsentation von Fremdwörtern beobachtet werden (vgl. Vogel/Vogel 1975, 39). Wann eine Person entscheidet, eine Fremdsprache zu erlernen, ist demnach nicht entscheidend für den Lernerfolg, da der Lerner lediglich vor unterschiedliche Probleme gestellt wird. Dennoch kann in Hinblick auf die phonische Repräsentation von Fremdwörtern davon ausgegangen werden, dass jüngere Lerner diese schneller erlernen und demzufolge vermutlich häufiger eine authentische phonische Wiedergabe von Fremdwörtern erkennen lassen, als Personen, die in späteren Jahren eine Fremdsprache erlernen.
Der erfolgreiche Erwerb einer Fremdsprache hängt allerdings auch von zahlreichen weiteren Faktoren ab, die einerseits den äußeren Rahmen betreffen, wie beispielsweise die Art des Unterrichts, die Lehrmaterialien sowie die Qualifikation und Motivation der Lehrer, und andererseits persönliche Merkmale, beginnend bei Alter und Auffassungsgabe der Lerner bis hin zu ihrer Frustrationstoleranz, ihrer Aufgeschlossenheit, ihrem Ehrgeiz und Eigenschaften wie Schüchternheit oder Versagensängsten (vgl. Krings 2016, 47).
Wirft man einen genaueren Blick auf die phonetischen und phonologischen Kompetenzen, die die Lerner erwerben müssen, kann festgestellt werden, dass die L1 der Lerner einen starken Einfluss auf ebendiese haben. Beim Erlernen einer neuen Fremdsprache müssen nämlich zunächst neue artikulatorisch-intonative Gewohnheiten etabliert werden und diese, wie auch das Wahrnehmungsvermögen und die Fähigkeit der Produktion, können je nach L1 der Sprecher leichter oder schwieriger erworben werden. Sprecher, die eine Muttersprache besitzen, die kaum oder keine prosodischen Charakteristika der zu erlernenden Sprache teilt, stoßen häufig auf große Schwierigkeiten, wohingegen Sprecher, deren Muttersprache viele Merkmale der neuen Fremdsprache teilt, Kommunikationsstrategien und prosodische Elemente leichter erlenen können (vgl. Costamagna u.a. 2010, 75-76).
Bi- oder Multilingualität spielt beim Fremdsprachenerwerb ebenfalls eine wichtige Rolle, da Sprecher mehrerer Sprachen erstens verschiedenste Charakteristika aus ihnen ableiten können und zweitens außerdem durch Studien ermittelt werden konnte, dass Personen, die bilingual oder multilingual aufwachsen, kognitive Vorteile, wie eine verbesserte Erinnerungsgabe (vgl. Brito u.a. 2015, 674-675), besitzen, durch die sie beispielsweise besser assoziieren und leichter Verknüpfungen zwischen Sprachen erstellen können (vgl. Soares De Sousa 2016, 144). Generell muss allerdings darauf geachtet werden, dass der Terminus ‚Bilingualität‘ mehrere Konzepte und Ausprägungen unter sich vereint, wie beispielsweise den bilinguismo perfetto o bilanciato, der davon ausgeht, dass das gleiche Kompetenzniveau in beiden Sprachen vorhanden ist oder den bilinguismo limitato, von dem gesprochen wird, wenn in keiner der beiden Sprachen eine funktionale linguistische Kompetenz entwickelt wurde (vgl. Luise 2006, 44-46). Im Folgenden werden die Begriffe ‚Bilingualität‘ oder ‚bilingual‘ nur in Fällen gebraucht werden, in denen die Sprecher zwei Muttersprachen besitzen, bei denen das gleiche Kompetenzniveau vorhanden ist, und es sich demnach um einen bilinguismo bilanciato handelt.
Auch Lernern, die bereits eine oder mehrere Fremdsprachen derselben Sprachfamilie erlernt haben und nicht bilingual oder multilingual aufgewachsen sind, fällt es leichter, Konzepte und prosodische Charakteristika der neuen Fremdsprache wiederzuerkennen und sich diese anzueignen (vgl. Diadori 2011, 12-13). Der Italienischerwerb könnte demnach bei Personen, die andere romanische Sprachen, wie Französisch, Spanisch, Portugiesisch und Rumänisch, als Muttersprache sprechen oder als Fremdsprache erlernt haben, schneller voranschreiten. Hinzukommend könnten Lerner, die sich andere Fremdsprachen bereits über lange Zeit aneignen und ein hohes Sprachniveau in ebendiesen aufweisen, von diesen auch in Hinblick auf die Aussprache des Italienischen beeinflusst werden. Äußerst wichtig ist in diesem Sinne auch der Kontakt der Fremdsprachenlerner mit Muttersprachlern der zu erlernenden Sprache (vgl. Diadori 2011, 13) und es kann vermutet werden, dass Lerner, die stetigen Kontakt mit Muttersprachlern ihrer Wahlfremdsprache haben, sich schneller und einfacher eine korrekte und authentische Aussprache aneignen.
Im schulischen Fremdsprachenunterricht werden laut Michel (2006) bereits frühzeitig Maßnahmen für die korrekte Artikulation von Lauten, die Satzmelodie, die Wortbetonung sowie die Bindung und den Sprechakt getroffen, da falsche Aussprachegewohnheiten im späteren Verlauf des Fremdsprachenerwerbs schwieriger korrigiert werden können und das Ziel besteht, lautliche Interferenzen durch die Muttersprache zu vermeiden (vgl. Michel 2006, 176-177). Bei Personen, die eine Fremdsprache bereits in der Schulzeit erlernt haben, könnten demnach weniger bis keine lautlichen Interferenzen bei der Aussprache ebendieser zu finden sein. Costamagna u.a. (2010) erläutert überdies, dass der gemeinsame europäische Referenzrahmen für Sprachen in Hinblick auf die phonologische Kompetenz der Lerner sogar vorsieht, dass Sprecher, die das Sprachniveau B1 im Italienischen erreicht haben, die Vokal- und Konsonantenphoneme des Italienischen, die ihnen besonders komplex erscheinen, korrekt wiedergeben und eine klare Unterscheidung zwischen geschlossenen und offenen Vokalen in der Aussprache machen können. Ab Niveau B2 wird außerdem davon ausgegangen, dass auch die dentalen Affrikate fehlerfrei realisiert werden (vgl. Costamagna u.a. 2010, 82-84). Diesen Richtlinien zufolge sollten die deutschsprachigen Italienischlerner also bereits ab einem Niveau von B1 in der italienischen Aussprache so geübt sein, dass keine lautlichen Differenzen mehr perzipiert werden können.
Zusammenfassend kann demnach gesagt werden, dass der Fremdsprachenerwerb durch viele Faktoren beeinflusst wird und auch der L2 Akzent der Lerner vermutlich nicht auf einen alleinigen Faktor zurückgeführt werden kann. Der Beginn und die Dauer des Fremdsprachenunterrichts, Vorkenntnisse anderer, zur gleichen Sprachenfamilie gehörender Sprachen, Auslandsaufenthalte, die zu einem intensiven Sprachkontakt geführt haben, und auch Bilingualität bzw. Multilingualität oder Kenntnisse eines Dialektes sind Faktoren, die starke Auswirkungen auf die Aussprache einer Fremdsprache sowie die Geschwindigkeit, mit der ebendiese erlernt wird, haben können. Aus diesem Grund werden sich diese Rahmenbedingungen in der späteren empirischen Untersuchung wiederfinden und abgefragt werden.
Die didaktische Vermittlung einer Sprache ist allerdings nur ein Teilfaktor, der die Aussprache einer Fremdsprache beeinflusst. Ein weiterer wichtiger Faktor ist die Muttersprache der Fremdsprachenlerner, die im Falle dieser empirischen Untersuchung die deutsche Sprache ist. Besonders interessant ist dabei die Tatsache, dass Deutsch nicht nur in Deutschland, sondern auch in anderen Teilen der Welt gesprochen wird und regionale Besonderheiten aufweist. Aus diesem Grund soll nun im folgenden Kapitel über die Plurizentrizität der deutschen Sprache gesprochen und die Bedeutung dieser Eigenschaft für deutschsprachige Lerner des Italienischen erklärt und erläutert werden.
2.2. Plurizentrizität der deutschen Sprache
Die deutsche Sprache besitzt in Deutschland, Österreich und Liechtenstein den Status der alleinigen Staatssprache und wird zudem in zwei weiteren Ländern, der Schweiz und Luxemburg, als Co-Staatssprache angesehen (vgl. Muhr 1993, 110). Grundsätzlich werden jene Sprachen als plurizentrisch bezeichnet, die in mehreren Ländern den Status der Amtssprache besitzen sowie unterschiedliche Standardvarietäten entwickelt haben und somit über länderspezifische, kodifizierte Normen verfügen (vgl. Kellermeier-Rehbein 2014, 22 & Schmidlin 2011, 71).
Der Begriff Amtssprache kann generell für jede Sprache herangezogen werden, die von Regierungen, Behörden und Ämtern in einem Land für die Kommunikation mit Bürgern und untereinander genutzt wird, und außerdem in die Unterkategorien ‚national‘ und ‚regional‘ unterteilt werden (vgl. Kellermeier-Rehbein 2014, 22-24). Nationale Amtssprachen gelten im gesamten Gebiet eines Staates, während regionale Amtssprachen lediglich in einer oder mehrerer Regionen eines Staates gültig sind (vgl. Kellermeier-Rehbein 2014, 24). Als Standardvarietäten gelten hingegen jene sprachlichen Erscheinungsformen, die in der öffentlichen und überregionalen Kommunikation gebraucht werden (vgl. Korhonen 2013, 102).
Eine weitere definitorische Möglichkeit in Hinblick auf die Plurizentrizität einer Sprache bietet Ammon (2017), der drei verschiedene Typen von Zentren für seine Klassifizierung der deutschen Sprache unterscheidet: Vollzentren, Halbzentren und Viertelzentren (vgl. Ammon 2017, 18-20). Nach dieser Einteilung, die auf der Neuauflage des Variantenwörterbuchs des Deutschen1 beruht, gibt es insgesamt 10 Zentren der deutschen Sprache (vgl. Ammon 2017, 18). Sowohl in Vollzentren als auch in Halbzentren gilt die deutsche Sprache als staatliche Amtssprache, wobei Vollzentren die Besonderheit aufweisen, dass sie zum einen über eigene Nachschlagewerke bzw. Sprachkodexe verfügen und zum anderen Varianten bzw. standardsprachliche Besonderheiten der deutschen Standardsprache auf allen grammatischen Ebenen gefunden werden können (vgl. Ammon 2017, 18-19). Plurizentrische Sprachen unterscheiden sich jedoch nicht nur auf der grammatischen Ebene voneinander, sondern auch die phonologische, die lexikalische, die semantische sowie die pragmatische Ebene können sprachliche Eigenheiten und Besonderheiten aufweisen (vgl. Clyne 1989, 360). Wichtig sei hierbei allerdings zu betonen, so Clyne (1989), dass Unterschiede nicht zwangsläufig auf allen Ebenen vorgefunden werden müssen (vgl. Clyne 1989, 360-361). Der Definition von Ammon (2017) zufolge zählen Deutschland, Österreich und die Schweiz somit zu den Vollzentren der deutschen Sprache, während Liechtenstein, Luxemburg, Ostbelgien und Südtirol den Halbzentren zugeordnet werden können (vgl. Ammon 2017, 18-19).
Hollmach (2007) und Korhonen (2013) beschreiben die deutsche Sprache hingegen nicht nur als plurizentrisch, sondern darüber hinaus als plurinational, da mehr als eine Nation ein eindeutiges Sprachzentrum der deutschen Sprache vorweisen kann und in ebendiesen jeweils eine ausgeformte Standardvarietät gebraucht wird (vgl. Hollmach 2007, 45-46 & Korhonen 2013, 101). Hollmach erklärt des Weiteren, dass die Nationen Deutschland, Österreich und die Schweiz über Varianten verfügen, die in einer für eine Standardvarietät typischen Situation, beispielsweise in der Öffentlichkeit, als korrekt angesehen und anerkannt werden (vgl. Hollmach 2007, 46). Auf Ebene der Standardvarietäten kann für das Deutsche im Allgemeinen die Unterscheidung zwischen Nord- und Südstandard gemacht werden, wobei der Nordstandard lediglich für die nördlichen Teile Deutschlands gilt und der Südstandard sowohl Süddeutschland als auch Österreich und die Schweiz umschließt (vgl. Korhonen 2013, 102).
Wirft man einen Blick auf die Sprachkodizes, ist zu sehen, dass der Sprachkodex in Deutschland durch die Dudenbände festgehalten wird, während dies sowohl in Österreich als auch in der Schweiz über Wörterbücher, genauer gesagt durch das Österreichische Wörterbuch und das Schweizer Wörterbuch, passiert (vgl. Ammon 2017, 19). Der deutsche Sprachkodex genießt allerdings einen höheren Bekanntheitsgrad als seine österreichischen und schweizerischen Vertreter, was mit verschiedenen Faktoren zusammenhängt: Ein wichtiger Faktor ist dabei die Ausführlichkeit des deutschen Kodexes und ein weiterer grundlegender Faktor die Tatsache, dass er die bevölkerungsstärkste nationale Varietät beschreibt, die aufgrund ihrer numerischen Stärke auch für die Vermittlung des Deutschen als Fremdsprache präferiert wird. Die Ausführlichkeit des deutschen Sprachkodexes zeigt sich bei der Einschließung von Austriazismen und Helvetismen, wohingegen sowohl der österreichische als auch der schweizerische Sprachkodex keine spezifischen Teutonismen enthalten (vgl. Ammon 1996, 198).
Es ist also zu vermuten, dass bereits Unterschiede in Bezug auf die deutsche Sprache bei den deutschen, österreichischen und schweizerischen Sprechern vorgefunden werden können und sich diese auch in der italienischen Sprache im L2 Akzent der Fremdsprachenlerner äußern könnten. Wie stark sich die Differenzen der deutschen Sprache tatsächlich in der italienischen Sprache widerspiegeln und ob Differenzen von italienischen Muttersprachlern zwischen den deutschsprachigen Sprechern in Bezug auf ihr Herkunftsland perzipiert werden können, soll in der empirischen Untersuchung festgestellt werden.
Abschließend kann also festgehalten werden, dass die deutsche Sprache alle Bedingungen erfüllt, um als plurizentrische Sprache und sogar als plurinationale Sprache bezeichnet zu werden, da sich ihr Verbreitungsgebiet über mehrere Länder und Zentren erstreckt und diese eine nationale Variante der deutschen Sprache mit eigenen Normen vorweisen (vgl. Clyne 1989, 358). Zwar kann der größte Teil plurizentrischer Unterschiede einer Sprache auf Ebene der Lexik vorgefunden werden, doch treten auch einige Unterschiede auf Ebene der Phonologie auf (vgl. Graefen/Liedke 2012, 25 & Schmidlin 2011, 72), die besonders interessant für die empirische Untersuchung sein werden und deswegen in Hinblick auf die Plurizentrizität der deutschen Sprache und der damit verbundenen Aussprache im nächsten Kapitel erläutert werden sollen. Im Vordergrund werden dabei die Fragen stehen, welche Besonderheiten im Lautsystem der deutschen Sprache durch die verschiedenen existierenden Normen vorgefunden werden können und inwiefern das deutsche Lautsystem die Aussprache deutscher Italienischlerner bedingt. Des Weiteren sollen erste Vermutungen hinsichtlich der Schwierigkeiten bei der Aussprache von italienischen Wörtern aufgestellt werden und darüber diskutiert werden, welche lautlichen Differenzen zwischen deutschen, österreichischen und schweizerischen Sprechern vorgefunden werden könnten.
2.3. Lautsystem der deutschen Sprache
Das phonologische System einer Sprache ist gleichsam ein Sieb, durch welches alles Gesprochene durchgelassen wird. Haften bleiben nur jene lautlichen Merkmale, die für die Individualität der Phoneme relevant sind. Alles übrige fällt hinunter in ein anderes Sieb, wo die appellrelevanten lautlichen Merkmale haften bleiben, noch tiefer liegt wiederum ein Sieb, an dem die für die Kundgabe des Sprechers charakteristischen Züge des Sprechschalles abgesiebt werden usw. Jeder Mensch gewöhnt sich von Kindheit an, das Gesprochene so zu analysieren, und diese Analyse geschieht ganz automatisch und unbewusst. Dabei ist aber das System der ‚Siebe‘, das eine solche Analyse ermöglicht, in jeder Sprache anders gebaut. Der Mensch eignet sich das System seiner Muttersprache an.
Das Zitat von Trubetzkoy (1962) verdeutlicht, dass die Beschäftigung mit der Phonologie etwas Alltägliches ist und man, um eine Sprache wirklich zu kennen, ein unbewusstes Wissen über das Lautsystem ebendieser besitzen und außerdem über das Wissen verfügen muss, wie dieses beim Hören und Sprechen eingesetzt werden kann (vgl. Hengartner/Niederhauser 1993, 44). Normalerweise variiert die Anzahl der Laute in einem Lautsystem einer Sprache zwischen 20 und 40 Sprachlauten und es kann gesagt werden, dass nur ausgewählte Laute für jedes Lautsystem einer Sprache als typisch angesehen werden und relevant sind. Diese Tatsache fällt beispielsweise sehr häufig beim Erlernen einer neuen Fremdsprache auf, wenn die korrekte Aussprache eines Lautes zum Problem wird (vgl. Hengartner/Niederhauser 1993, 42).
Das Lautsystem der deutschen Sprache ist vielfältig und unterscheidet sich nicht nur nach Land, sondern innerhalb eines Landes auch nach Region. Der Fokus dieser Arbeit liegt auf Sprechern der Städte München, Wien und Zürich, was bedeutet, dass nicht nur die Länder Deutschland, Österreich und die Schweiz in Hinblick auf L1 interferierte lautliche Merkmale beim Italienischerwerb betrachtet werden sollen, sondern auch lautliche Besonderheiten der ausgewählten Regionen Erwähnung finden werden. Nichtsdestotrotz wird für die Beschreibung und Erläuterung des deutschen Lautsystems auf die deutsche Standardaussprache zurückgegriffen werden und ebendiese als Ausgangspunkt für Variationen innerhalb des deutschen Lautsystems angesehen werden.
Die deutsche Standardsprache wird auch für Unterricht und Lehre herangezogen und zeichnet sich in erster Linie durch ihre Überregionalität und ihre landschaftlich unbeeinflusste Lautung aus (vgl. Rues u.a. 2009, 21-23). Sie kann in jeder Kommunikationssituation verwendet werden, stellt die Ausspracheform mit dem höchsten sozialen Prestige dar und erscheint im Gespräch unauffällig (vgl. Rues u.a. 2009, 23-24). Diese Norm wird unter anderem durch die Massenmedien vermittelt und bildet die Grundlage, um erstens eine standardsprachliche Aussprache zu erkennen und zweitens andere Ausspracheformen als unangemessen einzustufen. Ein Sprecher spricht folglich Standarddeutsch, wenn seine Aussprache nicht erkennen lässt, aus welcher deutschen Region er stammt (vgl. Rues u.a. 2009, 21-24).
Im Folgenden soll zunächst auf die Vokalrealisation und Konsonantenrealisation der deutschen Standardsprache eingegangen werden, wobei zusätzliche Bemerkungen in Hinblick auf regionale Besonderheiten der Länder Deutschland, Österreich und der Schweiz sowie der Städte München, Wien und Zürich in die Beschreibungen einfließen werden. Im Anschluss soll außerdem ein Blick auf das italienische Lautsystem und seine Besonderheiten geworfen werden, um schließlich, mithilfe der Beschreibung und Erläuterung der beiden Lautsysteme, eine Grundlage für die Konzeption der benötigten Wortliste zu schaffen.
2.3.1. Vokalrealisation deutscher Sprecher
Die Aussprache der deutschen Vokale spiegelt sich oft in ihrer Schreibung wider, doch können nicht alle Vokale mit Sicherheit aus der Rechtschreibung erschlossen werden, da das System in sich nicht geschlossen ist und Ausnahmeerscheinungen aufweist (vgl. Siebs 1969, 49). Phonologisch betrachtet zählen die Vokale zu den stimmhaften Lauten (vgl. Siebs 1969, 19) und können für die deutsche Sprache wie folgt dargestellt werden:
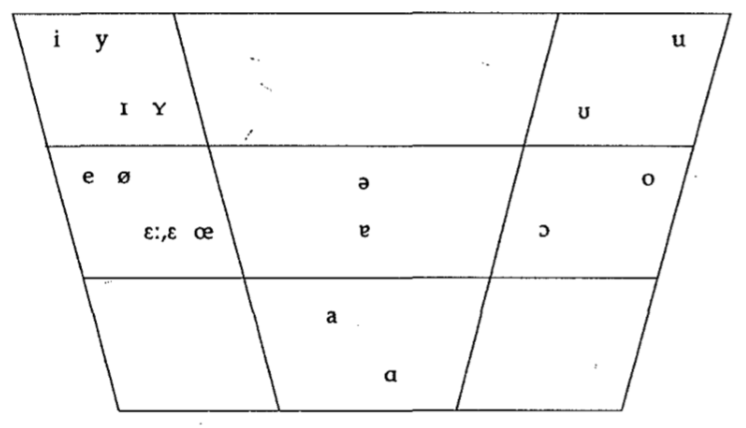
Noak (2010) stellt in Bezug auf das deutsche Vokalsystem fest, dass in der Fachliteratur über die Anzahl der Vokale im deutschen Lautsystem keine Einigkeit herrscht und je nach Betrachtungsweise von 15 oder 16 vokalischen Phonen die Rede ist (vgl. Noak 2010, 34). Diese Diskrepanz hängt mit der Tatsache zusammen, dass manche Autoren, wie unter anderem Noak (2010), den Reduktionsvokal [ɐ] in ihre Zählung mit aufnehmen und andere, wie beispielsweise Maturi (2009) oder Ternes (2012), sich gegen ebendiese Aufnahme entscheiden. In dieser Arbeit sollen die Reduktionsvokale [ɐ] und [ə] aber ebenfalls unter Betrachtung stehen, weswegen im Folgenden immer von 16 Vokalphonen ausgegangen werden wird.
Generell lassen sich die Vokale des deutschen Lautsystems anhand von drei Merkmalspaaren, die in Opposition zueinander stehen, untergliedern. So können die dem deutschen Lautsystem angehörigen Vokale entweder durch ihre Dauer, ihre Qualität oder durch ihre Anschlussopposition sowie ihren Silbenschnitt unterschieden werden. Im ersten Fall wird demnach eine Unterscheidung in kurze und lange Vokale vorgenommen, wohingegen im zweiten Fall auf geschlossene und offene bzw. gespannte und ungespannte Vokale eingegangen wird und im dritten Fall der Anschluss der Vokale im Vordergrund steht (vgl. Noak 2010, 36). In diesem Kapitel sollen die vokalischen Phone des deutschen Lautsystems einerseits in Hinblick auf ihre Dauer und andererseits bezüglich ihres Gespanntheitsgrades betrachtet werden, da vor allem diese Eigenschaften, je nach Region der deutschen Sprecher, variieren.
Zu den langen Vokalen zählen [iː, eː, aː, oː, uː] und [yː, øː], wohingegen [ɪ, ɛ, ɑ, ɔ, ʊ] sowie [ʏ, œ] den kurzen Vokalen zugeordnet werden können (vgl. Maturi 2009, 130). Wirft man einen Blick in die Schweiz, kann beobachtet werden, dass sich die Vokale im schweizerischen Standarddeutsch in Hinblick auf die deutsche Standardsprache in erster Linie durch ihre Länge unterscheiden. Vokale, die in der deutschen Standardsprache häufig lang gesprochen werden, werden in der Schweiz kurz ausgesprochen und kurze Vokale der deutschen Standardsprache werden in der Schweiz wiederum häufig als lange Vokale realisiert (vgl. Rash 1998, 156). Diese Beobachtung legt die Vermutung nahe, dass die Länge der von Schweizern ausgesprochenen Vokale auch vom Italienischen abweichen könnte und sich Schweizer dadurch von Sprechern aus Deutschland und Österreich abgrenzen könnten. Ansonsten sollte angemerkt werden, dass maßgebliche Unterschiede im Intonationsverhalten der Schweizer im Vergleich zu Sprechern aus Deutschland und Österreich festgestellt werden können und Wortakzente ebenfalls anders gesetzt werden (vgl. Rash 1998, 155-156). Der typisch deutsche Akzent im Italienischen kann hingegen oftmals auf die Opposition von langen und kurzen Vokalen zurückgeführt werden (vgl. Michel 2006, 184) und entsteht, so erklärt Michel (2006, 184), vorwiegend „durch die unbewusste Übertragung von phonetischen und phonologischen Charakteristika des Deutschen auf die romanischen Sprachen“.
Wendet man sich der Differenzierung von offenen und geschlossenen bzw. gespannten und ungespannten Vokalen zu, kann festgestellt werden, dass der Schwa-Laut [ə], der auch als Reduktionsvokal oder Zentralvokal bezeichnet wird, da er im Zentrum des Mundraums mit neutraler Zungenstellung gebildet wird (vgl. Hengartner/Niederhauser 1993, 37), typisch für deutschsprachige Sprecher ist, eine isolierte Stellung im deutschen Lautsystem einnimmt und, im Gegensatz zu allen anderen langen und kurzen Vokalen, nur in einer unbetonten Vor- oder Endsilbe vorgefunden werden kann (vgl. Graefen/Liedke 2012, 214). Allerdings wird der Schwa-Laut oftmals nicht zum Vokalphonemsystem des Deutschen gezählt, da sich dieser meist von den vokalischen Phonemen /e/ oder /e:/ ableiten lässt (vgl. Hengartner/Niederhauser 1993, 51). In Hinblick auf den Öffnungsgrad der Vokale ist weiterhin interessant zu beobachten, dass das Phon [ɛː] in der Aussprache der meisten Norddeutschen nicht vorkommt und zum Beispiel Wörter wie Mädchen oder Käse mit dem Phonem /eː/ realisiert werden (vgl. Hengartner/Niederhauser 1993, 50). In Süddeutschland, und somit auch in der bayerischen Hauptstadt München, kann das [ɛː] aber in der Aussprache vorgefunden werden und bildet einen wesentlichen Bestandteil der süddeutschen Sprache (vgl. Canepari 2014, 213-220), wodurch vermutet werden kann, dass Süddeutsche mit der Differenzierung des [e] und [ɛ] im Italienischen weniger Probleme als norddeutsche Italienischlerner haben könnten, da diese Laute zu ihrem muttersprachlichen Sprachrepertoire gehören und tagtäglich verwendet werden. Des Weiteren konnten auch bei den österreichischen Vokalen Besonderheiten bezüglich der Öffnungsgrade der kurzen Vokale beobachtet werden und zudem konstatiert werden, dass das österreichische Vokalsystem durch das Fehlen des Phonems /ɛ/ gekennzeichnet ist (vgl. Muhr 2017, 33). Bürkle (1993) führt außerdem an, dass es im Österreichischen bei allen drei e-Vokalen zu „Überlappungserscheinungen“ kommt und unterschiedlichste Variationen des Öffnungsgrades bei kurzen und langen e-Vokalen vorzufinden sind (vgl. Bürkle 1993, 60). Iivonen (1996) beschreibt die Phonemvokale /i:/ und /e:/ im wienerischen Deutsch darüber hinaus als „besonders geschlossen“ (vgl. Iivonen 1996, 228). Aus diesem Grund kann vermutet werden, dass österreichische Sprecher im Italienischen eine geringere Anzahl des Phonems /ɛ/ aufweisen werden, da es im österreichischen Deutsch nicht verwendet wird, und gleichzeitig auch Unterschiede in Hinblick auf die Aussprache des Phonems /e/ aufgrund seines Öffnungsgrades von Italienern wahrgenommen werden könnten.
Alles in allem kann in Bezug auf die Vokalrealisation also festgehalten werden, dass Unterschiede zwischen den deutschen, österreichischen und schweizerischen Sprechern bereits in der deutschen Sprache in Hinblick auf die Länge der Vokale sowie ihren Öffnungsgrad bestehen und sich diese Differenzen im Italienischen widerspiegeln könnten.
2.3.2. Konsonantenrealisation deutscher Sprecher
Das deutsche Konsonantensystem ist ebenfalls variabel und weist etwa 19 Konsonanten auf, unter denen sich sowohl stimmhafte als auch stimmlose Laute befinden. Die Variabilität des Konsonantensystems kann dabei auf Konsonanten anderer Sprachen, die ihren Weg in die deutsche Sprache gefunden haben, zurückgeführt werden (vgl. Graefen/Liedke 2012, 215).
Um die Beziehung zwischen Laut und Buchstabe der Konsonanten zu beschreiben, kann man diese unter anderem in Plosive [p, b, t, d, k, g, ʔ], Frikative [f, v, s, z, ʃ, ʒ, ç, x, ʁ, h], Nasale [m, n, ŋ], Approximanten [j, l], Vibranten [r, ʀ] und Affrikate [pf, ts, ʧ, dʒ] gruppieren (vgl. Rues u.a. 2014, 16 & Pittner 2013, 20-21).
| bi- labial |
labio- dental |
alveolar | post- alveolar |
palatal | velar | uvular | glottal | |
| Plosive | p b | t d | k g | ʔ | ||||
| Frikative | f v | s z | ʃ ʒ | ç j | x | χ ʁ | h | |
| Nasale | m | n | ŋ | |||||
| Laterale | l | |||||||
| Vibranten | r | R |
Tabelle 1: Konsonanten im Deutschen nach Pittner (2013, 22)
Die Plosive der deutschen Sprache zeigen allgemein eine Opposition in Hinblick auf ihre Gespanntheit (fortis) und Ungespanntheit (lenis) auf (vgl. Rues u.a. 2014, 16). Vor betonten Silben kann bei Plosiven eine Aspiration am Anfang ebendieser festgestellt werden, wohingegen bei unbetonten Silben normalerweise keine Aspiration, weder am Wortanfang noch am Wortende, stattfindet (vgl. Canepari 2014, 60). Die Aspiration kann als redundantes Merkmal der deutschen Sprache eingestuft werden, da sie lediglich die Möglichkeit zur Unterscheidung von Allophonen, aber nicht von Phonemen, bietet (vgl. Hengartner/Niederhauser 1993, 46). Dennoch unterscheidet die Aspiration beispielsweise deutsche von italienischen Sprechern und soll deswegen als phonetisches Merkmal in der späteren Analyse untersucht werden. Interessant ist in Hinblick auf die Aspiration auch die Beobachtung von Canepari (2007), der darauf hinweist, dass bei süddeutschen Akzenten dagegen normalerweise keine Aspiration vorhanden ist (vgl. Canepari 2007, 109). Diese Observation trifft auch auf die Deutschschweiz zu, in der eine aspirierte Aussprache der stimmlosen Verschlusslaute [t] und [p] sogar als übertrieben und affektiert angesehen wird (vgl. Hengartner/Niederhauser 1993, 52). Süddeutsche Sprecher könnten demnach anpassungsfähiger in Bezug auf die italienische Aussprache sein, die in der Regel keine Aspiration vor stimmlosen Verschlusslauten aufweist.
Des Weiteren werden Plosive der deutschen Sprache stärker und gespannter als in anderen Sprachen ausgesprochen (vgl. Canepari 2014, 60) und können deswegen häufig beim Sprechen von Fremdsprachen wahrgenommen werden. Überdies kann den Plosiven der Glottisverschlusslaut [ʔ] zugeordnet werden, der durch das Öffnen und Schließen der Stimmritze entsteht und häufig von Sprechern unbewusst verwendet wird. Im Deutschen kann der Glottisverschlusslaut anlautend vor einem Vokal oder im Inlaut zwischen Vokalen, sofern die Silbe, die der Verschlusslaut einleitet, betont ist, vorgefunden werden (vgl. Pittner 2013, 20-21). Dieser Laut ist den romanischen Sprachen, und somit auch dem Italienischen, gänzlich unbekannt (vgl. Michel 2006, 184) und könnte deshalb zu Abweichungen in der Aussprache der deutschsprachigen Italienischlerner führen.
Auch das deutsche r besitzt einige Eigenschaften, die von der italienischen Sprache abweichen. Es kann im Standarddeutschen, je nach Stellung und Herkunft des Sprechers, unterschiedlich ausgesprochen werden und unterscheidet sich im Allgemeinen stark vom italienischen r. Während das deutsche r in der Regel uvular ausgesprochen und als /ʀ/ oder /ʁ/ realisiert wird (vgl. Rues u.a. 2014, 17), wird das italienische r üblicherweise als /r/ realisiert. Nach einem betonten Kurzvokal wird das r in der deutschen Standardsprache zudem normalerweise vokalisiert und als /ɐ/ wiedergegeben (vgl. Ammon 1995, 336). In südlichen Regionen Deutschlands, wie beispielsweise Bayern, kann aber auch ein erhöhtes Vorkommen des alveolaren r-Lautes festgestellt werden (vgl. Schrambke 2010, 54). Diese Beobachtung lässt die Vermutung zu, dass sich süddeutsche Sprecher einfacher an die italienische Aussprache in Hinblick auf das r anpassen können, da sie dieses eventuell bereits in ihrem alltäglichen Gebrauch verwenden. Wirft man einen Blick auf die deutschsprachige Schweiz, so kann in Bezug auf die Aussprache des rs festgestellt werden, dass es, im Gegensatz zur Aussprache in Deutschland, keiner Vokalisierung im Auslaut unterliegt (vgl. Bickel/Hofer 2013, 86 & Ammon 1995, 257). Die r-Varianten, die innerhalb der deutschsprachigen Schweiz vorgefunden werden können, zeigen einen häufigen Wechsel von Artikulationsart sowie -ort auf, was dazu führt, dass die Artikulationsart von alveolar bis frikativ reichen und der Artikulationsort stark apikal bis uvular sein kann (vgl. Schrambke 2010, 57). In Zürich kann in Hinblick auf die deutschsprachigen Italienischlerner erwartet werden, dass sie, da sie das r normalerweise uvular realisieren (vgl. Schrambke 2010, 57), auch den uvularen Laut /ʁ/ im Italienischen produzieren oder zumindest von der alveolaren Aussprache des italienischen Lautes /r/ abweichen werden.
Weitere Abweichungen zwischen dem deutschen und italienischen Lautsystem können bei den Nasalen und den Affrikaten vermutet werden. Im deutschen Lautsystem können die drei Nasale [m, n, ŋ] vorgefunden werden, während sich das italienische Lautsystem durch die Nasale [m, ɱ, n, ɲ, ŋ] auszeichnet. Gleichzeitig weist das italienische Lautsystem auch die Affrikate [ts, dz, tʃ, dʒ] auf, die als solche nicht alle im deutschen Lautsystem existieren. Inwiefern sich die Affrikate und die Nasale untereinander unterscheiden, soll allerdings erst im folgenden Kapitel 2.4. Lautsystem der italienischen Sprache erläutert werden.
Zusammenfassend kann für das deutsche Lautsystem also gesagt werden, dass einige typische Laute der deutschen Sprache im italienischen Lautsystem nicht vertreten sind oder standardmäßig anders ausgesprochen werden. Dazu zählen in Hinblick auf die Konsonanten unter anderem die Plosive [t, p], die im Deutschen gespannter und damit ‚härter‘ ausgesprochen werden, sowie der Vibrant [ʀ] und der Frikativ [ʁ], die beide eine uvulare Realisierung des Graphems <r> darstellen. Aber auch in Hinblick auf die Vokale des deutschen Lautsystems lassen sich Besonderheiten feststellen, wie beispielsweise die unterschiedlichen Öffnungsgerade der e- und o-Laute, die zu Interferenzen in der italienischen Sprache führen könnten. Um herauszufinden, welche Laute in der späteren empirischen Untersuchung tatsächlich im Vordergrund stehen sollen, muss allerdings ebenfalls das italienische Lautsystem beschrieben und erläutert werden.
2.4. Lautsystem der italienischen Sprache
Ebenso wie die deutsche Sprache weist auch die italienische Sprache eine hohe Vielfalt und Variation innerhalb ihres Lautsystems auf. Interessant ist dabei zu beobachten, dass es in Italien zahlreiche Dialekte und regionale Aussprachen2 gibt, die oftmals die Aussprache der Nationalsprache beeinflussen und eine neutrale Standardaussprache deswegen selten vorzufinden ist (vgl. Canepari 2007, 7-8). Dabei sei eine neutrale Standardaussprache nicht weniger natürlich als eine regionale Aussprache, so Canepari, da ebenjene vielmehr eine mangelnde Ausdrucksform der neutralen Standardaussprache darstelle (vgl. Canepari 2007, 7). Maturi (2009) erklärt im Gegensatz dazu, dass unter dem italiano standard eine normierte und abstrakte Sprache verstanden werde, die nicht die Realität widerspiegle und weder einer italienischen Region noch dem Gebrauch einer realen Person zugeordnet werden könne. Vielmehr könne diese Sprache im Theater oder unter anderen unrealistischen Bedingungen vorgefunden werden (vgl. Maturi 2009, 71-72).
Es gibt also verschiedene Ansichten, was die neutrale Standardaussprache im Italienischen betrifft, und doch soll sich im Folgenden auf ebendiese, so artifiziell sie vielleicht auch sein mag, konzentriert werden. Da in der späteren empirischen Untersuchung keine Sprachaufnahmen von Italienern gemacht werden und diese lediglich die Aussprache der deutschen Italienischlerner zu bewerten haben, wird der Blick auf die neutrale italienische Standardaussprache auch keine späteren Auswirkungen auf die Auswertung und Analyse der Sprachdaten haben.
2.4.1. Vokalrealisation italienischer Sprecher
Die italienischen Vokale können grundsätzlich in zwei große Kategorien eingeteilt werden: betonte und unbetonte Vokale (vgl. Maturi 2009, 72-75). Diese werden im Folgenden auch als vocali toniche und vocali atone bezeichnet werden und im italienischen Lautsystem durch die Diphthonge ergänzt, die eine Sequenz von zwei Vokalen innerhalb derselben Silbe darstellen (vgl. Maturi 2009, 75). Zusätzlich umfasst das italienische Lautsystem auch semivocali ‚Halbvokale‘, die durch eine engere Konstriktion als bei normalen Vokalen entstehen und häufig den Begriff Approximanten tragen (vgl. Michel 2016, 83). Generell kann gesagt werden, dass das italienische Vokalsystem zwei große Unterschiede zum deutschen Vokalsystem aufweist. Zum einen können unter den italienischen Vokalen keine Umlaute vorgefunden werden und zum anderen ist im Italienischen die Struktur der Silben ausschlaggebend für die Länge der einzelnen Vokale (vgl. Solari 1997, 225).
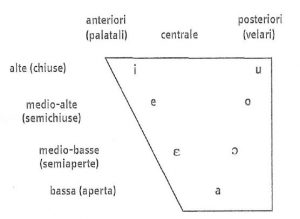
Im italiano standard gibt es sieben Vokale, die den betonten Vokalen zugeordnet werden können: [i, e, ɛ, a, ɔ, o, u]. Diese Vokale können lang oder kurz ausgesprochen werden und folgen zwei Regeln. Eine betonte, offene Silbe, die demnach keine konsonantische Coda besitzt, hat einen langen Vokal und eine betonte, geschlossene Silbe, die über eine konsonantische Coda verfügt, hat einen kurzen Vokal (vgl. Maturi 2009, 72-73). Diese Regel unterscheidet sich vom Deutschen in der Hinsicht, dass im deutschen Lautsystem lange Vokale grundsätzlich geschlossener und kurze Vokale offener betont werden. Diese Ausspracheregel wird in betonten Silben immer eingehalten, wohingegen in unbetonten Silben kaum Gesetzmäßigkeiten vorgefunden werden können (vgl. Siebs 1969, 21).
Bei Betrachtung des italienischen Lautsystems ist außerdem auffallend, dass der Schwa-Laut [ə] nicht existiert und auch der zentral gelegene Vokal [ɐ] nicht im italienischen Lautsystem vorzufinden ist. Es könnte demnach vermutet werden, dass Italiener den Laut [ə], der bei deutschsprachigen Sprechern in ihrer Aussprache des Italienischen möglicherweise auftreten könnte, vergleichsweise einfach als fremd identifizieren könnten, da dieser Laut in ihrem Lautsystem nicht vertreten ist (vgl. Michel 2006, 184). Eine ähnliche Vermutung könnte auch in Hinblick auf den Vokal [ɐ] aufgestellt werden, da dieser ebenfalls nicht im italienischen Lautsystem vorzufinden ist und er dadurch gleichermaßen fremdartig auf Italiener wirken könnte.
Eine Gemeinsamkeit zwischen dem italienischen und deutschen Lautsystem lässt sich jedoch bei den geschlossenen Vokalen [i, u] sowie bei dem offenen Vokal [a] feststellen, da die Mundstellung für die Realisierung der Laute in beiden Lautsystemen übereinstimmt. Doch nicht nur die Mundstellung gleicht einander, sondern auch die Artikulationsstellen weisen Parallelen auf. So wird sowohl im italienischen als auch im deutschen Lautsystem der Laut [i] vorne, der Laut [a] zentral und der Laut [u] hinten im Mundraum produziert. Dieser Beobachtung kann außerdem hinzugefügt werden, dass palatale Vokale im Italienischen immer gespreizt und velare Vokale stets gerundet sind (vgl. Michel 2016, 82). Das Phon [i], das im Italienischen demnach geschlossen und gespreizt ist, kann in gleicher Weise auch im deutschen Lautsystem vorgefunden werden und auch das Phon [u], das nach Anwendung der Regel im Italienischen offen und gerundet ist, kann mit diesen Attributen ebenfalls im deutschen Lautsystem vorgefunden werden, da hintere Vokale in ebendiesem, unter Auslassung von [ɑ], grundsätzlich gerundet sind (vgl. Noak 2010, 35).
Zusammenfassend kann demnach die Hypothese aufgestellt werden, dass deutsche Sprecher beim Italienischerwerb Schwierigkeiten bei der Differenzierung von offenen und geschlossenen Vokalen in der Aussprache aufweisen könnten, da die Aussprache offener und geschlossener Vokale in der deutschen Sprache, je nach Region und Land, unterschiedlich ausfällt und sie anderen Regeln als in der italienischen Sprache folgt. Ein wichtiger Unterschied wird wahrscheinlich speziell in Bezug auf die Aussprache von [e] sowie [ɛ] vorzufinden sein, da diese Phone, abgesehen von ihrem Öffnungsgrad, je nach Position von deutschsprachigen Italienischlernern als Schwa [ə] realisiert werden könnten. Gleichzeitig kann aber auch vermutet werden, dass wahrscheinlich keine signifikanten Unterschiede bei den Vokalen [i, a, u] auftreten werden, da diese in beiden Lautsystemen vorhanden sind, sich nur in manchen Fällen in ihrer Länge unterscheiden und bei ihnen keine Unterschiede hinsichtlich ihres Öffnungsgrades, der Mundstellung und der Artikulationsstelle bestehen (vgl. Pittner 2013, 22-24). In Bezug auf die spätere linguistische Analyse kann also festgehalten werden, dass die Realisierungen von [e, ɛ] sowie [o, ɔ] durch deutschsprachige Sprecher in Hinblick auf Interferenzen lautlicher Merkmale besonders interessant sein könnten.
Unterschiede lassen sich jedoch nicht nur zwischen dem italienischen und deutschen Vokalsystem feststellen, sondern parallel auch zwischen dem italienischen und deutschen Konsonantensystem, das nun im Anschluss behandelt werden soll.
2.4.2. Konsonantenrealisation italienischer Sprecher
Das italienische Lautsystem verfügt insgesamt über 23 konsonantische Phoneme (vgl. Canepari 2007, 13), die, wie auch die konsonantischen Phoneme des deutschen Lautsystems, nach Artikulationsort und Artikulationsart eingeteilt werden können.
| bi- labial |
labio- dental |
dental | alveolar | prä- palatal |
palatal | velar | |
| Nasale | m | ɱ | n | ɲ | ŋ | ||
| Plosive | p b | t d | k g | ||||
| Frikative | f v | s z | ʃ | ||||
| Affrikate | ts dz | tʃ dʒ | |||||
| Vibranten | r | ||||||
| Laterale | l | ʎ | |||||
| Approximanten | j | w |
Tabelle 2: Konsonanten im Italienischen (vgl. Michel 2016, 84)
Interessant ist in Hinblick auf die Konsonanten des italienischen Lautsystems zu sehen, dass sich ihre Artikulationsorte von denen des deutschen Lautsystems zum Teil unterscheiden. Dieser Umstand kann erklären, warum manche Laute, die von deutschen Sprechern produziert werden, im Italienischen anders ausgesprochen oder als ‚fremd‘ perzipiert werden. Stellt man einen Vergleich an, ist deutlich zu sehen, dass die Plosive [p] und [b] in beiden Fällen bilabial erzeugt werden, die Plosive [t] und [d] hingegen aber im Deutschen alveolar3 und im Italienischen dental4 gebildet werden. Dieser Unterschied des Artikulationsorts kann sich auf die Aussprache der deutschen Sprecher im Italienischen auswirken und dazu führen, dass Italiener anhand der Plosive [t] und [d] erkennen können, dass es sich bei einem Sprecher nicht um einen Muttersprachler handelt. Die Plosive [p] und [b] sollten im Gegensatz dazu nicht auf den Umstand hinweisen, dass jemand kein Muttersprachler ist, da sie sowohl im Italienischen als auch im Deutschen auf dieselbe Art und Weise produziert und ausgesprochen werden. Interessant wäre in diesem Fall also zu sehen, ob die alveolaren Plosive der deutschsprachigen Italienischlerner tatsächlich häufiger auf ihre Herkunft hinweisen, als bilabiale Plosive.
Ein weiterer wichtiger Unterschied ist auch in Bezug auf den Vibranten [r] zu erkennen. Wie bereits erklärt wurde, wird der Konsonant r im Deutschen meist uvular ausgesprochen und unterscheidet sich damit stark vom italienischen r, das in der Regel alveolar ausgesprochen und damit ‚gerollt‘ wird. Zwar gibt es im deutschen Sprachraum einige Regionen, in denen das r ebenfalls alveolar ausgesprochen wird, doch gibt es keine Region im italienischen Sprachraum, in der der Konsonant r uvular ausgesprochen wird. Sollte ein deutscher Italienischlerner also nicht in der Lage sein, sich an die italienische Aussprache anzupassen, könnte dieser Umstand ein klares Indiz für Italiener sein, um Fremdsprachenlerner und vor allem deutsche Sprecher zu erkennen.
Ein weiterer Unterschied zwischen dem deutschen und dem italienischen Lautsystem kann, wie bereits im vorherigen Kapitel kurz erwähnt, bei den Nasalen festgestellt werden. Im Italienischen gibt es fünf Nasale, wohingegen das deutsche Lautsystem nur drei vorweisen kann. Die Laute [ɱ] und [ɲ], die labiodental bzw. palatal produziert werden, fehlen demnach in der deutschen Sprache und könnten aus diesem Grund für deutsche Italienischlerner schwieriger zu produzieren sein. Überdies führt die Aussprache des stimmhaften Frikativs [z] sowie des stimmlosen Affrikaten [ts] oftmals zu Schwierigkeiten und lautlichen Überschneidungen bei deutschsprachigen Sprechern, da diese im Italienischen mit dem gleichen Graphem abgebildet werden.
Allgemein kann in Bezug auf das italienische Lautsystem also festgehalten werden, dass bei einem kontrastiven Vergleich dentaler und bilabialer Plosive interessant zu beobachten wäre, ob italienische Muttersprachler häufiger lautliche Differenzen in Hinblick auf die italienische Sprache bei dentalen Plosiven als bei bilabialen Plosiven perzipieren. Weitere Laute, die zu spannenden Ergebnissen mit Blick auf einen Perzeptionstest führen könnten, wären unter anderem der Vibrant [r] oder die Frikative und Affrikate.
Im Anschluss an die Erläuterung des deutschen und italienischen Lautsystems soll nun ein Überblick zur Perzeptiven Linguistik folgen, die die Grundlage des Aufbaus der späteren empirischen Untersuchung und seiner Auswertung bildet.
3. Perzeptive Linguistik
Die Annahme, dass Menschen nicht nur über sprachliches Wissen verfügen, das sich auf die Kompetenz des Sprechens und Verstehens einer Sprache bezieht, sondern auch Wissen besitzen, das Sprachen und Varietäten in ihrer Gesamtheit betrifft, bildet die Basis der perzeptiven Linguistik (vgl. Krefeld/Pustka 2010, 10). Dieses Phänomen wird in der Literatur häufig mit verschiedensten Begriffen beschrieben, wie beispielsweise „Sprachbewusstsein“ (Gauger 1976) oder „metasprachliches Wissen“ (Berruto 2002), obwohl dabei kritisiert werden muss, dass sich Sprecher über einen Teil dieses Wissens oftmals nicht bewusst sind und zum Metasprachlichen auch Wissen über die interne Struktur einer Sprache vorhanden sein muss und dies nicht immer der Fall ist (vgl. Krefeld/Pustka 2010, 11). Grundsätzlich kann aber gesagt werden, dass sich die perzeptive Linguistik mit „der Wahrnehmung sprachlicher Variation durch die Sprecher selbst“ (Krefeld/Pustka 2014, 9) beschäftigt und demnach das Sprachbewusstsein von Laien in den Vordergrund stellt und mit ebendiesem arbeitet (vgl. Ille/Vetter 2010, 234).
Diese linguistische Forschungsweise bringt viele Vorteile mit sich und ermöglicht es beispielsweise, aufgenommene Sprachaufnahmen von Muttersprachlern bewerten zu lassen und diese Ergebnisse später mit einer selbst durchgeführten phonetischen Analyse von Audiodaten zu vergleichen. Denkbar wäre bei diesem Szenario, dass bei der phonetischen Analyse Unterschiede in Hinblick auf geschlossene und offene Vokale im Vergleich zur standarditalienischen Aussprache festgestellt werden könnten, diese den italienischen Sprechern aber nicht auffallen oder sich für Personen einer bestimmten Region normaler anhören, als für Personen aus anderen Regionen Italiens. Mithilfe der perzeptiven Linguistik kann also erfasst werden, welche sprachlichen Variationen von Sprechern tatsächlich wahrgenommen werden und nicht nur, welche Phoneme beispielsweise rein phonetisch und technisch gesehen von einer standarditalienischen Aussprache abweichen.
Perzeptive Studien, die sich mit der italienischen Sprache und der Wahrnehmung ebendieser befassen, unterliegen oftmals einer diatopischen oder diachronen Fragestellung. So beschäftigten sich Ille/Vetter (2010) beispielsweise mit Wahrnehmungsaspekten des deutsch-italienischen Varietätenkontaktes im historischen sowie aktuellen Wien, D'Agostino/Pinello (2010) und Soriani (2010) mit linguistischen Differenzen und geo-soziolinguistischen Dynamiken im Sizilianischen und Amenta/Castiglione (2010) versuchte mithilfe eines perzeptiv-linguistischen Ansatzes, neue Kriterien für eine Definition des Regionalitalienischen zu finden.
Im Bereich der Didaktik und des Fremdsprachenerwerbs sind solche perzeptiven Studien allerdings noch eher selten zu finden. Die Abfrage der Wahrnehmung von Muttersprachlern bietet in diesem Fall aber ein hohes Potential, um Aussagen über den Fremdsprachenerwerb mit Blick auf die Aussprache der Sprecher zu treffen und um Verbesserungen im Bereich der Aussprache von Fremdsprachen voranzutreiben. Dass immer noch ein didaktisches Desiderat in Hinblick auf phonetisch-phonologische Eigenschaften im Bereich des Fremdsprachenerwerbs besteht, konnten nicht zuletzt Gärtig/Rocco (2018) nach Durchführung ihrer perzeptiven Studie, in der sie Untersuchungen zur L1- und L2-Phonetik und -Phonologie junger italienischer Deutschlerner durchgeführt sowie ein Lernerkorpus mit den wichtigsten Fehlerquellen italienischer Deutschlernender erstellt haben, feststellen. Die Tatsache, dass weitere Untersuchungen zu L2 Akzenten von Lernern nötig sind, soll jedoch nicht bedeuten, dass Lerner im Laufe des Erwerbs einer neuen Fremdsprache ihren Akzent komplett ablegen sollen oder müssen, um sagen zu können, dass sie erfolgreich eine Fremdsprache erlernt haben, sondern vielmehr, dass Forscher Fremdsprachenlernern die Möglichkeit bieten möchten, häufig auftretende lautliche Differenzen früh zu erkennen und diese, falls das Bedürfnis besteht, eigenständig zu verringern und sich in dieser Hinsicht den Muttersprachlern anzupassen.
Auch für die spätere empirische Untersuchung lautlicher Merkmale deutscher L1 Sprecher im Italienischen soll die Perzeptive Linguistik helfen, Aussagen über die Dimensionen der Wahrnehmung von Italienern in Hinblick auf Fremdsprachenlerner zu treffen. Der gewählte perzeptive Ansatz soll in der späteren empirischen Untersuchung demnach in erster Linie die Wahrnehmung der Italiener abbilden und veranschaulichen, wie präzise sie Abweichungen in der Aussprache italienischer Wörter von deutschen Sprechern feststellen können. Durch diese Art von Untersuchung rücken die Sprecher, sowohl auf deutscher als auch auf italienischer Seite, in den Vordergrund und die italienischen Sprecher können so alleinig mithilfe ihrer Intuition und ihrem natürlichen Wissen über die italienische Sprache, Aussagen über die Aussprache deutscher Italienischlerner treffen und aufzeigen, ob und wo Probleme in der Aussprache der deutschen Sprecher bestehen. Im Anschluss daran sollen die italienischen Sprecher allerdings nicht bewerten, welcher deutsche Akzent ihnen besser oder weniger gut gefällt, sondern lediglich versuchen zu bestimmen, aus welchen Regionen die deutschen Sprecher stammen. Wie der Online-Perzeptionstest für die empirische Studie genau aufgebaut wurde und welche Aufgaben die Teilnehmer zu absolvieren hatten, wird ausführlich in Kapitel 4.2. Konzeption und Durchführung des Perzeptionstests dieser Arbeit beschrieben und erläutert werden.
Nach der Erläuterung des theoretischen Hintergrundes, der die Basis für diese Arbeit und für die Konzeption der gesamten empirischen Untersuchung sowie der Analyse darstellt, soll nun der empirische Teil dieser Arbeit folgen.
4. Die empirische Untersuchung
Die durchgeführte empirische Untersuchung und Analyse interferierter lautlicher Merkmale deutscher L1 Sprecher im Italienischen setzt sich aus der Datenerhebung, d.h. der Aufnahme von italienischen Sprachdaten deutscher L1 Sprecher aus Deutschland, Österreich und der Schweiz, und dem von Italienern absolvierten Online-Perzeptionstest zusammen. Die erste Phase der empirischen Untersuchung war durch die Konzeption einer passenden Wortliste, der Wahl einer geeigneten Sprechbedingung, der Suche nach Probanden und der Aufnahme von deutschen L1 Sprechern gekennzeichnet, während die Wahrnehmung der Italiener in der zweiten Phase im Vordergrund stand und auf Basis ebenjener Perzeptionen eine Auswertung in Hinblick auf Interferenzen bei lautlichen Merkmalen sowie auf die Länderzuordnung der deutschsprachigen Italienischlerner durchgeführt wurde.
Im Folgenden werden die Methoden, die in der ersten und zweiten Phase der empirischen Untersuchung Verwendung fanden, erläutert werden. Außerdem wird auf Probleme, die während der Vorbereitung, Aufnahme und Analyse der Sprachdaten aufgetreten sind, eingegangen werden.
4.1. Konzeption und Durchführung der Sprachaufnahmen
4.1.1. Wortliste und Trägersätze
Um Interferenzen bei lautlichen Merkmalen im Italienischen von deutschen L1 Sprechern feststellen zu können, wurde eine Wortliste mit italienischen Wörtern erstellt, die die Aussprache der Vokale [ɛ], [e], [ɔ] und [o], der Plosive [t] und [p] sowie des Vibranten [r] überprüft. Diese Auswahl wurde aufgrund der Unterschiede zwischen dem deutschen und dem italienischen Lautsystem getroffen und umfasst einen Teil der Vokale und Konsonanten, bei denen lautliche Interferenzen vermutet werden5.
In der Wortliste wird jedes konsonantische Phon durch fünf bzw. sechs ausgewählte Wörter repräsentiert, die außerdem zur Untersuchung der vokalischen Phoneme /ɛ/, /e/, /ɔ/ und /o/ dienen werden, da diese zusätzlich in den ausgewählten Wörtern enthalten sind. Bei der Erstellung der Wortliste wurde darauf geachtet, dass die ausgewählten Phone, wenn möglich, an verschiedenen Positionen innerhalb der Wörter auftauchen, um später eventuell Aussagen über den Einfluss der Stellung der Vokale und Konsonanten in Hinblick auf die Aussprache der Probanden treffen zu können. Die vollständige Wortliste mit der genauen Anzahl der zu untersuchenden Laute findet sich unter Anhang 3: Wortliste und Trägersätze.
Insgesamt umfasst die Wortliste zwölf Wörter, die von 18 Probanden, sechs aus Deutschland, sechs aus Österreich und sechs aus der Schweiz, eingesprochen wurden. Die Basis des perzeptiven Tests bilden folglich 216 Sprachaufnahmen, die in insgesamt 108 Fällen jeweils das Phon [t], das Phon [d] und den Vibranten [r] widerspiegeln. Die Phone [ɛ] und [e] kommen ebenfalls in 72 bzw. 144 Fällen vor und die Phone [ɔ] und [o] werden in 36 bzw. 144 Fällen in den Sprachaufnahmen abgebildet. Nicht jedes ausgewählte und zu untersuchende Phon wird demnach gleich häufig von den Probanden realisiert, was mit der geringen Anzahl an Wörtern zusammenhängt, die für diese Studie ausgewählt wurden. Die Wörter wurden so ausgewählt, dass möglichst viele Laute gleichzeitig abgebildet werden, doch konnten Abweichungen in der Anzahl nicht vermieden werden. Diese Abweichungen werden jedoch in die Auswertung einfließen und in Relation zu den Ergebnissen gesetzt werden.
Die oben genannten Phone wurden für die empirische Untersuchung aus mehreren Gründen ausgewählt. Wie bereits in Kapitel 2.3. Lautsystem der deutschen Sprache erklärt und erläutert wurde, können bei Deutschen, Österreichern und Schweizern bereits Unterschiede in der deutschen Aussprache von Vokalen vorgefunden werden, wodurch angenommen werden kann, dass sich diese Unterschiede auch in der italienischen Sprache widerspiegeln und ein Mittel zur Erschließung der Herkunft der deutschen Sprecher darstellen könnten. Des Weiteren unterscheidet sich der Öffnungsgrad von Vokalen bei Italienischlernern oftmals vom Öffnungsgrad italienischer Muttersprachler, was ebenfalls Aufschluss darüber geben könnte, ob sich deutsche Italienischlerner eine authentische Aussprache aneignen können.
Die Konsonanten [t], [p] und [r] wurden für die empirische Untersuchung ausgewählt, da, zum einen Plosive im Deutschen häufig mit einer starken vorherigen Aspiration verbunden sind und untersucht werden soll, ob größere lautliche Differenzen bei dem Plosiv [t] im Vergleich zum Plosiv [p] konstatiert werden können, und zum anderen, der Vibrant [r] nur selten in der deutschen Sprache Verwendung findet und deswegen lautliche Interferenzen durch die deutsche Muttersprache in Hinblick auf die Realisierung des r-Lautes zu erwarten sind.
Die ausgewählte Methode hat den Vorteil, dass einerseits eine große Kontrolle über die empirische Untersuchung besteht und andererseits die spätere Segmentierung der gesuchten Vokale und Konsonanten überschaubar ist. Zudem gewährleisten Wortlisten eine sehr gute Vergleichbarkeit, da alle Sprecher dieselben Wörter und dieselben Trägersätze lesen.
Das hohe Maß an Kontrolle, das dieser Methode zugrunde liegt, bringt aber auch einige Nachteile mit sich. Spontansprache, die als natürlichste Form der Sprache gilt, kann mit dieser Methode nicht erzielt werden und das Konzept der Wortliste führt außerdem häufig dazu, dass Probanden in ein Intonationsmuster verfallen, das unbewusst für Listen jeglicher Art verwendet wird. Dies hat zur Folge, dass die ersten Wörter einer jeden Wortliste meistens eine uniform ansteigende Intonationskurve vorweisen, generell eine Längung wortfinaler Vokale stattfindet und außerdem, fast unweigerlich, eine stark abfallende Intonationskurve beim letzten Wort der Liste vorhanden ist (vgl. Ladefoged 2011, 7).
Um diese Nachteile auszugleichen, wurde für die Analyse zunächst für jedes Wort der Liste ein Trägersatz konstruiert, der das Wort in einen möglichst natürlichen Kontext einbettet. Dieser soll nicht nur der Längung von wortfinalen Vokalen entgegenwirken, sondern auch gleichzeitig die Intonationskurve normalisieren. Die für die empirische Untersuchung konstruierten Trägersätze können unter Anhang 3: Wortliste und Trägersätze eingesehen werden. Des Weiteren wurde den Probanden eine randomisierte Liste vorgelegt, um zu gewährleisten, dass nicht immer dieselben Wörter an erster und letzter Stelle der Liste stehen und die besonderen Intonationen bei ersten und finalen Wörtern abgeschwächt werden.
4.1.2. Sprechbedingung
Bei der Auswahl der Sprechbedingung stand der Gedanke im Vordergrund, dass Interferenzerscheinungen im Bereich lautlicher Realisierungen von ausgewählten Konsonanten und Vokalen des Italienischen bei deutschen L1 Sprechern aus Deutschland, Österreich und der Schweiz erhoben werden sollen.
Die Erhebungsmethode mit den wohl natürlichsten Ergebnissen wäre sicherlich das Aufnehmen frei getätigter Äußerungen der Probanden gewesen, doch gab es einige Hindernisse, die diese Erhebungsmethode unterbunden haben. Erstens hätte die Vielfalt an Äußerungen, sprich der Belege für die zu beobachtenden Parameter, dazu geführt, dass keinerlei Kontrolle darüber bestanden hätte, wie häufig die ausgewählten Konsonanten und Vokale in den getätigten Äußerungen tatsächlich aufgetaucht wären. Die Belege der zu beobachtenden Konsonanten und Vokale hätten folglich kaum ökonomisch und in kürzester Zeit erfasst werden können. Zweitens muss ebenfalls in Betracht gezogen werden, dass die Probanden für eine solche Erhebungsmethode frei in einer Fremdsprache, eventuell sogar in Gegenwart fremder Personen, hätten sprechen und kommunizieren müssen, was ein sehr hohes Maß an Selbstvertrauen vorausgesetzt hätte und womöglich dazu geführt hätte, dass sich überhaupt keine oder nur deutsche Sprecher mit Niveau C1 oder C2 für die Aufnahmen gefunden hätten. Drittens, was für Untersuchungen im Bereich der Phonetik noch schwerer wiegt, können Feldaufnahmen aufgrund der auftretenden Hintergrundgeräusche und der natürlichen Geräuschkulisse einer echten Gesprächssituation nur sehr selten für phonetische Analysen verwendet werden, da kaum sinnvolle Interpretationen der Daten möglich sind (vgl. Grassegger 1988, 114).
Aus diesen Gründen wurde sich für die Sprechbedingung ‚Lesen‘ entschieden, die zwar eine Verzerrung der natürlichen Sprechsituation darstellt, aber unter Anbetracht der Tatsache, dass sich die Probanden aus technischen Gründen in einem komplett ruhigen Raum befinden und sich darüber bewusst sind, aufgenommen zu werden, zu keiner noch größeren Verzerrung führt. Grassegger (1988) betont überdies, dass das Lesen bzw. Vorlesen im Fremdsprachenunterricht als Lehrmittel eingesetzt wird und aus diesem Grund auch für eine phonetische Untersuchung eingesetzt werden kann, da den Probanden ebendiese Sprechsituation aus dem Fremdsprachenunterricht bekannt ist (vgl. Grassegger 1988, 114-115).
Welche Probanden für die Sprachaufnahmen ausgewählt wurden und wie die Suche nach ihnen verlaufen ist, wird Gegenstand des nächsten Kapitels sein.
4.1.3. Probanden
Für die Sprachaufnahmen wurden insgesamt 18 Probanden aufgenommen, von denen sechs aus München (Deutschland), sechs aus Wien (Österreich) und sechs aus Zürich (der Schweiz) stammen. Alle Probanden sind zwischen 18 und 30 Jahre alt und haben die Gemeinsamkeiten, dass Deutsch ihre L1 ist und sie mindestens das Niveau B1 in Italienisch besitzen. Außerdem sind alle Probanden in der jeweiligen ausgewählten Stadt, sprich München, Wien oder Zürich, oder in der näheren Umgebung dieser Städte aufgewachsen. Dadurch soll die Zuordnung der deutschen L1 Sprecher durch die Italiener, die den Perzeptionstest bearbeiten, vereinfacht und Verwirrungen durch unterschiedliche Akzente oder Einflüsse von Dialekten eines Landes unterbunden werden. Der Perzeptionstest verfolgt nämlich zum einen das Ziel, Unterschiede in der Aussprache der deutschen Lerner im Vergleich zu italienischen Sprechern aufzuzeigen und zum anderen Ähnlichkeitsrelationen zwischen den unterschiedlichen deutschen Lernern herzustellen. Diese Ähnlichkeitsrelationen sollen durch die Zuordnung der Sprachaufnahmen der deutschen Sprecher durch die Italiener hergestellt werden. Wie diese Zuordnung im Einzelnen funktioniert, wird in Kapitel 4.2.1. Konzeption des Perzeptionstests erklärt.
Die Probandensuche erwies sich in den Städten München und Wien als relativ problemlos, wohingegen sich die Suche nach schweizerischen Probanden als äußerst mühselig erwies. In München haben sich andere Studenten und Studentinnen der Romanistik und der Italianistik, mit denen bereits persönlicher Kontakt durch das Studium bestand, bereit erklärt, an der Studie teilzunehmen, wodurch sich innerhalb eines sehr kurzen Zeitraumes bereits sechs Probanden gefunden hatten. In Wien konnte eine Probandin ebenfalls durch einen persönlichen Kontakt für die Sprachaufnahmen gewonnen werden und über die Facebook-Gruppe ‚Romanistik Uni Wien‘, die über fast 5000 Mitglieder verfügt, konnte das Interesse weiterer fünf Probanden geweckt werden.
Für die empirische Untersuchung sollten außerdem Probanden aus Bern gewonnen werden, weswegen zunächst die Universität Bern und das dortige Institut der Romanistik kontaktiert wurde. Leider konnte die Universität nur anbieten, einen Flyer auszuhängen, auf den sich keine Studenten gemeldet haben, und auch die Suche nach einer Facebook-Gruppe für die Studenten des Studiengangs Romanistik in Bern verlief enttäuschend, da keine solche Gruppe existiert. Daraufhin wurden zwei Schulen im Zentrum von Bern mit der Bitte und Frage kontaktiert, ob eventuell Schüler, die mindestens 18 Jahre alt sind, Interesse hätten, an der Studie teilzunehmen. Eine Schule sprach sich sofort gegen die Teilnahme aus und die zweite Schule antwortete leider niemals auf die Anfrage. Aus diesem Grund wurde letztendlich die Entscheidung getroffen, eine andere Stadt in der Deutschschweiz für die empirische Untersuchung auszuwählen. Die Wahl fiel dabei auf die Stadt Zürich, die ein aktives Sprachenzentrum hat, das gemeinsam von der Universität Zürich und der Technischen Hochschule Zürich geleitet wird und in dem auch Italienisch unterrichtet wird. Über eine Rundmail an die Kursteilnehmer der angebotenen Italienischkurse konnten so zwei Probanden gefunden werden, die ebenfalls dem Profil der gesuchten Probanden entsprechen. Ein weiterer Proband konnte außerdem über persönliche Beziehungen für das Projekt begeistert werden und die letzten drei benötigten Probanden konnten beim Besuch von Italienischkursen des Sprachenzentrums in Zürich für das Projekt gewonnen werden.
Vor Durchführung der Sprachaufnahmen sollten die Probanden einen kurzen Fragebogen ausfüllen, der unter Anhang 1: Fragebogen ‚Persönliche Daten‘ eingesehen werden kann. Mithilfe dieses Fragebogens sollten nicht nur demographische Daten erfasst werden, sondern auch Daten in Bezug auf den Fremdsprachenerwerb Italienisch und das Sprachverhalten selbst erhoben werden. Konkret sollten die Probanden beispielsweise angeben, ob sie einen Dialekt beherrschen, welche Fremdsprachen sie auf welchem Sprachniveau sprechen, wie lange sie schon Italienisch lernen, ob sie regelmäßigen Kontakt zu italienischsprachigen Freunden oder Bekannten pflegen und ob sie längere Zeit in einem italienschsprachigen Land verbracht haben.
Die Antworten auf die soeben genannten Fragen sollen nach Durchführung des Perzeptionstests und der darauffolgenden Analyse der Sprachdaten Aufschluss darüber geben, warum ein Proband eventuell nicht einer bestimmten Gruppe oder dem entsprechenden Land zugeordnet werden konnte oder warum beispielsweise keine signifikanten Unterschiede in der Aussprache von den Italienern wahrgenommen werden konnten.
4.1.4. Durchführung
Die Sprachaufnahmen wurden mit dem Programm SpeechRecorder aufgenommen, das zum einen die Möglichkeit bietet, ein Skript hochzuladen und zu randomisieren, und zum anderen die eingespeicherten Sätze den Probanden in einem Fenster präsentiert, sodass diese leicht vorgelesen werden können. Mithilfe des Programms können die Aufnahmen manuell, oder auf Wunsch auch automatisch, begonnen und gestoppt werden. Im Zuge dieser Aufnahmen wurden die Probanden manuell aufgenommen und zudem wurde ihnen die Möglichkeit geboten, Aufnahmen zu wiederholen, sollten sie beispielsweise über die Sätze gestolpert sein. Dieses Angebot sollte einerseits dazu führen, dass sich die Probanden weniger nervös fühlen und weniger Druck verspüren, und andererseits dazu, dass alle ausgewählten Wörter, die für den Perzeptionstest verwendet werden, klar hörbar sind und während des Perzeptionstests ohne Probleme bewertet werden können. Um eine gute Qualität der Sprachaufnahmen zu gewährleisten, wurde zusätzlich das Mikrofon Sony ECM-MS907 angeschlossen.
Bei der Durchführung der Sprachaufnahmen wurde darauf geachtet, dass der Raum, der für die Sprachaufnahmen ausgewählt wurde, ruhig war und keine störenden Geräusche, wie beispielsweise das Ticken einer Uhr oder das Summen eines Kühlschranks, zu hören waren. Außerdem gab es eine kleine Einführung für die Probanden, damit sie wussten, wann sie beginnen konnten, den präsentierten Satz vorzulesen.
Alles in allem kann gesagt werden, dass für jede Sprachaufnahme ein geeigneter Ort gefunden werden konnte und nur selten Aufnahmen aufgrund von Störgeräuschen, wie beispielsweise einer zuschlagenden Tür, wiederholt werden mussten. Die Aufnahmen dauerten in der Regel zwischen fünf und zehn Minuten und das Ausfüllen des Fragebogens und das Unterschreiben der Einverständniserklärung beanspruchte weitere fünf Minuten der Probanden. Die durchschnittliche Dauer der Aufnahmen betrug demnach circa 15 Minuten. Nur wenige Probanden hatten bereits Erfahrungen mit Sprachaufnahmen gesammelt, was in einigen Fällen zu einer erhöhten Nervosität der Probanden geführt hat. Bei erhöhter Nervosität half es einigen Probanden, den angezeigten Satz vor dem Vorlesen kurz für sich durchzulesen oder bei Bereitschaft kurz zu nicken, damit die Aufnahme gestartet werden konnte.
Um die Sprachaufnahmen, die manchmal beispielsweise kurze Räusperer am Anfang oder Ende beinhalten und selbstverständlich die zu untersuchenden Wörter mit den dazugehörigen Trägersätzen umfassen, für den Perzeptionstest vorzubereiten, wurden diese im Verlauf von zwei Phasen mit dem Programm Praat geschnitten. In der ersten Phase wurden die Sprachaufnahmen lediglich so geschnitten, dass der vorgelesene Satz die Aufnahme bildet und keine anfänglichen Geräusche oder längere Wartephasen ohne Geräusche am Anfang oder Ende der Aufnahmen mehr enthalten sind. Dies führte zu saubereren Aufnahmen, die später eventuell für andere Zwecke wiederverwendet werden könnten. In der zweiten Phase des Schneideprozesses wurden die ausgewählten Wörter, die die Basis des folgenden Perzeptionstests bilden, ausgeschnitten, sodass die abgespeicherten Audiodateien jeweils nur noch ein einziges Wort umfassen.
Beim Schneiden der einzelnen Wörter kam es manchmal zu Problemen, da beispielsweise zwei Vokale zwei verschiedener Wörter im Trägersatz direkt aufeinander folgten, wie zum Beispiel im Trägersatz Nummer sechs, in dem das Wort eppure direkt vor dem Verb era steht6. Um solche Schwierigkeiten zukünftig zu vermeiden, sollte darauf geachtet werden, dass sich Vokale in einem konsonantischen Umfeld befinden, damit sie genauer geschnitten werden können. Fälle, in denen die Vokale nicht klar voneinander abgegrenzt waren, haben zwar beim Schneiden für einen höheren Zeitaufwand gesorgt, doch konnten letztendlich alle Wörter erfolgreich ausgeschnitten und für den Perzeptionstest verwendet werden.
4.2. Konzeption und Durchführung des Perzeptionstests
Die zweite Phase der empirischen Untersuchung besteht aus einem Online-Perzeptionstest7, den Italiener in einem Zeitraum von zweieinhalb Wochen bearbeitet haben und der Aufschluss darüber geben soll, ob Italiener Differenzen in Hinblick auf lautliche Merkmale bei deutschsprachigen Italienischlernern feststellen können und ob sie dazu in der Lage sind, diese sogar dem entsprechenden Land, sprich Deutschland, Österreich oder der Schweiz, zuzuordnen. Die aufgenommenen und geschnittenen Audiodateien stellen die Basis dieses Perzeptionstests dar.
Im Folgenden wird zunächst die Konzeption des Tests beschrieben und erläutert werden, gefolgt von der eigentlichen Durchführung des Perzeptionstests. Zum Schluss werden die Ergebnisse des Tests präsentiert und diskutiert werden.
4.2.1. Konzeption des Perzeptionstests
Der Perzeptionstest wurde mithilfe der Online-Plattform ‚Webapp‘8 des Instituts für Phonetik und Sprachverarbeitung (IPS) der Ludwig-Maximilians-Universität München erstellt und fragt, neben soziodemographischen Daten der Testteilnehmer, in erster Linie die auditive Wahrnehmung von Italienern in Hinblick auf die italienische Sprache ab. Zu Beginn des Tests erhält jeder Teilnehmer einen Fragebogen, in dem soziodemographische Daten, wie das Geschlecht, das Alter und die Herkunft der Probanden, abgefragt werden und in dem zudem Auskunft darüber gegeben wird, ob die Teilnehmer einen bestimmten Dialekt sprechen, welche Fremdsprachen sie sprechen, wo sie zurzeit wohnen und ob sie in ihrem Leben bereits im Ausland gelebt haben und falls ja, wo sie gelebt haben. Des Weiteren wird in dem Fragebogen auf den Gehörsinn der Teilnehmer eingegangen und festgehalten, ob sie beispielsweise ein gutes Gehör besitzen oder ihren Gehörsinn als eher weniger gut einstufen. Außerdem wird Rücksicht auf die Umgebung der Teilnehmer genommen und abgefragt, ob sie sich zum Beispiel in ihrem Zuhause befinden, in ihrem Büro oder gerade unterwegs sind. Überdies wird am Ende des Fragebogens kontrolliert, ob die Teilnehmer die Audioaufnahmen über einen In-Ear Kopfhörer, normalen Kopfhörer oder über einen Lautsprecher anhören. All diese Fragen sollen später bei der Auswertung zusätzlich Aufschluss darüber geben, warum in bestimmten Fällen spezielle Antworten gegeben oder nicht gegeben wurden. Sollte ein Teilnehmer beispielsweise angeben, dass er gerade unterwegs ist und somit höchstwahrscheinlich einem höheren Lärmpegel ausgesetzt ist, könnte dies eventuell ein Indiz dafür sein, warum er in manchen Fällen keine Buchstaben markiert hat oder Audioaufnahmen übersprungen hat.
Nach Beantwortung des Fragebogens gelangen die Teilnehmer durch einen Klick zur ersten tatsächlichen Testseite, die wie folgt aufgebaut ist:
Testseite des Online-Perzeptionstests
Auf der Testseite erscheint oben ein Kopfhörersymbol, das für die Audiodatei und das Abspielen ebendieser steht. Darunter befinden sich die erste Arbeitsanweisung und die jeweiligen Buchstaben des zu hörenden italienischen Wortes, die während oder nach dem Hören vom Testteilnehmer angeklickt werden können, sofern dieser einen Unterschied in der Aussprache der Sprecher in Hinblick auf die italienische Sprache feststellen kann. Das Ende der Testseite stellt ein Drop-Down-Menü dar, das dem Teilnehmer des Perzeptionstests die Möglichkeit bietet, dem Sprecher der Audioaufnahme ein Land aus einer vorgefertigten Liste zuzuweisen oder anzugeben, dass der Sprecher keinem Land der Liste zugeordnet werden kann. Die Länder Austria ‚Österreich‘, Germania ‚Deutschland‘, Italia ‚Italien‘ und Svizzera ‚Schweiz‘ und die Option Non assegnabile ‚nicht zuweisbar‘ können im Drop-Down-Menü vorgefunden und ausgewählt werden. Die Länder sind dabei in alphabetischer Reihenfolge aufgelistet, während die Auswahlmöglichkeit Non assegnabile am Ende des Drop-Down-Menüs zu finden ist. Dies soll dazu beitragen, dass sich die Teilnehmer durch die Reihenfolge der Länder nicht beeinflusst fühlen. Die Möglichkeit, das Land Italien auszuwählen, soll außerdem Aufschluss darüber geben, ob der Italienischlerner als solcher überhaupt erkannt wird, und könnte beispielsweise gewählt werden, wenn der Teilnehmer keine Grapheme markiert und somit zum Ausdruck bringt, dass er keine lautlichen Differenzen feststellen kann.
Da einige Testwörter über Doppelkonsonanten verfügen und Verwirrung auf Seiten der Teilnehmer vermieden werden soll, können die Doppelkonsonanten der Wörter terra, terremoto, penna und eppure nur zusammen markiert werden. Dies soll die Auswertung erleichtern, da man sich niemals sicher sein könnte, ob ein Teilnehmer bewusst den ersten oder den zweiten Konsonanten ausgewählt hat, sich durch Zufall für einen entschieden hat oder überhaupt nicht erkannt hat, dass beide Konsonanten markiert werden können. Auch beim Wort parchi können die Konsonanten c und h nur zusammen markiert werden, da sie einen gemeinsamen Laut abbilden.
Der Perzeptionstest besteht demnach aus drei aufeinander folgenden Schritten: dem Anhören der Audiodatei, dem Markieren des bzw. der anders klingenden Buchstaben und der Zuordnung des Sprechers zu einem Land. Dieses Konzept muss im Laufe des Perzeptionstests insgesamt 216 Mal bearbeitet werden und wurde aufgrund der hohen Anzahl der Audiodateien auf zwei Skripte aufgeteilt. Dies bedeutet, dass das Programm, mit dem der Perzeptionstest erstellt wurde, jedem Teilnehmer, der auf den Link des Perzeptionstests klickt, automatisch ein Skript zuweist, das in sich randomisiert ist, und gleichzeitig darauf achtet, dass alle Audiodateien in gleicher bzw. ähnlicher Anzahl bearbeitet werden. Die Erstellung von zwei Skripten hat den Vorteil, dass die Teilnehmer weniger Audiodateien bewerten müssen und demzufolge eine höhere Bereitschaft bei der Teilnahme zeigen könnten und dennoch keine hohe Diskrepanz zwischen der Anzahl der bearbeiteten Audiodateien besteht. Durch die Verwendung von zwei Skripten muss jeder Teilnehmer folglich 108 Audiodateien innerhalb des Perzeptionstests bewerten, was einem Zeitaufwand von circa 30 Minuten entspricht.
Bei der Konzeption des Perzeptionstests war es also wichtig, den Test so aufzubauen, dass alle zu untersuchenden Vokale und Konsonanten einzeln bewertet werden konnten, die Audiodateien gleichzeitig einem Land zugewiesen werden konnten und die Teilnehmer des Perzeptionstests trotzdem keine zu hohe Anzahl an Sprachaufnahmen zu bearbeiten hatten.
4.2.2. Durchführung des Perzeptionstests
Der Perzeptionstest wurde nach Aufnahme der ausgewählten Sätze und Bearbeitung ebendieser Ende Mai 2019 gestartet. Der Test war ab dem 27. Mai 2019 für insgesamt zweieinhalb Wochen online und sollte von italienischen Muttersprachlern bearbeitet werden. Um zur Startseite des Perzeptionstests zu gelangen, wurde eine URL ausgegeben, über die jedem Teilnehmer automatisch eins der zwei vorhandenen Skripte zugewiesen wurde.
Die Interessenten mussten für die Teilnahme an dem Perzeptionstest nur wenige Voraussetzungen erfüllen. Einerseits musste ihre Muttersprache Italienisch sein und andererseits durften sie keinen sehr schlechten Gehörsinn besitzen. Des Weiteren mussten sie in der Lage sein, mit der gewählten Online-Plattform, die sich durch klare Strukturen und typische Abfragetools auszeichnet, umzugehen und fähig sein, die Audiodateien abzuspielen und anzuhören. Ob die italienischen Muttersprachler zur Zeit der Bearbeitung des Tests in Italien leben oder nicht, war für die Teilnahme an dem Test kein Ausschlusskriterium. Vielmehr wurde darauf gehofft, dass sowohl italienische Muttersprachler an dem Perzeptionstest teilnehmen, die entweder in Deutschland, Österreich oder der Schweiz wohnen bzw. für längere Zeit gewohnt haben und somit Erfahrungen mit der deutschen Sprache gesammelt haben, als auch Italiener, die noch nie in einem deutschsprachigen Land gelebt haben und nur wenig bis keine Erfahrung im Umgang mit der deutschen Sprache aufweisen können.
Die Suche nach Teilnehmern für den Perzeptionstest verlief dabei in erster Linie über den privaten Freundeskreis und über Facebook. Auf der Online-Plattform wurde zunächst ein privater Post veröffentlicht, der Freunden und Bekannten in ihrer Timeline angezeigt wurde und der den Link zum Test und die Bitte, an der Studie teilzunehmen, beinhaltet hat. Um die Reichweite des Gesuchs zu erhöhen, wurde zudem ein ähnlicher Post in den Facebook-Gruppen der Universitäten Università di Bologna, Università Ca‘ Foscari di Venezia, Università di Bari, La Sapienza–Università di Roma, Università di Milano, Università degli Studi di Lecce-Salento, Università Politecnica delle Marche, Università degli Studi di Palermo, Università degli Studi di Perugia und Università di Pisa veröffentlicht. Facebook-Gruppen wie Italiani a Monaco Di Baviera, Italiani a Zurigo, Italiani a Francoforte e dintorni-Germania, Italiani ad Amburgo und Italiani a Vienna wurden außerdem ebenfalls benachrichtigt. Es wurde versucht, Zugang zu allen Facebook-Gruppen der größten Universitäten Italiens zu erhalten, doch wurden oftmals Matrikelnummer und Studiengang abgefragt, sodass letzten Endes nicht für alle Facebook-Gruppen ein Zugang erworben werden konnte. Das Anschreiben von Italienern in deutschsprachigen Ländern sollte darüber hinaus dazu führen, dass Personen, die in den Gebieten der deutschsprachigen Italienischlerner leben, ebenfalls an dem Test teilnehmen und so Aussagen darüber getroffen werden können, ob Personen, die in einem bestimmten deutschsprachigen Land gelebt haben oder leben, Italienischlerner den jeweiligen Ländern bzw. dem jeweiligen Land treffsicherer zuordnen können oder nicht. Über diese Suchverfahren konnten letztendlich 40 Teilnehmer für den Perzeptionstest gefunden werden.
Die Durchführung des Perzeptionstests war allerdings von drei verschiedenen Komplikationen gekennzeichnet, die im Folgenden aufgezeigt werden sollen. Welche Auswirkungen diese auf die Ergebnisse des Perzeptionstests hatten, wird ebenfalls Bestandteil des nächsten Kapitels sein.
4.2.3. Komplikationen bei der Durchführung des Perzeptionstests
Bevor der Perzeptionstest an mögliche Teilnehmer und Teilnehmerinnen verteilt wurde, wurde dieser auf der Online-Plattform des Instituts für Phonetik getestet. Im Verlauf des Testens wurden noch kleinere Änderungen, wie beispielsweise die Abänderung von Formulierungen oder der Schreibung beim anfänglichen Fragebogen, vorgenommen und nach nochmaliger Überprüfung wurde die Freigabe für den Test erteilt. Als die ersten Ergebnisse über die Datenbank eingingen und diese angesehen wurden, konnte allerdings festgestellt werden, dass zwar die markierten Grapheme in der Ergebnistabelle verzeichnet wurden, aber keine Daten zum Drop-Down-Menü, das die Länderauswahl darstellt, in der Tabelle zu finden waren. Nach Rücksprache mit dem zuständigen Programmierer, der feststellen musste, dass ebendiese Eingabe nicht an den Server gemeldet wurde und deswegen die Daten nicht übermittelt werden konnten, obwohl das Drop-Down-Menü im Perzeptionstest selbst einwandfrei funktionierte, konnte das Problem gelöst werden. Da der Fehler sofort erkannt und behoben wurde, sind nur eine vollständige und eine unvollständige Experiment-Teilnahme davon betroffen. Aufgrund der Tatsache, dass bei der vollständigen Teilnahme allerdings keinerlei Buchstaben markiert wurden und zusätzlich die Übertragung der Daten des Drop-Down-Menüs nicht funktioniert hat, wird die gesamte Eingabe nicht in die Auswertung des Perzeptionstests einfließen.
Die zweite Komplikation bestand aus dem ungewollten Abbruch des Perzeptionstests aufgrund vom caricamento dei dati ‚Laden von Daten‘, das aus bisher ungeklärten Gründen bei unterschiedlichen Personen aufgetreten ist. Die Teilnehmer konnten in diesem Fall zunächst problemlos an dem Test teilnehmen, doch nach einer unbestimmten Anzahl von angehörten Audiodateien konnten keine weiteren Seiten mehr geladen und bearbeitet werden. Wie viele Personen tatsächlich von diesem Problem betroffen waren, lässt sich im Nachhinein nicht mehr feststellen, doch kann davon ausgegangen werden, dass einige der unvollständigen Experiment-Teilnahmen auf dieses Problem zurückzuführen sind. Da aber auch die Daten von unvollständigen Testteilnahmen abgespeichert wurden, werden diese ebenfalls für die Darstellung und Analyse der Ergebnisse herangezogen werden.
Die dritte und wahrscheinlich schwerwiegendste Komplikation trat etwa eine Woche nach Veröffentlichung des Perzeptionstests auf und betrifft neun Testteilnahmen, unter denen sich drei vollständige Teilnahmen befinden. In diesem Fall konnten die betroffenen Testteilnehmer die erste Arbeitsanweisung und Aufgabe nicht sehen und somit lediglich die Audiodateien anhören und eine Option des Drop-Down-Menüs auswählen, aber keine Buchstaben anklicken. Wie viele der neun Teilnehmer tatsächlich die Aufgabe nicht sehen konnten oder sich bewusst dafür entschieden haben, keine Buchstaben zu markieren, kann leider nicht nachvollzogen werden, doch steht fest, dass die Aufgabe bei mindestens zwei Teilnehmern nicht erschienen ist. Auf der Suche nach dem Fehler wurde zunächst überprüft, welches Endgerät die Teilnehmer, bei denen keine Daten für die erste Aufgabe in der Tabelle zu finden sind, für die Durchführung des Tests verwendet haben, und es konnte festgestellt werden, dass die betroffenen Teilnehmer sowohl Laptops als auch Handys benutzt haben. Bei der Verwendung von Laptops dürften grundsätzlich keine Probleme auftreten, da die verwendete Online-Plattform für diverse Browser konzipiert ist und das Anklicken eines Graphems durch Benutzung einer Computermaus oder eines Touchpads immer korrekt registriert wird. Es könnte allerdings sein, dass bei dem Versuch, Buchstaben über das Handy anzuklicken, die Eingabe nicht korrekt registriert wurde und deswegen keine Daten übermittelt werden konnten. Fest steht aber, dass sich ein korrekt markierter Buchstabe rot färbt und somit der Teilnehmer in der Lage sein müsste, seine Eingabe zu überprüfen. Demnach könnte es also sein, dass die weiteren sieben Testteilnehmer, bei denen eine Komplikation aufgetreten ist, Probleme mit ihrem Endgerät hatten oder die Aufgabe nicht angezeigt wurde. Des Weiteren besteht die Möglichkeit, dass die Teilnehmer die erste Aufgabe nicht mit Bedacht gelesen oder nicht verstanden haben und aus diesem Grund keine Buchstaben ausgewählt haben. Sinnvoll wäre es sicherlich in Hinblick auf weitere Durchführungen dieser Art von perzeptiven Tests, dass zu Beginn eine Anleitung, beispielsweise in Form einer einfachen Animation, für die Testteilnehmer bereitsteht, damit sie das nötige Vorgehen für den Test zur Not auch ohne Lesen der Aufgabenstellung verstehen und gleichzeitig sehen, wie eine korrekte Version des Tests aussehen müsste.
Die Ergebnisse dieser Testteilnahmen können zwar nicht vollständig in die Bewertung einbezogen werden, doch sollen die Länderangaben in die Analyse der Ergebnisse einfließen. Auf diese Weise kann zumindest festgestellt werden, ob die Teilnehmer die Audiodateien dem richtigen Land zuweisen konnten, auch wenn keine Aussagen über die Auswahl der Länder auf phonetischer Ebene möglich sind. Ungeklärt bleibt allerdings, warum andere Teilnehmer den Perzeptionstest im gleichen Zeitraum ohne die oben erläuterten Probleme absolvieren konnten.
Welche Ergebnisse der Test erzielt hat und welche Erkenntnisse durch ebendiese gewonnen werden können, wird im nächsten Kapitel beschrieben und erläutert werden. Wichtig bei der Betrachtung und Interpretation der Ergebnisse ist vor allem der Einbezug der aufgetretenen Probleme und ihr Einfluss auf die Anzahl und Art der Ergebnisse.
4.3. Perzeption der Sprachaufnahmen durch Italiener
Nach einer Laufzeit von zweieinhalb Wochen (27. Mai 2019 bis 15. Juni 2019) konnte der Online-Perzeptionstest eine Anzahl von 40 Teilnehmern9 verbuchen, die insgesamt 2579 Eingaben getätigt haben. Von diesen Eingaben werden 21 als ungültig angesehen, da sie ohne das Anhören der Audioaufnahmen getätigt wurden und somit keine validen Aussagen darstellen, und weitere 37, da diese von einer Person getätigt wurden, die als Muttersprache nur cinese angegeben hat und italiano unter der Kategorie Fremdsprachen verzeichnet hat. Nach Filterung der ungültigen Eingaben bleibt demnach noch eine Anzahl von 2521 Eingaben übrig, die in die Analyse einfließen wird und insgesamt 38 Teilnehmer widerspiegelt. Von diesen 2521 Eingaben können 1303 Eingaben dem ersten Skript und 1218 Eingaben dem zweiten Skript zugeordnet werden. Demzufolge wurde jede Audiodatei des ersten Skripts durchschnittlich zwölfmal bearbeitet, während sich die Teilnehmer im Schnitt elfmal mit den einzelnen Audioaufnahmen des zweiten Skripts befasst haben. Eine leichte Diskrepanz ist zwischen den zwei Skripten zu erkennen, doch zeigen die Durchschnittswerte, dass sich die Anzahl der abgespielten Audiodateien in derselben Größenordnung befindet und demnach allgemeine Aussagen über die aufgenommenen Audiodateien getroffen werden können.
13 von den 38 Teilnehmern, die in die letztendliche Analyse aufgenommen wurden, haben alle 108 Aufnahmen des zugewiesenen Skriptes bearbeitet, während 27 von 40 Teilnehmern weniger als 108 Aufnahmen bearbeitet haben. Die Teilnehmer, die den Perzeptionstest nicht komplett bearbeitet haben, haben dennoch mindestens zwei Aufnahmen und maximal 107 Audioaufnahmen angehört, bewertet und zugeordnet. Bei denjenigen Teilnehmern, die unter zehn Aufnahmen bearbeitet haben, kann vermutet werden, dass sie den Test als zu schwierig oder zu zeitaufwendig empfunden haben, doch bei denjenigen Teilnehmern, die über 80 Aufnahmen angehört und bearbeitet haben, liegt die Vermutung nahe, dass es einen ungewollten Abbruch des Programms gab und deswegen nicht alle Audiodateien des zugewiesenen Skriptes bearbeitet werden konnten.
Die Testteilnehmer waren zwischen 20 und 56 Jahre alt, stammen aus den Regionen Trentino-Südtirol, Lombardei, Piemont, Venetien, Emilia-Romagna, Ligurien, Toskana, Marken, Latium, Kampanien, Apulien, Basilikata, Kalabrien sowie aus Sizilien10 und haben als höchsten Abschluss entweder superiori oder università angegeben. 95,4% der Teilnehmer haben außerdem angegeben, eine oder mehrere Fremdsprachen zu sprechen, und 52,1% der Testteilnehmer haben überdies bereits in Deutschland, Österreich oder der Schweiz gewohnt. Die Testteilnehmer zeigen also eine Affinität zu Fremdsprachen auf und können als gebildet beschrieben werden. Interessant ist außerdem zu sehen, dass die Hälfte der Teilnehmer bereits in einem deutschsprachigen Land gelebt hat und damit ein Vergleich zwischen Teilnehmern mit Erfahrung in einem deutschsprachigen Land und Teilnehmern ohne Erfahrung in einem solchen Land aufgestellt werden kann.
Für die Auswertung der Daten des Perzeptionstests wurden ebendiese in die Datenbank MySQL des DHVLabs11 überführt, mit der zunächst eine Tabelle mit allen ermittelten Daten erstellt wurde und mit deren Hilfe außerdem statistische Aussagen über die erhobenen Daten getroffen werden konnten. Im Folgenden soll nun ein übergreifender Blick auf alle bearbeiteten Sprachaufnahmen in Hinblick auf die perzipierten lautlichen Differenzen und die Länderzuordnung geworfen werden, bevor die detaillierte Auswertung und Analyse der Sprachaufnahmen mit den am häufigsten markierten Graphemen oder Graphempaaren in Kapitel 4.4. Auswertung der Sprachaufnahmen folgen wird.
4.3.1. Perzeption der lautlichen Differenzen
Während der Bearbeitung des Perzeptionstests konnten die Teilnehmer verschiedene Grapheme italienischer Wörter auswählen, bei denen sie meinten, lautliche Unterschiede im Vergleich zu italienischen Muttersprachlern wahrgenommen zu haben. Das Fundament dieser Teilanalyse, die die perzipierten lautlichen Differenzen bei deutschsprachigen Italienischlernern untersucht, bilden demnach die ausgewählten italienischen Wörter und ihre anklickbaren Grapheme und Graphempaare, wie sie in Tabelle 3 Mögliche Graphemauswahl im Online-Perzeptionstest zu sehen sind.
|
Wörter |
Anklickbare Grapheme/Graphempaare |
|
terra |
<t>, <e>, <rr>, <a> |
|
terremoto |
<t>, <e>, <rr>, <e>, <m>, <o>, <t>, <o> |
|
risposta |
<r>, <i>, <s>, <p>, <o>, <s>, <t>, <a> |
|
pane |
<p>, <a>,<n>, <e> |
|
penna |
<p>, <e>, <nn>, <a> |
|
eppure |
<e>, <pp>, <u>, <r>, <e> |
|
cooperazione |
<c>, <o>, <o>, <p>, <e>, <r>, <a>, <z>, <i>, <o>, <n>, <e> |
|
ruolo |
<r>, <u>, <o>, <l>, <o> |
|
lento |
<l>, <e>, <n>, <t>, <o> |
|
cioè |
<c>, <i>, <o>, <è> |
|
tè |
<t>, <è> |
|
parchi |
<p>, <a>, <r>, <ch>, <i> |
Tabelle 3: Mögliche Graphemauswahl im Online-Perzeptionstest
Bei der Konzeption des Perzeptionstests wurde sich, wie bereits in Kapitel 4.2.1. Konzeption des Perzeptionstests erläutert wurde, dafür entschieden, sowohl einzelne Grapheme als auch Graphempaare, die in diesem Fall als zwei zusammenhängende Grapheme, die einen Laut widerspiegeln oder einen Doppelkonsonanten darstellen, aufgefasst werden, zum Anklicken bereitzustellen. Eine Ausnahme bei der Zusammenschließung von zwei Graphemen wurde allerdings bewusst bei dem Wort cioè, für den Laut /tʃ/, gemacht, da eine Sprachaufnahme die Aussprache [tʃio’ɛː] aufzeigt und die Möglichkeit gegeben werden sollte, diesen Unterschied markieren zu können. Die distinktiven Grapheme bzw. Graphempaare, die während des Online-Perzeptionstests ausgewählt werden konnten, sind also die folgenden: <a>, <c>, <ch>, <e>, <è>, <i>, <l>, <m>, <n>, <nn>, <o>, <p>, <pp>, <r>, <rr>, <s>, <t>, <u>, <z>.
Über die Zeitspanne von zweieinhalb Wochen wurde, trotz der Komplikationen, die während des Perzeptionstests aufgetreten sind, 806 Mal, bei einer Gesamtanzahl von 2521 Eingaben, mindestens ein Graphem oder ein Graphempaar nach Anhören einer Sprachaufnahme markiert und somit die Aussage getroffen, dass bei diesem markierten Graphem bzw. Graphempaar ein lautlicher Unterschied in Hinblick auf die italienische Aussprache festgestellt werden kann. In der untenstehenden Tabelle 4 Anzahl aller markierten Grapheme und Graphempaare sind alle Grapheme und Graphempaare mit ihrer entsprechenden Anzahl von Markierungen verzeichnet und es kann festgestellt werden, dass das Graphem <o> mit 282 Markierungen am häufigsten im Online-Perzeptionstest in Hinblick auf einen lautlichen Unterschied ausgewählt wurde. Dies deutet darauf hin, dass die deutschsprachigen Italienischlerner vermutlich Schwierigkeiten bei der Realisierung und Unterscheidung der Laute [o] und [ɔ] hatten. An zweiter Stelle folgt mit 188 Markierungen das Graphem <r>, wobei das Graphempaar <rr> zusätzlich 139 Mal markiert wurde und folglich gesagt werden kann, dass der r-Laut 327 Mal ausgewählt wurde und damit den am häufigsten markierten Laut darstellt. Dies ist wenig überraschend, da der Vibrant [r] in der deutschen Sprache nur selten Verwendung findet und dadurch schon immer eine Schwierigkeit für deutschsprachige Italienischlerner dargestellt hat. An dritter Stelle steht das Graphem <e> mit 184 Markierungen, das wiederum auf Unterscheidungsschwierigkeiten in Bezug auf [e] und [ɛ] hindeutet und außerdem vermuten lässt, dass sich manchmal der Laut [ə] hinter dem Graphem verbirgt. Beachtet werden sollte zudem das Graphem <t>, das sich mit einer Gesamtanzahl von 106 Markierungen an vierthöchster Stelle befindet und das Graphem <è>, das 98 Mal markiert wurde und erneut ein Hinweis darauf ist, dass die deutschen Lerner Schwierigkeiten bei der Differenzierung von [e] und [ɛ] haben könnten.
|
Graphem/ |
Anzahl der Markierungen |
Graphem/ |
Anzahl der Markierungen |
|
<a> |
75 |
<o> |
282 |
|
<c> |
26 |
<p> |
44 |
|
<ch> |
4 |
<pp> |
22 |
|
<e> |
184 |
<r> |
188 |
|
<è> |
98 |
<rr> |
139 |
|
<i> |
26 |
<s> |
14 |
|
<l> |
5 |
<t> |
106 |
|
<m> |
8 |
<u> |
39 |
|
<n> |
10 |
<z> |
27 |
|
<nn> |
34 |
|
|
Tabelle 4: Anzahl aller markierten Grapheme und Graphempaare
Unter den ausgewerteten Aufnahmen befinden sich 263 Sprachaufnahmen, die aus Deutschland stammen, 258 Aufnahmen aus Österreich und 285 Aufnahmen aus der Schweiz. 341 dieser Aufnahmen wurden von den italienischen Muttersprachlern nach Deutschland verortet, während 130 Sprachaufnahmen Österreich und 116 Sprachaufnahmen der Schweiz zugewiesen wurden. 155 Mal haben die Teilnehmer zudem angegeben, dass sie die Audiodatei keinem Land zuordnen können und in zehn Fällen gibt es keine Daten, die die Länderzuordnung betreffen.
Im Folgenden soll nun einerseits ein Blick darauf geworfen werden, welche Grapheme und Graphempaare überwiegend den verschiedenen Ländern zugewiesen wurden, da, wie in Kapitel 4.3.2. Länderzuordnung der Sprachaufnahmen erläutert werden wird, nur wenige Aufnahmen ihrem Land korrekt zugeordnet wurden, und andererseits aufgezeigt werden, welche Grapheme und Graphempaare bei den Sprechern der jeweiligen Ländern ausgewählt wurden. Zum einen wird also die Wahrnehmung der Italiener betrachtet werden und gleichzeitig untersucht werden, welche lautlichen Merkmale sie vor allem mit den unterschiedlichen deutschsprachigen Ländern verbinden, und zum anderen wird ausgewertet werden, welche lautlichen Interferenzen bei den Italienischlernern aus Deutschland, Österreich und der Schweiz tatsächlich festgestellt werden konnten.
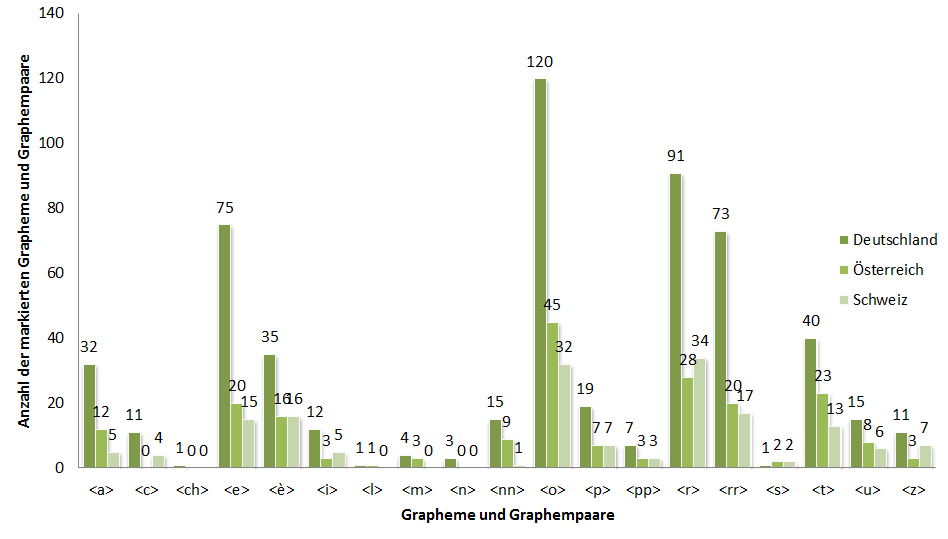
Verteilung der markierten Grapheme und Graphempaare nach Ländern
Abbildung 4 zeigt die Verteilung der markierten Grapheme und Graphempaare nach Ländern auf, die von den Testteilnehmern nach Anhören der Sprachaufnahmen in Kombination mit den genannten Graphemen und Graphempaaren ausgewählt wurden. Dieses Diagramm stellt nicht die Verteilung der markierten Grapheme und Graphempaare der Sprachaufnahmen dar, die ihrem Herkunftsland korrekt zugeordnet wurden, sondern gibt einen Eindruck über die individuelle Perzeption der Testteilnehmer und stellt eine Verbindung zwischen der Auswahl der Grapheme bzw. Graphempaare und dem ausgewählten Land her. Insgesamt haben die Testteilnehmer 936 Grapheme und Graphempaare markiert, die sie den Ländern Deutschland, Österreich oder Schweiz zugeordnet haben. Dabei wurde eine Anzahl von 566 Graphemen und Graphempaaren Deutschland zugeordnet, während 203 Grapheme und Graphempaare Österreich und 167 Grapheme und Graphempaare der Schweiz zugewiesen wurden.
Bei Betrachtung von Abbildung 4 kann festgestellt werden, dass die italienischen Muttersprachler in 120 Fällen die angehörten Sprachaufnahmen nach Deutschland verortet haben, wenn sie das <o> markiert haben. Noch häufiger als das <o>, wurden, sofern sie zusammen betrachtet werden, das Graphem <r> und das Graphempaar <rr> ausgewählt, wenn eine Verortung der Sprecher nach Deutschland stattgefunden hat. Im Vergleich zu Österreich und der Schweiz lässt sich hier ein großer Unterschied erkennen. So wurde in insgesamt 164 Fällen das Land Deutschland ausgewählt, wenn ein lautlicher Unterschied beim r-Laut festgestellt werden konnte, doch nur in 48 Fällen Österreich und in 51 Fällen die Schweiz. Die italienischen Testteilnehmer scheinen demnach grundsätzlich lautliche Unterschiede in Hinblick auf den r-Laut mit Sprechern aus Deutschland zu verbinden. Besonders häufig wurde auch das Graphem <e> mit Deutschland verbunden. In 75 Fällen meinten die italienischen Testteilnehmer, einen deutschen Sprecher zu erkennen, während dieses Graphem lediglich 20 Mal mit Österreich und 15 Mal mit der Schweiz in Verbindung gebracht wurde. Das Konsonantengraphem <t> wurde ebenfalls relativ oft markiert und 40 Mal Deutschland zugewiesen, während es Österreich lediglich 23 Mal und der Schweiz 13 Mal zugeordnet wurde. Das bedeutet, dass in mehr als der Hälfte aller Zuordnungen, genauer gesagt bei 52,6% aller Zuordnungen, das Graphem <t> und der sich dahinter verbergende Plosiv /t/ als deutsch wahrgenommen wurden. Überraschend ist außerdem die hohe Markierungsrate des Graphems <a> und seine gehäufte Zuordnung zu Deutschland. In 32 Fällen wurden lautliche Unterschiede, die beim Graphem <a> erkannt werden konnten, mit Deutschland gleichgesetzt, während lautliche Unterschiede in nur zwölf Fällen mit Österreich und lediglich in fünf Fällen mit der Schweiz in Verbindung gebracht wurden.
Betrachtet man die Grapheme und Graphempaare, die besonders selten einem Land zugeordnet wurden, wie beispielsweise <ch>, <l>, <n> und <s> , kann die Vermutung geäußert werden, dass die durch die Grapheme und Graphempaare abgebildeten Laute nicht zu den typischen lautlichen Erkennungsmerkmalen deutschsprachiger Sprecher zählen, da sie einerseits sehr selten markiert wurden und damit größtenteils unauffällig sind und andererseits weder nach Italien noch in ein deutschsprachiges Land verortet werden konnten und demzufolge nicht charakteristisch für ebendiese zu sein scheinen. Dieser Aussage muss allerdings hinzugefügt werden, dass diese Grapheme wesentlich seltener in den ausgewählten Wörtern vorzufinden sind und demzufolge eine geringere Markierungsrate zu erwarten war.
Rekapituliert man die Ergebnisse, die in Abbildung 4 veranschaulicht werden, kann die Aussage getroffen werden, dass die italienischen Testteilnehmer jegliche lautlichen Unterschiede, die sie beim Anhören der Sprachaufnahmen feststellen konnten, in erster Linie mit Deutschland in Verbindung gebracht haben. In der Tat haben die Testteilnehmer in 60,5% der Fälle gesagt, dass der Sprecher aus Deutschland stammt, während nur 21,7% aller lautlichen Unterschiede mit Österreich und 17,8% aller lautlichen Unterschiede mit der Schweiz verbunden wurden. Doch welche Grapheme und Graphempaare wurden tatsächlich bei den Sprachaufnahmen der Sprecher aus Deutschland, Österreich und der Schweiz ausgewählt und zeigen lautliche Unterschiede bei ebendiesen auf12?
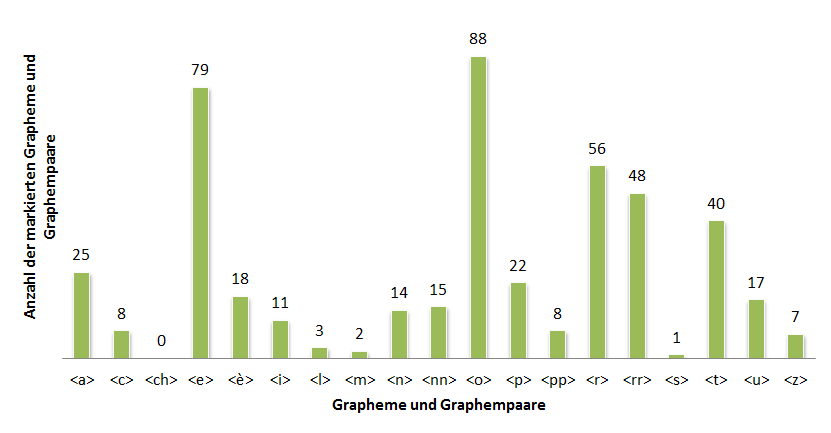
Verteilung der markierten Grapheme und Graphempaare bei Sprechern aus Deutschland
Abbildung 5 zeigt die Grapheme und Graphempaare auf, die bei den Sprechern aus Deutschland markiert wurden. Dies bedeutet nicht, dass die Anzahl der oben vermerkten Grapheme und Graphempaare den Sprechern aus Deutschland korrekt zugeordnet wurde, sondern lediglich, dass bei den Aufnahmen mit den Kennziffern 0001 bis 0006, die für die Sprecher aus Deutschland stehen, die oben dargestellten Grapheme und Graphempaare ausgewählt wurden, auch wenn die Teilnehmer die angehörten Sprachaufnahmen eventuell einem anderen Land zugewiesen haben.
Insgesamt wurden 462 Grapheme bzw. Graphempaare bei den Sprechern aus Deutschland markiert. Einzeln betrachtet wurden die Grapheme <o>, <e> und <r> am häufigsten markiert. Das Graphem <o> wurde insgesamt 88 Mal ausgewählt, was einen Anteil von 19% darstellt, das Graphem <e> 79 Mal, das damit einen Anteil von 17% ausmacht, und das Graphem <r> 56 Mal, das somit in 12% aller Fälle ausgewählt wurde. Wird das Graphem <r> und das Graphempaar <rr> allerding zusammen betrachtet, da beide Grapheme den gleichen Laut darstellen, erhält man die Anzahl 104, die den höchsten Wert im gesamten Diagramm darstellt und einen Anteil von 22,5% widerspiegelt. Interessant ist außerdem zu sehen, dass weitere Vokale, wie <a>, <è>, <i> und <u> nur selten ausgewählt wurden und, einzeln betrachtet, maximal einen Anteil von 5% der ausgewählten Grapheme und Graphempaare darstellen. Daraus kann geschlussfolgert werden, dass bei den Sprechern aus Deutschland, in Hinblick auf die Vokalrealisation, vor allem lautliche Interferenzen bei den Vokalen <e> und <o> ausgemacht werden konnten und diese in der späteren Analyse der Sprachaufnahmen besonders beleuchtet werden sollten.
Was die Konsonantenrealisation betrifft, können Ausspracheunterschiede vor allem beim r-Laut festgestellt werden. Der Plosiv <t> steht zudem an vierter Stelle der am häufigsten markierten Grapheme und Graphempaare und wurde in 8,7% der Fälle ausgewählt. Das Graphem <p> und das Graphempaar <pp> konnten zusammengerechnet außerdem nur einen Anteil von 6,5% ausmachen und untermauern damit die Hypothese, dass sich süddeutsche Sprecher der italienischen Aussprache in Hinblick auf Plosive besser anpassen können, da in süddeutschen Akzenten normalerweise keine Aspiration vorhanden ist. Außerdem lässt die Auswertung erkennen, dass die Aussprache des Plosivs /p/ tatsächlich seltener als die Aussprache des Plosivs /t/ zu Markierungen geführt hat.
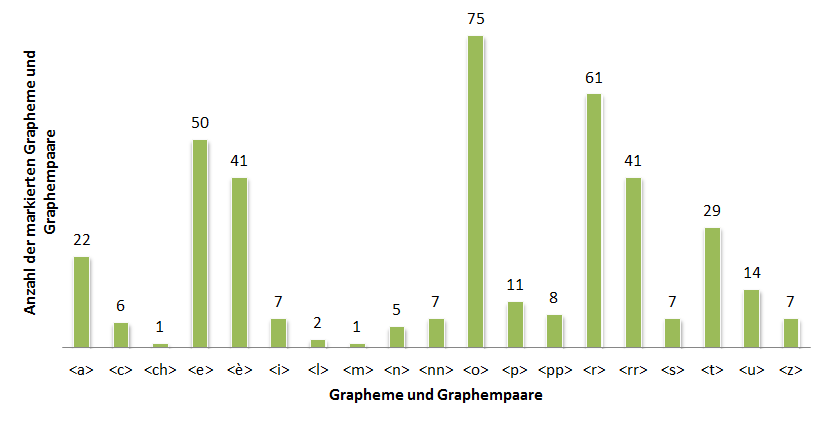
Verteilung der markierten Grapheme und Graphempaare bei Sprechern aus Österreich
Abbildung 6 stellt, angelehnt an Abbildung 5, die Verteilung der markierten Grapheme und Graphempaare bei den Sprechern aus Österreich dar. Insgesamt wurden bei den österreichischen Sprechern 395 Grapheme bzw. Graphempaare markiert. Vergleicht man Abbildung 5 und Abbildung 6 miteinander, kann zunächst festgestellt werden, dass die Verteilung der markierten Grapheme und Graphempaare einer sehr ähnlichen Tendenz folgt. Sowohl in Abbildung 5 als auch in Abbildung 6 wurde das Graphem <o> am häufigsten markiert und die Grapheme <e> und <r> befinden sich erneut an zweiter und dritter Stelle der am häufigsten ausgewählten Grapheme. Unterschiede zwischen der Zuordnung der Grapheme und Graphempaare bei den Sprechern aus Deutschland und den Sprechern aus Österreich lassen sich dennoch feststellen.
Auffällig bei der Betrachtung von Abbildung 6 ist zunächst der Anteil an Markierungen, der sowohl das Graphem <e> als auch das Graphem <è> betrifft. In Abbildung 5 konnte eine hohe Markierungsrate für das Graphem <e> festgestellt werden, doch war gleichzeitig zu sehen, dass das Graphem <è> selten markiert wurde. Bei den österreichischen Sprechern wurden beide Grapheme oftmals ausgewählt und unterscheiden sich in ihrer Anzahl kaum. Aufgrund des Diagramms kann also die Aussage getroffen werden, dass bei den österreichischen Sprechern häufiger lautliche Interferenzen bei den vokalischen Graphemen <e> und <è> aufgetreten sind und dies ein Indiz dafür sein könnte, dass den österreichischen Sprechern die Unterscheidung zwischen [e] und [ɛ] schwieriger fällt als den Sprechern aus Deutschland. Interessant ist außerdem zu sehen, dass selbst das Graphem <è> 41 Mal ausgewählt wurde, obwohl es bereits die offene Aussprache des Vokals anzeigt. Bedenkt man allerdings, dass das österreichische Vokalsystem durch das Fehlen von [ɛ] gekennzeichnet ist und sich die Wiener durch eine besonders geschlossene Aussprache des Phonems /e/ auszeichnen, ist die hohe Markierungsrate wenig überraschend. Aus diesem Grund kann darüber hinaus gemutmaßt werden, dass die österreichischen Italienischlerner generell Schwierigkeiten bei der Unterscheidung und Aussprache von offenen und geschlossenen Vokalen haben und dies sich auch in der Anzahl der markierten <o>s widerspiegelt. Die restlichen Vokalgrapheme wurden, wie auch bei den Sprechern aus Deutschland, nur selten markiert und stellen demzufolge keine größeren Probleme in Hinblick auf Interferenzen bei lautlichen Merkmalen im Italienischen dar.
Wendet man sich den Konsonanten zu, kann beobachtet werden, dass auch bei den österreichischen Sprechern vielfach das Graphem <r> und das Graphempaar <rr> markiert wurden. Zusammengerechnet wurden sie 102 Mal ausgewählt und stellen einen Anteil von 25,8% dar. Der r-Laut ist demnach nicht nur für die Sprecher aus Deutschland, sondern auch für die Sprecher aus Österreich charakteristisch und wird von den italienischen Testteilnehmern am häufigsten als lautliches Merkmal ausgewählt, bei dem Interferenzen festgestellt werden können. Die Plosive <p>, <pp> und <t> wurden bei den österreichischen Sprechern sowohl prozentual als auch absolut gesehen, seltener als bei den Sprechern aus Deutschland markiert, was den Schluss zulässt, dass die Aussprache der Plosive /p/ und /t/ der Italienischlerner aus Österreich nahe an der italienischen Aussprache liegt. Die markierten <p>s und <t>s können auf alle sechs österreichischen Probanden zurückgeführt werden, doch ist interessant zu sehen, dass Sprecher 0009 beispielsweise nur ein markiertes <t>, zwei markierte <p>s und ebenfalls zwei markierte <pp>s zugewiesen wurden und anderen Sprechern bis zu neun markierte <t> zugeordnet wurden. Bei den österreichischen Sprechern kann also eine gewisse Heterogenität in Hinblick auf die ausgewählten Plosive festgestellt werden.
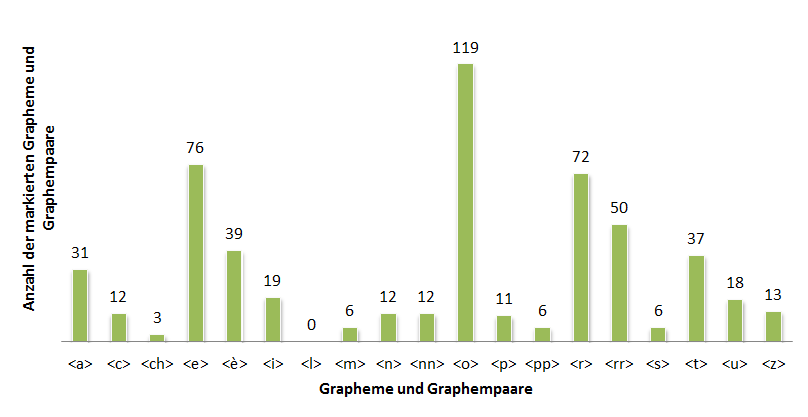
Verteilung der markierten Grapheme und Graphempaare bei Sprechern aus der Schweiz
Die oben zu sehende Abbildung 7 veranschaulicht zuletzt die Verteilung der ausgewählten Grapheme und Graphempaare bei den Sprechern aus der Schweiz. Im Vergleich zu Abbildung 5, die die Verteilung Deutschlands aufzeigt, und Abbildung 6, die die Verteilung bei den österreichischen Sprechern darstellt, kann bei der Verteilung der Grapheme und Graphempaare bei den Sprechern aus der Schweiz festgestellt werden, dass auch hier die Grapheme <o>, <e> und <r> sowie das Graphempaar <rr> die meisten Markierungen erhalten haben. Insgesamt wurden 542 Grapheme und Graphempaare bei den Aufnahmen der Italienischlerner aus der Schweiz ausgewählt, was die höchste Anzahl an Markierungen aller drei Länder darstellt. Das Graphem <o> wurde in 22% aller Fälle ausgewählt, während das Graphem <e> in 14% aller Fälle und das Graphem <r>, zusammengerechnet mit dem Graphempaar <rr>, in 22,5% aller Fälle markiert wurde. Interessant ist im Falle der Schweiz und in Hinblick auf die Grapheme <o> und <r> sowie das Graphempaar <rr> zu sehen, dass sich die Werte kaum voneinander unterscheiden. Sowohl bei der Verteilung der Grapheme und Graphempaare in Deutschland als auch in Österreich wurde der r-Laut immer eindeutig am häufigsten markiert, doch in der Schweiz kann das Graphem <o> einen fast gleich hohen Wert verzeichnen. Dies könnte mit der Tatsache zusammenhängen, dass die Länge der Vokale im schweizerischen Standarddeutsch stark von der deutschen Standardaussprache differiert und damit eventuell auch im Italienischen zu lautlichen Differenzen führt. Es sollte außerdem erwähnt werden, dass beide Werte, sofern die absoluten Zahlen betrachtet werden, in der Schweiz höher als in Deutschland und Österreich sind.
Wendet man sich den Vokalen zu, kann auch in der Schweiz festgestellt werden, dass das Graphem <e> sehr oft markiert wurde. Die restlichen Vokalgrapheme wurden, wie auch bei der Verteilung der Grapheme und Graphempaare in Deutschland und Österreich gesehen werden konnte, selten markiert, wobei das Graphem <a> aber einen Wert von 31 aufzeigt und das Graphem <è> 39 Mal markiert wurde. Das Verteilungsverhältnis zwischen den Markierungen von <e> und <è> liegt zwischen dem von Deutschland, wo der Unterschied besonders groß war, und dem von Österreich, wo nur ein sehr geringer Unterschied in der Anzahl der Markierungen von <e> und <è> festgestellt werden konnte.
Bei der Verteilung der Konsonantengrapheme kann hingegen bemerkt werden, dass das Graphem <p> und das Graphempaar <pp> noch seltener als in Österreich ausgewählt wurden, und demnach die Schlussfolgerung getroffen werden kann, dass die eigentliche Aussprache des Plosivs /p/ sowohl bei österreichischen als auch schweizerischen Italienischlernern nur in geringem Maße zu Interferenzen im Italienischen führt. Der Plosiv <t> wurde bei den Sprechern aus der Schweiz insgesamt 37 Mal ausgewählt. Dieser Wert liegt damit über dem Wert aus Österreich und knapp unter dem Wert aus Deutschland. Es kann also die Aussage getroffen werden, dass es bei schweizerischen und deutschen Italienischlernern öfter als bei den österreichischen Italienischlernern zu perzipierbaren Differenzen bei dem Plosiv /t/ kommt. Dies könnte an einer stärkeren Aspiration der deutschen und schweizerischen Sprecher im Allgemeinen liegen und soll in der detaillierten Auswertung der Sprachaufnahmen genauer analysiert werden.
Zusammenfassend kann in Hinblick auf die erwarteten Interferenzen bei lautlichen Merkmalen gesagt werden, dass bei den Sprechern aus der Schweiz am häufigsten die Aussage getroffen wurde, dass Unterschiede bei lautlichen Merkmalen bestehen und bei den Sprechern aus Österreich der niedrigste Wert an Markierungen festgestellt werden konnte. Dieses Ergebnis wird durch die Inkonsistenz der Markierungen, die im Verlauf des Perzeptionstests durch diverse Probleme entstanden ist, beeinflusst, doch kann festgehalten werden, dass für Deutschland 266 Eingaben, für Österreich 259 Eingaben und für die Schweiz 285 Eingaben für den Vergleich der Verteilung der Grapheme und Graphempaare herangezogen wurden und es deswegen zwar wahrscheinlich war, dass die Schweiz mehr Markierungen als Deutschland und Österreich haben würde, aber durch den Unterschied von 19 Eingaben die Aussage, dass bei den Sprechern aus der Schweiz die meisten Markierungen vorzufinden sind und bei ihnen demzufolge auch die meisten Interferenzen bei lautlichen Merkmalen bestehen, nicht an Korrektheit verliert.
Des Weiteren kann festgehalten werden, dass die Grapheme bzw. Graphempaare <o>, <e>, <r> und <rr> für alle drei Länder am häufigsten markiert wurden und infolgedessen als die Grapheme und Graphempaare aufgefasst werden können, bei denen es bei deutschsprachigen Sprechern im Allgemeinen zu lautlichen Differenzen kommt. Da die ausgewählten Grapheme und Graphempaare keinen klaren Rückschluss auf das Phonem zulassen, das sich hinter dem Graphem bzw. Graphempaar verbirgt, sollen die oben aufgelisteten Grapheme und Graphempaare in Kapitel 4.4. Auswertung der Sprachaufnahmen analysiert und aufbereitet werden.
Interessant war zudem zu sehen, dass die Testteilnehmer lautliche Unterschiede bei den Graphemen <o>, <e>, <r> sowie dem Graphempaar <rr> überwiegend mit Deutschland in Verbindung gebracht haben, obwohl nach der Analyse festgestellt werden konnte, dass diese lautlichen Unterschiede in allen Ländern markiert wurden und in einem ähnlichen Verhältnis zueinander stehen.
Im Folgenden soll nun auf die zweite Aufgabe des Online-Perzeptionstests, der Zuordnung der Sprecher zu ihrem Herkunftsland, Bezug genommen und die Frage beantwortet werden, ob italienische Muttersprachler die Herkunft eines deutschsprachigen Italienischlerners anhand eines einzigen Wortes präzise erkennen können.
4.3.2. Länderzuordnung der Sprachaufnahmen
Aufgrund der in Kapitel 4.2.3. Komplikationen bei der Durchführung des Perzeptionstests erläuterten Probleme, weisen nur 2362 der insgesamt 2521 Eingaben Länderzuweisungen bzw. die Option Non assegnabile auf. Unter diesen Eingaben befindet sich eine Gesamtzahl von 793 Aufnahmen aus Deutschland, 783 Aufnahmen aus Österreich und 786 Aufnahmen aus der Schweiz. Die Testteilnehmer haben von diesen Sprachaufnahmen insgesamt 632 nach Deutschland, 288 nach Österreich und ebenfalls 288 in die Schweiz verortet, während 870 Mal gesagt wurde, dass die Aufnahmen von Italienern stammen. 284 Mal konnten die Sprachaufnahmen demnach keinem Land zugewiesen werden und sie wurden mit dem Begriff Non assegnabile versehen. In 25% aller verzeichneten Fälle haben sich die Testteilnehmer demgemäß für das Land Deutschland, in 11,4% für das Land Österreich, in ebenfalls 11,4% für die Schweiz und in 34,5% für das Land Italien als Herkunftsland der Sprecher entschieden. Auffällig beim ersten Blick auf die Ergebnissen dieser Länderzuordnung ist zum einen, dass die Sprachaufnahmen verhältnismäßig selten Österreich oder der Schweiz zugeordnet wurden und auch zusammen nicht die Anzahl an Zuordnungen von Deutschland erreichen, und zum anderen, dass der prozentuale Anteil der Antwort Italia alle Einzelwerte der deutschsprachigen Länder übersteigt. Die Testteilnehmer haben demzufolge am häufigsten, sofern alle Daten zusammen betrachtet werden und individuelle Ergebnisse vernachlässigt werden, keine lautlichen Differenzen vernommen und die Sprachaufnahmen öfter nach Italien als in ein deutschsprachiges Land verortet. Allerdings muss dieser Beobachtung hinzugefügt werden, dass die Wahl zwischen drei deutschsprachigen Ländern bestand und der prozentuale Anteil aufgrund dessen aufgeteilt wurde. Wäre nur die Frage gestellt worden, ob es sich um einen Sprecher aus Italien oder aus einem deutschsprachigen Land handelt, hätte Italien 34,5% und die deutschsprachigen Länder zusammen 47,8% erhalten und wären somit insgesamt häufiger genannt worden13.
Doch in wie vielen Fällen konnten die Testteilnehmer die Sprachaufnahmen dem richtigen Land zuordnen und konnten Sprecher eines bestimmten Landes oder bestimmte Sprecher besonders oft korrekt ihrem Herkunftsland zugewiesen werden?
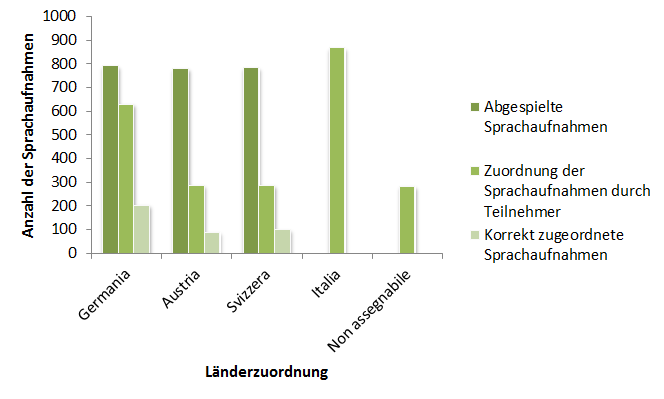
Übersicht über die korrekte und inkorrekte Zuordnung der Länder durch die Testteilnehmer
Insgesamt wurden 16,6% der Sprachaufnahmen dem passenden Herkunftsland der Sprecher zugeordnet, wobei die Sprecher aus Deutschland in 25,7% aller Fälle, die Sprecher aus Österreich in 11,4% aller Fälle und die Sprecher aus der Schweiz in 12,7% aller Fälle ihrem Land korrekt zugeteilt wurden. Diese Werte lassen die Interpretation zu, dass die italienischen Testteilnehmer als Kollektiv die deutschsprachigen Italienischlerner anhand ihrer Aussprache nicht mit Sicherheit ihrem Herkunftsland zuordnen konnten. Die Italienischlerner aus Deutschland wurden, im Vergleich zu den Sprechern aus Österreich und der Schweiz, am häufigsten korrekt zugeordnet, doch konnte der Sprecher auch hier nur in einem von vier Fällen korrekt zugewiesen werden. Die höhere Prozentzahl an korrekten Zuweisungen in Hinblick auf die deutschen Sprecher liegt außerdem in der Tatsache begründet, dass überdurchschnittlich viele Markierungen dem Land Deutschland zugewiesen wurden und demnach, selbst wenn die italienischen Testteilnehmer bei der Länderzuordnung Unsicherheit verspürt und vielleicht geraten haben, tendenziell immer ein höherer prozentualer Wert für die korrekte Zuordnung der Sprachaufnahmen nach Deutschland zu erwarten wäre.
Nun stellt sich natürlich die Frage, in wie vielen Fällen die deutschsprachigen Sprecher ihrem Herkunftsland tatsächlich korrekt zugeordnet wurden und wie häufig sie den jeweils anderen Ländern zugewiesen wurden. Die genaue Aufteilung dieser Verortungen nach einzelnen Sprechern kann in Tabelle 5 Verortung der deutschsprachigen Italienischlerner vorgefunden werden.
|
Sprecher |
Herkunft |
Anzahl |
Anzahl |
Anzahl der Ver-ortungen nach CH16 |
Anzahl |
Korrekt verortet |
|
0001 |
Deutschland |
34 |
15 |
19 |
41 |
31,2% |
|
0002 |
Deutschland |
26 |
13 |
19 |
61 |
21,8% |
|
0003 |
Deutschland |
14 |
11 |
9 |
83 |
12% |
|
0004 |
Deutschland |
42 |
21 |
18 |
29 |
38,2% |
|
0005 |
Deutschland |
44 |
16 |
16 |
50 |
35% |
|
0006 |
Deutschland |
44 |
15 |
13 |
49 |
36,4% |
|
0007 |
Österreich |
40 |
18 |
9 |
46 |
16% |
|
0008 |
Österreich |
38 |
14 |
15 |
52 |
11,8% |
|
0009 |
Österreich |
19 |
10 |
7 |
86 |
8,2% |
|
0010 |
Österreich |
36 |
9 |
17 |
43 |
8,6% |
|
0011 |
Österreich |
25 |
17 |
19 |
50 |
15,3% |
|
0012 |
Österreich |
43 |
21 |
27 |
22 |
18,6% |
|
0013 |
Schweiz |
60 |
28 |
20 |
13 |
16,5% |
|
0014 |
Schweiz |
35 |
21 |
20 |
44 |
16,7% |
|
0015 |
Schweiz |
19 |
7 |
15 |
72 |
13,3% |
|
0016 |
Schweiz |
15 |
18 |
16 |
59 |
14,8% |
|
0017 |
Schweiz |
31 |
8 |
14 |
60 |
12,4% |
|
0018 |
Schweiz |
67 |
26 |
15 |
10 |
12,7% |
Tabelle 5: Verortung der deutschsprachigen Italienischlerner
Nach Betrachtung der Tabelle kann konstatiert werden, dass vier von den sechs vorhandenen Sprechern aus Deutschland zu über 30% ihrem Herkunftsland zugeordnet werden konnten und dadurch den Gesamtdurchschnitt für die Länderzuordnung der Sprecher aus Deutschland heben. Allgemein kann allerdings die Aussage getroffen werden, dass die Länderzuordnung für die italienischen Testteilnehmer schwierig war und vor allem die Österreicher nicht ihrem Herkunftsland zugeordnet werden konnten. Die österreichischen Sprecher wurden prozentual gesehen zu 16%, 11,8%, 8,2%, 8,6%, 15,3% und 18,6% korrekt zugeordnet und unterscheiden sich demnach in manchen Fällen stark untereinander. Dies ist besonders interessant, da von einigen Testteilnehmern die Rückmeldung kam, dass die Länderzuordnung zwar schwierig war, aber sie die Österreicher noch am sichersten erkennen konnten. Die fehlerhafte Zuordnung der Sprecher aus Österreich könnte einerseits mit dem Sprachniveau der Probanden zusammenhängen, da jeder einzelne österreichische Sprecher öfter nach Italien als in sein eigenes Herkunftsland verortet wurde und andererseits mit der Tatsache, dass die italienischen Testteilnehmer viele perzipierte lautliche Unterschiede fast automatisch mit Italienischlernern aus Deutschland verbunden haben und aus diesem Grund überdurchschnittlich oft das Land Deutschland und nicht die Länder Österreich und die Schweiz ausgewählt haben. Die gleichen Phänomene können auch bei den Sprechern aus der Deutschschweiz festgestellt werden, obwohl dieser Beobachtung hinzugefügt werden muss, dass die häufige Verortung nach Italien und nach Deutschland geringer als bei den österreichischen Sprechern ausgefallen ist. Vier der sechs schweizerischen Sprecher wurden öfter nach Italien als in ihr Herkunftsland verortet und gleichzeitig wurden fünf von sechs Sprechern ebenfalls häufiger dem Land Deutschland als dem Land Schweiz zugewiesen. Es kann demnach eine sehr ähnliche Tendenz der Zuordnung zwischen den österreichischen und schweizerischen Sprechern festgestellt werden, wobei die Ausprägung der Länderzuordnung bei den österreichischen Sprechern noch deutlicher ist.
Da diese Studie auch Antwort auf die Frage geben soll, ob und falls ja, in welchen Situationen und unter welchen Bedingungen, die deutschsprachigen Sprecher die italienische Aussprache so gut beherrschen können, dass ihr L2 Akzent nicht mehr perzipiert werden kann und sie demzufolge nicht mehr als deutschsprachige Italienischlerner erkannt werden können, soll im Folgenden nun die Zuordnung der Probanden nach Italien im Vordergrund stehen und diskutiert werden, warum manche Sprecher überwiegend und andere Sprecher nur sehr selten nach Italien verortet wurden.
Kurz muss allerdings darauf hingewiesen werden, dass Einträge von italienischen Testteilnehmern existieren, bei denen alle Grapheme oder ein Graphem eines Wortes ausgewählt wurden und diese dennoch nach Italien verortet wurden, obwohl die Aufgabenstellung deutlich besagte, dass Grapheme nur dann ausgewählt werden sollten, wenn ein accento straniero, sprich ein ausländischer Akzent, auf Seiten der Sprecher vernommen werden konnte. 43 der insgesamt 2521 Eingaben sind davon betroffen und werden, aufgrund ihrer geringen Anzahl, als ungültig angesehen werden und nur in der Hinsicht in die Analyse einfließen, dass die markierten Grapheme für die betroffenen Sprecher in der späteren detaillierten Analyse der Sprachaufnahmen zählen werden. Diese Abweichungen könnten mit der Tatsache zusammenhängen, dass die Teilnehmer, die oftmals alle Grapheme eines Wortes oder nur ein Graphem eines Wortes markiert haben, obwohl ansonsten keine Grapheme von ihnen übertragen wurden, technische Probleme hatten und deswegen von der Logik abweichende Eingaben getätigt haben. Auffallend ist außerdem, dass 25 der 43 Eingaben von einem Testteilnehmer stammen und vermutet werden kann, dass dieser die Aufgabenstellung nicht gelesen oder nicht verstanden hat.
Wendet man sich der Auswertung der Daten zu, kann nichtsdestotrotz konstatiert werden, dass die Sprecher aus Deutschland insgesamt 313 Mal, die Sprecher aus Österreich 299 Mal und die Sprecher aus der Schweiz 258 Mal nach Italien verortet wurden. Dies bedeutet, dass die deutschen Sprecher in 39,5% aller Fälle, die österreichischen Sprecher in 38,2% aller Fälle und die schweizerischen Sprecher in 32,8% aller Fälle dem Land Italien zugewiesen wurden und keine lautlichen Differenzen bei ihnen festgestellt werden konnten. Die deutschen Sprecher wurden demnach am häufigsten nach Italien verortet, wobei angemerkt werden muss, dass sich der Anteil von deutschen und österreichischen Sprechern, der mit Italien in Verbindung gebracht wurde, kaum voneinander unterscheidet und sich auch der Anteil der Schweizer in der gleichen Größenordnung befindet und lediglich einen Unterschied von 5,4% aufweist. Betrachtet man die sprecherspezifische Zuweisung der Sprachaufnahmen nach Italien, die in Abbildung 9 veranschaulicht wird, ist zu sehen, dass große Unterschiede in Hinblick auf die einzelnen Sprecher und ihre Verortung nach Italien bestehen.
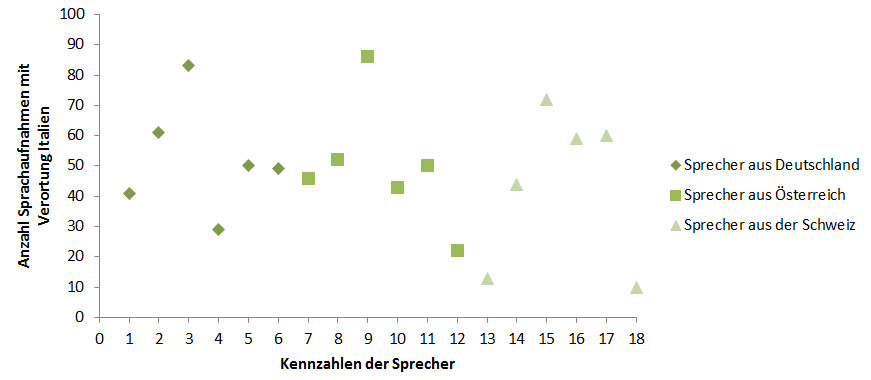
Anzahl der Sprachaufnahmen nach Sprechern mit Länderzuordnung Italien
Die deutschen Sprecher wurden zwischen 29 und 83 Mal, die österreichischen Sprecher zwischen 22 und 86 Mal und die schweizerischen Sprecher zwischen 10 und 72 Mal dem Land Italien bei der Länderzuordnung zugeteilt. In Hinblick auf die einzelnen Sprecher bestehen also Differenzen von 54, 64 und 62 Zuweisungen, was klare Unterschiede in der Stärke ihres Akzentes vermuten lässt. Das Diagramm zeigt außerdem deutlich, dass die Sprecher mit den Kennzahlen 0003, 0009 sowie 0015 im Zuge der Länderverortung am häufigsten nach Italien verortet und die Probanden 0012 und 0018 am seltensten mit dem Land Italien in Verbindung gebracht wurden. Nun stellt sich natürlich die Frage, aufgrund welcher Faktoren die Probanden 0003, 0009 und 0015 überdurchschnittlich oft nach Italien verortet wurden und warum die Probanden 0012 und 0018 nur sehr selten als Italiener angesehen wurden.
Aufschluss über die Faktoren, die dazu geführt haben können, geben uns die Fragebögen, die jeder Proband vor den Sprachaufnahmen ausfüllen musste und die persönliche Daten sowie Daten über das Sprachverhalten und die Fremdsprachenkompetenz der Probanden im Allgemeinen beinhalten. Durch den Fragebogen von Probandin 0003 erfährt man, dass sie ihren Master im Fach Romanistik absolviert und somit einen intensiven Kontakt zu romanischen Sprachen hat, ihr Sprachniveau in Italienisch zwischen C1 und C2 liegt, sie außerdem noch Spanisch spricht und auch in dieser Sprache ein Niveau zwischen B2 und C1 aufweist, dass sie seit sechs Jahren Italienisch lernt, regelmäßig Kontakt zu italienischen Muttersprachlern sowohl im In- als auch im Ausland pflegt und einen Auslandsaufenthalt von acht Monaten in Italien hatte. Auch Proband 0009 hat durch sein Studium der Translation (Konferenzdolmetschen) stetigen Kontakt zur italienischen Sprache und weist ein Sprachniveau von C1 auf. Er studiert seit fünf Jahren Italienisch, hat ebenfalls regelmäßig Kontakt zu italienischen Muttersprachlern und hatte auch einen Auslandsaufenthalt in Italien, der über elf Monate ging. Probandin 0015 studiert als einzige Sprecherin der drei am häufigsten nach Italien verorteten Sprecher keinen Studiengang, der direkt mit der italienischen Sprache verknüpft ist. Dennoch hat sie bereits das Niveau B2 in Italienisch erreicht, kann auch in Französisch ein Niveau von B2 aufweisen, lernt seit sechs Jahren Italienisch und hat regelmäßigen Kontakt zu italienischen Muttersprachlern in ihrem Wohnort. Interessant ist bei dieser Probandin zu sehen, dass sie nicht nur Deutsch sondern auch Serbisch als Muttersprache angegeben hat und, anders als die Probanden 0003 sowie 0009, keinen Auslandsaufenthalt in Italien verbracht hat. Die Probanden mit den meisten Verortungen nach Italien weisen also alle ein sehr hohes Sprachniveau auf und trotzdem kann ein Unterschied hinsichtlich der Anzahl der Verortungen nach Italien zwischen den beiden Probanden 0003 und 0009, die ein Italienischniveau von C1/C2 und C1 besitzen, und der Probandin 0015, die B2 als Niveau angegeben hat und keinen Auslandsaufenthalt in Italien absolviert hat, festgestellt werden. Die beiden Probanden 0003 und 0009 zeichnen sich also dadurch aus, dass sie seit langer Zeit Italienisch lernen, gleichzeitig Italienisch studieren, regelmäßigen Kontakt zu italienischen Muttersprachlern in ihrem Alltag haben und zudem ein langer Auslandsaufenthalt in Italien hinter ihnen liegt.
Wirft man einen Blick auf die Angaben von Probandin 0012, die aus Österreich stammt und am zweitseltensten nach Italien verortet wurde, kann allerdings festgestellt werden, dass auch Probandin 0012 durch ihr Studium stetigen Kontakt zur italienischen Sprache hat, ein Niveau von C1 im Italienischen besitzt, gleichzeitig noch Rumänisch auf B2 Niveau beherrscht und bereits seit sieben Jahren Italienisch lernt. Anhand dieser Angaben, die große Parallelen zu den am häufigsten nach Italien verorteten Probanden aufzeigen, müsste eigentlich die Vermutung aufgestellt werden, dass auch Probandin 0012 aufgrund ihres langjährigen und fortgeschrittenen Studiums des Italienischen oft mit Italien in Verbindung gebracht wird, wenn man diese Kriterien als zielgebend definieren würde, doch genau das Gegenteil ist der Fall. Dies könnte zum einen an der Tatsache liegen, dass Probandin 0012 in keinem regelmäßigen Kontakt zu italienischen Muttersprachlern steht und zum anderen an der Tatsache, dass sie keinen Auslandsaufenthalt in Italien absolviert hat. Durch den seltenen Kontakt zu italienischen Muttersprachlern und durch die mangelnde Auslandserfahrung könnte Probandin 0012, im Vergleich zu den Probanden 0003 und 0009, weniger Übung im gesprochenen Italienisch haben, wodurch der L1 Akzent der Probandin stärker in der italienischen Sprache perzipiert wird. Warum Proband 0018 die geringste Anzahl an Verortungen nach Italien erhalten hat, ist hingegen einfacher zu erklären. In seinem Studium beschäftigt er sich nicht mit der italienischen Sprache, er lernt erst seit eineinhalb Jahren Italienisch, hat keinen Auslandsaufenthalt in Italien absolviert und besitzt im Italienischen das Sprachniveau B1. Er gehört also zu den Probanden mit dem niedrigsten Sprachniveau und lernt von allen aufgenommenen Sprechern am kürzesten Italienisch. Interessant ist auch zu sehen, dass Proband 0018 fünf weitere Sprachen spricht und diese zu Interferenzen in der italienischen Sprache führen könnten.
Zusammenfassend kann also festgestellt werden, dass die Länderzuordnung von den italienischen Testteilnehmern nicht präzise durchgeführt werden konnte, jedoch viele Sprecher als italienische Muttersprachler perzipiert wurden und damit zeigen, dass deutschsprachige Italienischlerner lautliche Interferenzen, die durch ihre L1 in der Fremdsprache entstehen, vermeiden können. Welche lautlichen Differenzen aber genau bei welchen Sprechern und bei welchen Wörtern in Hinblick auf die am häufigsten markierten Grapheme und die Laute, die sich hinter ihnen verbergen, konstatiert werden können, wird die Auswertung der Sprachaufnahmen zeigen, die sich auf die Analyse von /e/ und /ɛ/, /o/ und /ɔ/, /r/ sowie auf die Analyse von /t/ konzentrieren wird.
4.4. Auswertung der Sprachaufnahmen
Die Grundlage des Perzeptionstests bilden die Sprachaufnahmen der Probanden, weswegen ebendiese nun genauer betrachtet und analysiert werden sollen. Wie bereits im vorherigen Kapitel 4.3. Perzeption der Sprachaufnahmen durch Italiener gesehen wurde, wurden die Grapheme bzw. Graphempaare <e> und <è>, <o>, <r> und <rr> sowie <t> besonders häufig und von besonders vielen Teilnehmern des Perzeptionstests markiert. Aus diesem Grund sollen nun ausgewählte Sprachaufnahmen aus Deutschland, Österreich und der Schweiz spezifisch auf die Laute, die durch diese Grapheme und Graphempaare repräsentiert werden, analysiert werden. Dabei soll festgestellt werden, wie hoch die Diskrepanz zwischen geschlossenen und offenen Vokalen bei den deutschsprachigen Sprechern tatsächlich ist und welche weiteren Laute, wie beispielsweise der Schwa-Laut, sich hinter den oben genannten Graphemen verbergen.
Alle Sprachaufnahmen wurden mit dem phonetischen Analyseprogramm Praat geschnitten, segmentiert und annotiert. Bei jeder phonetischen Analyse wurde im ersten Schritt der Anfangs- und Endpunkt des Wortes festgelegt und dieses in das erste Annotationsfeld geschrieben. Im zweiten Schnitt wurden die einzelnen Phoneme des aufgenommenen Wortes dann segmentiert und annotiert. In der folgenden Analyse werden bereits ausgewählte Screenshots und die dazugehörigen Sprachaufnahmen, die unter Anhang 5 vorgefunden werden können, zur Veranschaulichung verwendet werden. Eine tabellarische Darstellung aller transkribierten Wörter kann außerdem unter Punkt Anhang 6 vorgefunden werden.
4.4.1. Analyse von /e/ und /ɛ/
Im Verlauf des Perzeptionstests wurden insgesamt 274 Eingaben getätigt, bei denen entweder das Graphem <e> oder das Graphem <è> ausgewählt und somit die Aussage getroffen wurde, dass sich hinter diesen Graphemen lautliche Unterschiede in Hinblick auf die italienische Sprache verbergen. Es gab neun Wörter, die entweder ein oder mehrere der Grapheme <e> und <è> beinhaltet haben: terra, terremoto, pane, penna, eppure, cooperazione, lento, cioè und tè. 185 der insgesamt 274 Eingaben weisen Markierungen des Graphems <e> und 98 Eingaben Markierungen des Graphems <è> auf. Von diesen Markierungen sind alle Probanden und dementsprechend auch alle drei deutschsprachigen Länder betroffen.
Bei genauerer Betrachtung der markierten Grapheme, die in der untenstehenden Abbildung 10 dargestellt werden, kann festgehalten werden, dass die Sprecher aus Deutschland zwischen minimal elf und maximal 18 Markierungen, die Sprecher aus Österreich zwischen minimal neun und maximal 21 Markierungen und die Sprecher aus der Schweiz zwischen minimal 14 und maximal 27 Markierungen liegen. Im Durchschnitt können die deutschen Sprecher 14,3 Markierungen, die österreichischen Sprecher 14,2 Markierungen und die schweizerischen Sprecher 17,2 Markierungen der Grapheme <e> und <è> verzeichnen.
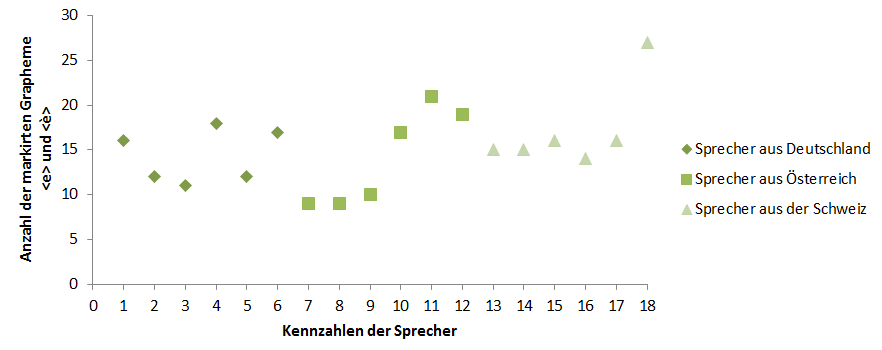
Verteilung der markierten Grapheme <e> und <è> nach Sprechern
Die deutschen und österreichischen Sprecher weisen demnach durchschnittlich fast gleich viele Markierungen der Grapheme <e> und <è> auf, wohingegen die Sprecher aus der Schweiz im Schnitt ungefähr drei Markierungen mehr aufweisen. Interessant ist in Hinblick auf Deutschland und Österreich zu sehen, dass sich die markierten Grapheme, sowohl bei den deutschen als auch den österreichischen Sprechern, anhand ihrer Anzahl in jeweils zwei Gruppen teilen lassen. Zum einen gibt es die Gruppe der deutschen Sprecher, die elf, zwölf und zwölf Markierungen aufweist und zum anderen die Gruppe der deutschen Sprecher, bei der 16, 17 und 18 Markierungen verzeichnet wurden. Noch deutlicher tritt das gleiche Phänomen bei den österreichischen Sprechern auf, die einerseits nur neun, neun und zehn Markierungen aufweisen und damit die geringsten Markierungen aller aufgenommenen Sprecher erhalten haben, und andererseits 17, 21 und 19 Markierungen, die zu den höchsten Anzahlen von Markierungen aller Sprecher zählen. Die schweizerischen Sprecher zeigen demgegenüber ein homogeneres Bild auf, da fünf von sechs Sprechern Werte zwischen 14 und 16 Markierungen aufzeigen und nur ein Sprecher 27 Markierungen, und damit den höchsten Markierungswert aller Teilnehmer, verzeichnet. Die Sprecher 0004, 0011, 0012 sowie 0018 weisen die meisten Markierungen der Grapheme <e> und <è> auf und sollen aus diesem Grund näher betrachtet werden.
Bezieht man die Fragebögen, auf denen die Probanden ihre persönlichen Daten angeben mussten, in die Analyse ein, kann festgestellt werden, dass Sprecher 0004, der aus Deutschland stammt, den Dialekt Bayerisch spricht, fünf weitere Fremdsprachen neben Italienisch erlernt hat, regelmäßig Kontakt zu italienischen Muttersprachlern im Wohnort hat und seit etwa zweieinhalb Jahren Italienisch lernt. Die Probanden 0011 und 0012, die beide aus Österreich stammen, sprechen hingegen keinen österreichischen Dialekt und haben außer Englisch noch zwei weitere Fremdsprachen erlernt. Proband 0011 lernt seit circa vier Jahren Italienisch, hat regelmäßigen Kontakt zu italienischen Muttersprachlern in seinem Wohnort und hat einen Auslandsaufenthalt von drei Wochen absolviert. Proband 0012 lernt hingegen schon seit sieben Jahren Italienisch, hat keinen regelmäßigen Kontakt zu italienischen Muttersprachlern und kann außerdem keinen Auslandsaufenthalt in einem italienischsprachigen Land vorweisen. Proband 0018, der in der Schweiz lebt, hat neben seiner Muttersprache Deutsch auch noch Portugiesisch als Muttersprache angegeben, spricht Schweizerdeutsch, hat vier weitere Fremdsprachen erlernt, hat regelmäßigen Kontakt mit Italienern in seinem Wohnort und lernt seit eineinhalb Jahren Italienisch. Sowohl Proband 0004 als auch die Probanden 0011 und 0012 studieren Italienisch und nur Proband 0018, der die meisten Markierungen der Grapheme <e> und <è> erhalten hat, hat angegeben, Kunstgeschichte und Philosophie zu studieren.
Anhand der personenspezifischen Daten können also nur wenige Parallelen gefunden werden, da die Dauer des Fremdsprachenerwerbs stark variiert und auch die Anzahl der weiteren erlernten Fremdsprachen große Unterschiede aufweist. Interessant ist aber zu sehen, dass Proband 0018, der die meisten Markierungen erhalten hat, am kürzesten Italienisch lernt und als einziger der vier Probanden kein sprachwissenschaftliches Studium absolviert. Doch wie viele Markierungen haben die Probanden bei welchen Wörtern erhalten? Die Antwort auf diese Frage veranschaulicht das Diagramm Abbildung 11 Anzahl der Markierungen von <e> und <è> nach Wörtern und Sprechern.
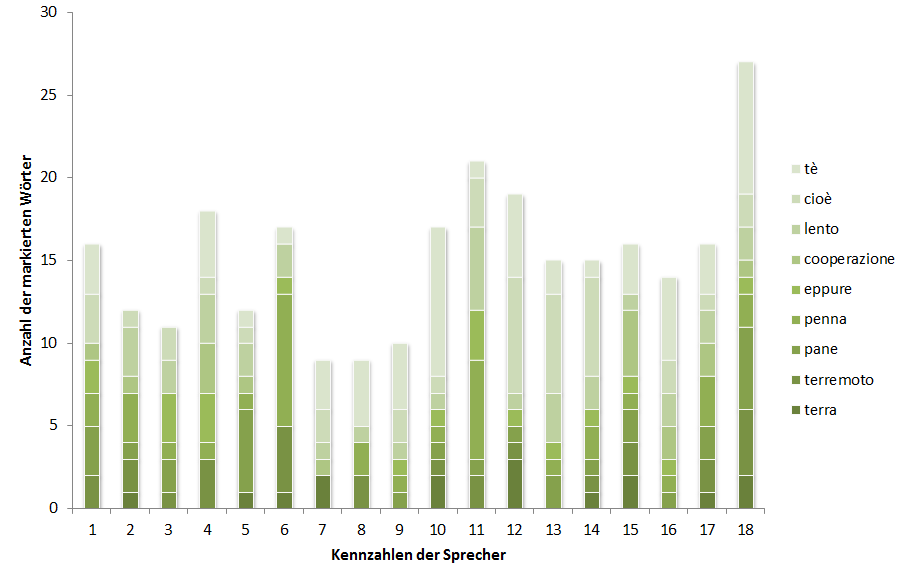
Anzahl der Markierungen von <e> und <è> nach Wörtern und Sprechern
Das Diagramm veranschaulicht nicht nur die Gesamtanzahl der markierten Wörter, sondern zeigt auch die Verteilung ebendieser nach Sprecher auf. Es ist deutlich zu erkennen, dass Proband 0018 die meisten Markierungen erhalten hat und vor allem bei jedem Wort mindestens ein Graphem markiert wurde. Andere Sprecher, wie beispielsweise Proband 0007 oder Proband 0008, weisen hingegen eine sehr geringe Anzahl an markierten Wörtern auf, wobei sich die Markierungen lediglich auf fünf bzw. vier Wörter verteilen. Betrachtet man im Gegensatz dazu die markierten Wörter, kann die Aussage getroffen werden, dass die Wörter tè und cioè, die das Graphem <è> repräsentieren, mit insgesamt 57 und 40 verzeichneten Markierungen, die am häufigsten markierten Wörter darstellen. Die Wörter penna sowie lento wurden über 30 Mal, genauer 36 Mal und 34 Mal, markiert, während die Wörter terra, terremoto, pane, eppure sowie cooperazione unter 30 Markierungen liegen. Die am seltensten markierten Wörter sind terra und cooperazione, die beide lediglich 16 Mal markiert wurden. Wendet man sich den einzelnen Sprachaufnahmen zu, kann festgestellt werden, dass die Probanden 0004, 0011, 0012 sowie 0018 zwar insgesamt die meisten Markierungen der Grapheme <e> und <è> erhalten haben, aber wörterbezogen nicht immer die höchste Anzahl an Markierungen aufweisen. Überdurchschnittlich oft wurde das <è> beispielsweise im Wort tè bei den Sprechern mit den Kennzahlen 0010 und 0018 markiert, das Graphem <e> im Wort penna bei den Sprechern mit den Kennzahlen 0006 und 0011, das Graphem <e> in pane bei den Sprechern 0005 sowie 0018 und das <è> in cioè bei Sprecher 0012. Aus diesem Grund sollen nun im Folgenden die Aufnahmen 0005_pane, 0006_penna, 0010_tè, 0011_penna, 0012_cioè, 0018_pane und 0018_tè analysiert und miteinander verglichen werden.
0005_pane
Folgende Markierungen konnten bei der Sprachaufnahme 0005_pane verzeichnet werden:
…e
.a.e
.a.e
..ne
.a.e
Die in der Markierungsliste aufgeführten Punkte stellen die nicht markierten Grapheme dar, während die ausgewählten Grapheme als ebensolche zu sehen sind. In fünf Fällen wurde bei der Sprachaufnahme 0005_pane, die insgesamt elfmal bearbeitet wurde und die von einem Sprecher aus Deutschland stammt, das <e> in pane markiert und die Aussage getroffen, dass bei diesem Laut lautliche Unterschiede in Hinblick auf die italienische Sprache festgestellt werden können. Ohne die Aufnahme bereits angehört zu haben, könnte die Vermutung aufgestellt werden, dass das finale <e> des Wortes pane [’paːne] von dem ausgewählten deutschen Sprecher entweder als /ɛ/ oder /ə/ realisiert wurde, wodurch die italienische Standardaussprache nicht mehr gegeben wäre.
Betrachtet man die Sprachaufnahme in Praat und hört sich ebendiese an, ergibt sich folgendes Bild und folgende Transkription:
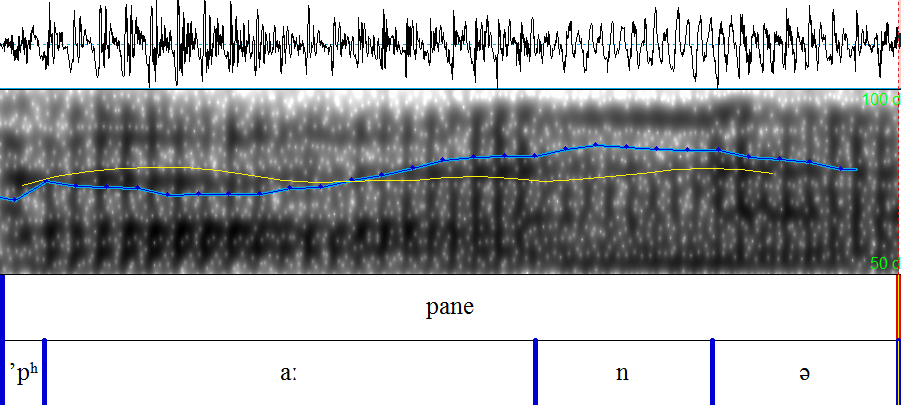
Oszillogramm, Sonogramm und Transkription der Sprachaufnahme 0005_pane
Nach Analyse der Sprachaufnahme 0005_pane kann festgestellt werden, dass Proband 0005 den markierten Laut als /ə/ wiedergegeben hat und aus diesem Grund die Markierungen des Graphems <e> zustande gekommen sind. Die Produktion eines Schwa-Lautes ist typisch für die deutsche Sprache und findet in der Regel bei einer unbetonten Vor- oder Endsilbe statt. Dieser Laut existiert in der italienischen Sprache nicht, weswegen eine deutliche lautliche Interferenz zu beobachten ist. Da aufgrund der Position des Graphems <e> die Wahrscheinlichkeit relativ hoch ist, dass deutsche Sprecher in diesem Fall den Laut /ə/ produzieren, könnte vermutet werden, dass noch weitere Sprecher ebendiese produziert haben. Widmet man sich den weiteren Sprachaufnahmen von pane, wird ersichtlich, dass außer Proband 0005 auch Proband 0018 fünf Markierungen erhalten hat, die anderen Sprecher aber zwischen null und drei Markierungen liegen und auch nur Proband 0001 drei Markierungen erhalten hat.
0018_pane
Hört man sich die Audioaufnahme 0018_pane an, erklärt sich die Anzahl der Markierungen, die auf der Grundlage von zwölf Bearbeitungen der Aufnahme beruht, dadurch, dass der schweizerische Sprecher die Aussprache /’paːnɛ/ gewählt hat und demzufolge den geschlossenen Laut /e/ durch den offenen Laut /ɛ/ ersetzt hat. Die Tendenz, dass die Mehrzahl der deutschen Sprecher das finale /e/ als /ə/ oder /ɛ/ wiedergegeben haben, wird bei Betrachtung der Transkriptionen ersichtlich, da zehn von 18 Sprechern das finale /e/ bei dem Wort pane anders als von der italienischen Standardaussprache vorgesehen realisiert haben18.
Die nächste Sprachaufnahme, die genauer analysiert werden soll, ist die Aufnahme 0006_penna, die wiederum von einem Sprecher aus Deutschland stammt, zwölfmal bearbeitet wurde und folgende Markierungen im Perzeptionstest erhalten hat:
pe..
.enn.
pe.a
pe..
.e..
.e..
pe..
.e..
0006_penna
Insgesamt kann die Sprachaufnahme 0006_penna acht Markierungen des Graphems <e> verzeichnen, die sich damit weit über dem Durchschnitt, der bei zwei Markierungen liegt, befindet. Bei der Hälfte der Markierungen wurde neben dem Graphem <e> außerdem das Graphem <p> markiert und somit die Aussage getroffen, dass lautliche Unterschiede nicht nur beim <e> sondern auch bei der Kombination von <p> und <e> zu erkennen sind. Da das Italienische die Aussprache /’penna/ vorsieht, besteht in diesem Fall die Möglichkeit, dass der Proband 0006 das /e/ als /ɛ/ realisiert hat und aus diesem Grund Markierungen gesetzt wurden. Öffnet man die Sprachaufnahme in Praat und bearbeitet sie, erscheint folgende Ansicht und Transkription:
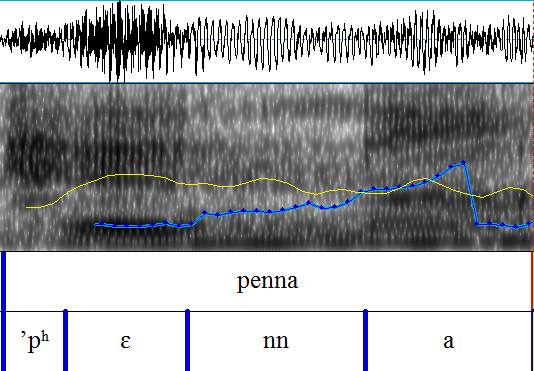
Oszillogramm, Sonogramm und Transkription der Sprachaufnahme 0006_penna
Proband 0006 hat demnach nicht den geschlossenen Laut /e/ sondern den offenen Laut /ɛ/ bei der Aussprache von penna verwendet und aus diesem Grund acht Markierungen erhalten. Des Weiteren kann festgestellt werden, dass der Proband eine sehr starke Aspiration bei dem Laut /p/ aufweist und deswegen das Graphem <p> ebenfalls häufig markiert wurde. Die anderen Sprecher konnten bei dem Wort penna zwischen null und sechs Markierungen verzeichnen, wobei aber betont werden muss, dass nur Proband 0011 sechs Markierungen erhalten hat und somit, wie Proband 0006, über dem Durchschnitt liegt.
Wertet man die Eingaben der Testteilnehmer aus, so können für die ebenfalls zwölfmal bearbeitete Audioaufnahme 0011_penna folgende Markierungen festgestellt werden:
.e..
.enn.
.enn.
.e..
.e..;
.e.a
0011_penna
Sechsmal wurde bei der Sprachaufnahme 0011_penna das <e> ausgewählt, doch tritt diese Markierung kein einziges Mal in Kombination mit einem ausgewählten <p> auf, wie es bei Proband 0006 der Fall war. Dies liegt in der Tatsache begründet, dass Proband 0011 nur eine sehr geringe Aspiration bei dem Laut <p> aufzeigt und diese wahrscheinlich so gering ist, dass die italienischen Testteilnehmer keinen Unterschied in der Aussprache feststellen konnten. Nichtsdestotrotz können auch Gemeinsamkeiten zwischen der Aufnahme des deutschen Probanden 0006 und des österreichischen Probanden 0011 festgestellt werden, da sich beide Probanden für die Aussprache /’pɛnna/ entschieden haben und somit auch Proband 0011 von der italienischen Standardaussprache abweicht. Bezieht man alle Transkriptionen der Sprachaufnahmen zu dem Wort penna in die Analyse ein, kann die Aussage getroffen werden, dass die Mehrheit der deutschsprachigen Sprecher Differenzen in Bezug auf die italienische Standardaussprache aufzeigt, da lediglich vier Probanden, davon einer aus Deutschland, einer aus Österreich und zwei aus der Schweiz, den geforderten Laut /e/ realisiert haben.
Eine weitere interessante Sprachaufnahme, die nun im Folgenden genauer untersucht werden soll, ist die Aufnahme 0010_tè, die neun Markierungen bei 13 Bearbeitungen erhalten hat und damit das Maximum an Markierungen in Hinblick auf die Grapheme <e> und <è> und in Bezug auf die aufgenommenen Sprecher aufweist. Die neun Markierungen des Graphems <è> sehen wie folgt aus:
.è
.è
.è
tè
.è
tè
.è
.è
.è
0010_tè
Neunmal wurde bei der Aufnahme 0010_tè demnach das Graphem <è> und in zwei von neun Fällen zusätzlich das Graphem <t> markiert. Da diese Aufnahme die Aufnahme mit den meisten Markierungen in Hinblick auf die Grapheme <e> und <è> darstellt, kann die Aussage getroffen werden, dass der wahrgenommene lautliche Unterschied besonders deutlich für die italienischen Testteilnehmer war. Doch welcher lautliche Unterschied wurde von den italienischen Testteilnehmern festgestellt?
Beim Anhören der Sprachaufnahmen ist deutlich zu hören, dass der Proband 0010 das Wort tè [’tɛ] mit der Aussprache /’te/ realisiert und folglich das Phonem /ɛ/ nicht realisiert, obwohl es bereits durch das Graphem <è> vorgegeben wird. Da Proband 0010 aus Österreich kommt und in Kapitel 2.3.1. Vokalrealisation deutscher Sprecher erklärt wurde, dass sich das österreichische Vokalsystem durch das Fehlen des Phonems /ɛ/ charakterisiert, ist es nicht verwunderlich, dass es in Hinblick auf die Differenzierung der Phoneme /e/ und /ɛ/ zu Interferenzerscheinungen in der italienischen Sprache kommt. Der Durchschnittswert des markierten Graphems <è> bei dem Wort tè liegt bei den deutschen Sprechern bei 1,5, bei den österreichischen Sprechern bei 4,3 und bei den Sprechern aus der Schweiz bei 3,7. Die österreichischen Sprecher zeigen also tatsächlich eine erhöhte Markierungsrate im Vergleich zu Deutschland und der Schweiz auf. Doch auch bei den Schweizern können Sprachaufnahmen des Wortes tè mit einer hohen Anzahl an Markierungen vorgefunden werden, wie beispielsweise die Aufnahme 0018_tè, die insgesamt zwölfmal bearbeitet wurde und folgende Markierungen von den italienischen Testteilnehmern erhalten hat:
.è
.è
.è
.è
.è
.è
.è
.è
0018_tè
Wie in der Auflistung der Markierungen der Aufnahme 0018_tè zu sehen ist, wurde achtmal das Graphem <è> markiert. Interessant ist hinsichtlich der Markierungen auch die Tatsache, dass nur das Graphem <è> ausgewählt wurde und keine Markierungen des Graphems <t> in Kombination mit dem Graphem <è> vorgekommen sind. Anders als bei Proband 0010, der Probleme bei der Differenzierung der Phonemen /e/ und /ɛ/ hatte, spricht Proband 0018 das Wort tè wie /’tiː/ aus und erinnert damit an die englische Aussprache des Wortes tea, das ebenfalls ‚Tee‘ bedeutet. Diese Aussprache findet sich aber nur bei Proband 0018 wieder, was zum einen an seiner noch recht kurzen Erwerbsphase der Fremdsprache Italienisch liegen könnte und zum anderen der Tatsache geschuldet sein könnte, dass Proband 0018 nicht nur die deutsche Sprache sondern auch die portugiesische Sprache als Muttersprache19 hat. Wirft man nämlich einen Blick auf die Aussprache des Portugiesischen, kann konstatiert werden, dass die Ausspracheregeln der Vokale vielzählig sind und das Graphem <e> in bestimmten Fällen als /i/ realisiert werden kann (vgl. Reumuth/Winkelmann 2013, 9-10). In diesem Fall liegt also keine lautliche Interferenz zwischen der deutschen und der italienischen Sprache vor, sondern vielmehr interferieren lautliche Merkmale der portugiesischen Sprache mit der italienischen Sprache.
Bei den Sprachaufnahmen des Wortes tè haben insgesamt acht der Teilnehmer, davon zwei aus Deutschland, zwei aus Österreich und vier aus der Schweiz, anstatt des Phonems /ɛ/ das Phonem /e/ realisiert. Folglich haben 44,4% der Probanden Probleme bei der Unterscheidung zwischen dem offenen und geschlossenen e-Laut bei der lautlichen Produktion des Wortes tè gezeigt. Bei 17 von 18 Probanden konnte außerdem eine Aspiration bei der Aussprache von /t/ festgestellt werden. Inwieweit diese Aspiration von den Italienern wahrgenommen wurde, wird in Kapitel 4.4.4. Analyse von /t/ näher besprochen werden.
Die letzte Aufnahme, die in diesem Teilkapitel behandelt werden soll, ist die Aufnahme 0012_cioè, die zehnmal bearbeitet wurde, siebenmal in Hinblick auf das Graphem <è> ausgewählt wurde und folgende Markierungen erhalten hat:
…è
..oè
…è
.ioè
…è
..oè
…è
0012_cioè
Bei der Aufnahme 0012_cioè eines Sprechers aus Österreich wurde außerdem dreimal das Graphem <o> zusätzlich zum Graphem <è> ausgewählt. Wie auch bei dem italienischen Wort tè gibt die Schreibweise des Wortes cioè [ʧo’ɛ] bereits seine Aussprache an. Nach Anhören der Sprachaufnahme und Betrachtung ebendieser in Praat kann allerdings festgestellt werden, dass Proband 0012 die Aussprache /ʧo’e/ angewandt hat und vermutlich Schwierigkeiten hatte, den Laut /ɛ/ korrekt zu realisieren.
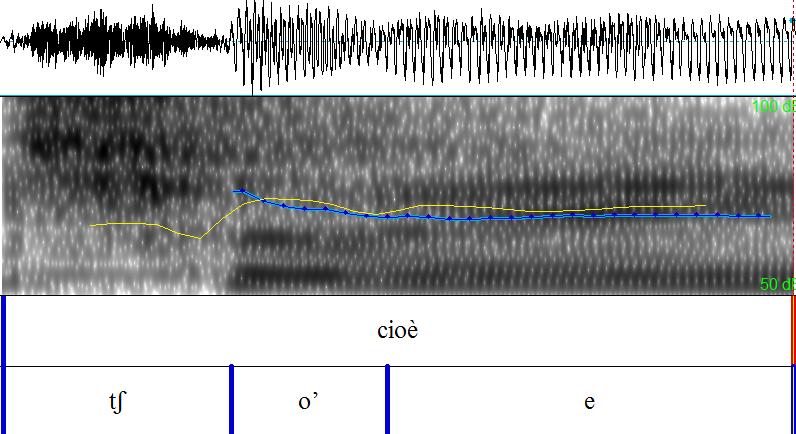
Oszillogramm, Sonogramm und Transkription der Sprachaufnahme 0012_cioè
Da Sprecher 0012 wie Sprecher 0010 ebenfalls aus Österreich stammt und das gleiche Phänomen bei beiden Sprechern beobachtet werden konnte, kann die Schlussfolgerung gezogen werden, dass die Schwierigkeiten bei der Differenzierung von /e/ und /ɛ/ bei den österreichischen Sprechern im Italienischen sehr präsent sind. Betrachtet man allerdings die Durchschnittswerte der Markierungen von <è> im Wort cioè nach Ländern, ist zu sehen, dass Deutschland einen Durchschnittswert von 1,3, Österreich einen Durchschnittswert von 2,5 und die Schweiz einen Durchschnittswert von 2,8 Markierungen aufweist. Demzufolge konnten bei den schweizerischen Sprechern noch mehr Markierungen des Graphems <è> vorgefunden werden und es kann die Aussage getroffen werden, dass schweizerische Italienischlerner ebenfalls häufig Probleme mit der Produktion des Lautes /ɛ/ haben. Wirft man einen Blick auf die Transkriptionstabelle, wird ersichtlich, dass sechs Sprecher, davon einer aus Österreich und fünf aus der Schweiz, bei dem Wort cioè anstatt des Lautes /ɛ/ den Laut /e/ produziert haben. Auffällig ist, dass bei vier von sechs Schweizern lautliche Unterschiede in Hinblick auf den e-Laut beim Wort cioè festgestellt werden können und keiner der sechs deutschen Sprecher lautliche Unterschiede in Hinblick auf ebendiesen aufweist.
Nachdem die Laute /e/ und /ɛ/ analysiert und die Interferenzen bei ebendiesen mit den Herkunftsländern der Probanden in Verbindung gebracht wurden, soll nun eine ganz ähnliche Analyse für die Laute, die sich hinter dem Graphem <o> verbergen, folgen.
4.4.2. Analyse von /o/ und /ɔ/
Das Graphem <o> konnte für jedes Land noch mehr Markierungen als die Grapheme <e> und <è> verzeichnen und soll aus diesem Grund nun ebenfalls detailliert analysiert werden. Im Perzeptionstest waren sechs Wörter vorhanden, bei denen ein- oder mehrmals das Graphem <o> ausgewählt werden konnte: terremoto, risposta, cooperazione, ruolo, lento und cioè. Werden alle Sprecher zusammengefasst, so können 282 Eingaben, bei denen ein- oder mehrmals das Graphem <o> innerhalb eines Wortes ausgewählt wurde, vorgefunden werden. Von diesen Eingaben können 88 Eingaben den Sprechern 0001 bis 0006, 75 Eingaben den Sprechern 0007 bis 0012 und 119 Eingaben den Sprechern 0013 bis 0018 zugeordnet werden.
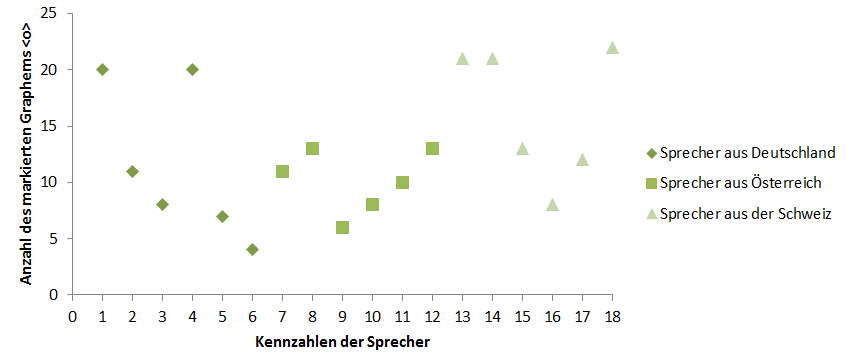
Verteilung des markierten Graphems <o> nach Sprechern
Abbildung 15 veranschaulicht die Verteilung der Markierungen des Graphems <o> und zeigt, dass die Markierungen der deutschen Sprecher zwischen den Werten vier und 20, die Markierungen der österreichischen Sprecher zwischen den Werten sechs und 13 und die Markierungen der schweizerischen Sprecher zwischen den Werten acht und 22 liegen. Die österreichischen Sprecher haben damit den niedrigsten Durchschnittswert von 10,2, während die deutschen Sprecher einen Durchschnittswert von 11,7 und die schweizerischen Sprecher einen Durchschnittswert von 16,2 aufweisen. Demnach können bei den Schweizern die meisten Markierungen des Graphems <o> vorgefunden werden. Die niedrigste Anzahl der Markierungen kann bei Sprecher 0006 erkannt werden und die höchste Anzahl der Markierungen kann im Vergleich dazu bei Sprecher 0018 vorgefunden werden.
Interessant ist bei der Verteilung des Graphems <o> zu beobachten, dass alle Sprecher der verschiedenen deutschsprachigen Länder recht unterschiedliche Werte aufweisen und deswegen eine stärkere Heterogenität im Vergleich zur Verteilung der Grapheme <e> und <è> besteht. Von den fünf Sprechern mit den meisten Markierungen stammen die zwei Sprecher mit den Kennzahlen 0001 und 0004 aus Deutschland und die drei Sprecher mit den Kennzahlen 0013, 0014 und 0018 aus der Schweiz. Bei jedem der fünf Sprecher können mindestens 20 Markierungen des Graphems <o> vorgefunden werden. Wirft man einen Blick auf die ausgefüllten Fragebögen der Sprecher mit den meisten Markierungen des Graphems <o> kann festgestellt werden, dass die deutschen Sprecher mit den Kennzahlen 0001 und 0004 beide einen Dialekt, Allgäuerisch bzw. Bayerisch, sprechen und außerdem vier bis fünf andere Sprachen erlernt haben. Da diese beiden Sprecher im Vergleich zu den anderen deutschen Sprechern einen Dialekt sprechen und die meisten Fremdsprachen erlernt haben, von denen die Mehrheit den romanischen Sprachen zugeordnet werden kann, könnte die Vermutung aufgestellt werden, dass diese weiteren sprachlichen Kenntnisse die Aussprache von /o/ und /ɔ/ beeinflussen. Wendet man sich den Probanden 0013, 0014 und 0018 zu, kann anhand der Fragebögen festgestellt werden, dass alle Probanden Schweizerdeutsch sprechen und Proband 0013 und Proband 0018 weitere fünf bzw. vier Sprachen erlernt haben. Proband 0018 hat zudem als zweite Muttersprache Portugiesisch angegeben und alle drei schweizerischen Sprecher haben überdies angegeben, kein sprachwissenschaftliches Studienfach zu studieren, wohingegen beide deutschen Sprecher angeführt haben, dass sie ihren Master im Studienfach Romanistik absolvieren. Betrachtet man die Dauer des Fremdsprachenerwerbs der fünf ausgewählten Teilnehmer, ist zu sehen, dass Proband 0001 mit einer Fremdsprachenerwerbsdauer von zehn Jahren der Sprecher mit dem längsten Erwerb ist, gefolgt von Proband 0014, der bereits fünf Jahre Italienisch lernt und damit, zeitlich gesehen, nur die Hälfte der Zeit von Proband 0001 in den Fremdsprachenerwerb des Italienischen investiert hat. Die anderen drei Probanden mit den Kennzahlen 0004, 0013 und 0018 lernen erst vergleichsweise kurz Italienisch und haben angegeben, dass sie sich seit zweieinhalb Jahren, zwei Jahren bzw. eineinhalb Jahren mit der Sprache beschäftigen und ebendiese erlernen. Die Dauer des Fremdsprachenerwerbs scheint in diesem Fall also keine allgemeine Begründung für die hohe Anzahl der Markierungen des Graphems <o> bei diesen fünf Sprechern darzustellen. Interessanterweise haben beide deutschen und ein schweizerischer Sprecher angegeben, regelmäßig Kontakt mit italienischen Muttersprachlern zu haben, doch hat nur Proband 0001 angegeben, einen Auslandsaufenthalt absolviert zu haben. Da dieser allerdings nur eine Dauer von zwei Wochen hatte, kann festgehalten werden, dass jeder der fünf Sprecher keine längere Zeit im italienischsprachigen Ausland verbracht hat.
Wie oft Markierungen des Graphems <o> allgemein und insbesondere bei den Sprechern 0001, 0004, 0013, 0014 und 0018 vorkamen, zeigt Abbildung 16. In diesem Säulendiagramm können die Gesamtanzahl der Eingaben, bei denen das Graphem <o> ausgewählt wurde sowie die Anzahl der markierten Wörter im Einzelnen betrachtet werden.
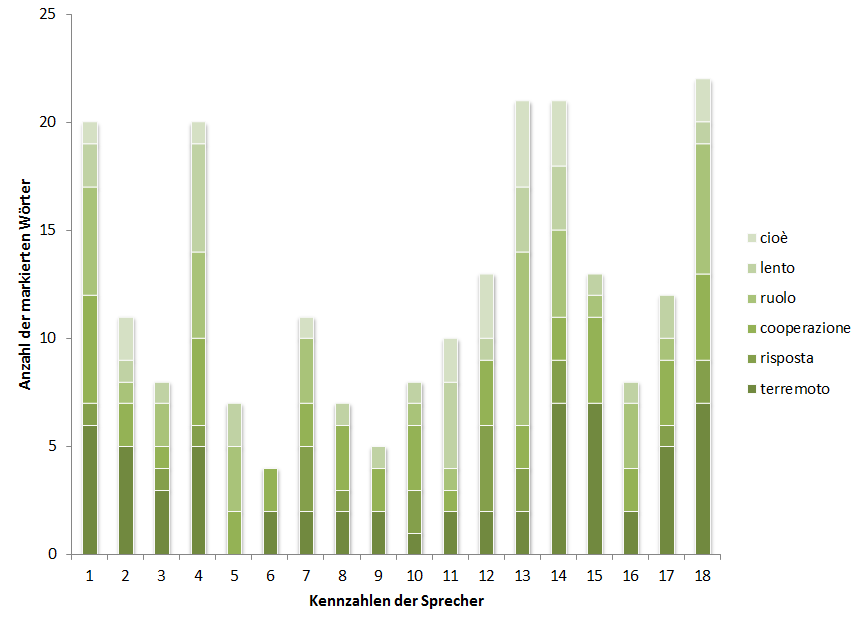
Anzahl der Markierungen von <o> nach Wörtern und Sprechern
Abbildung 16 zeigt unter anderem auf, dass bei Sprecher 0006 das Graphem <o> nur bei zwei Wörtern markiert wurde und auch bei Sprecher 0005 lediglich Markierungen bei den Wörtern cooperazione, ruolo sowie lento verzeichnet wurden. Da aufgrund der hohen Anzahl an Aufnahmen nicht alle Sprachaufnahmen jedes Sprechers qualitativ analysiert werden können, soll das Diagramm in Abbildung 16 Aufschluss darauf geben, welche Wörter welches Sprechers am häufigsten von Markierungen betroffen waren und welche Sprachaufnahmen dementsprechend genauer untersucht und analysiert werden sollten. Generell kann die Aussage getroffen werden, dass die Wörter terremoto, cooperazione und ruolo besonders häufig von Markierungen betroffen sind und auch die meisten Sprecher bei ebendiesen Wörtern Markierungen erhalten haben. Insgesamt gibt es 62 Markierungen, die das Wort terremoto, 47 Markierungen, die das Wort cooperazione, und 43 Markierungen, die das Wort ruolo betreffen. Um die Phoneme /o/ und /ɔ/ sowie die einzelnen Wörter, in denen sie vorkommen, in dieser Analyse zu repräsentieren, wurden deswegen die Aufnahmen 0001_terremoto, 0001_cooperazione sowie 0013_ruolo ausgewählt.
0001_terremoto
Die Sprachaufnahme 0001_terremoto, die von den italienischen Testteilnehmern insgesamt elfmal bearbeitet wurde, konnte folgende Markierungen verzeichnen:
..rr..o..
..rr..o..
..rre.o..
t.rre.oto
..rr…to
..rr..o.o
…..o..
In sechs von sieben Eingaben wurde das vorletzte <o> markiert und in drei der sieben Eingaben das finale <o>. Es kann also davon ausgegangen werden, dass die Aussprache des Sprechers 0001 nicht der italienischen Standardaussprache von terremoto [terre’mɔːto] entspricht. Beim Anhören der Sprachaufnahme kann allerdings auch festgestellt werden, dass sich der finale Laut /o/ ein wenig abgeschnitten anhört und aus diesem Grund wahrscheinlich einige Markierungen bei ebendiesem Laut gesetzt wurden. Solche leicht abgeschnittenen Endlaute sind oftmals der Methode an sich geschuldet, da die Probanden ganze Sätze eingesprochen haben und die Wörter im Nachhinein aus der Gesamtaufnahme extrahiert wurden. Wurde ein Satz besonders schnell ausgesprochen oder Wörter zusammengezogen, konnten deswegen keine klareren Audiodateien der einzelnen Wörter geschnitten werden. Betrachtet man die Aufnahme in Praat, kann die Sprachaufnahme mit ihrer Transkription aber wie folgt dargestellt werden:
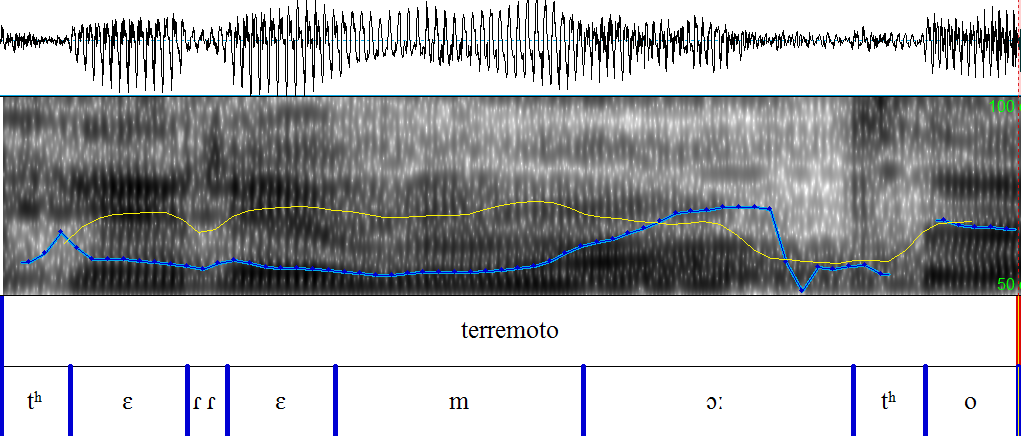
Oszillogramm, Sonogramm und Transkription der Sprachaufnahme 0001_terremoto
In Abbildung 17 ist zu sehen, dass Proband 0001 den ersten o-Laut des Wortes, der nach der italienischen Standardaussprache offen ausgesprochen werden sollte, als /ɔː/ realisiert und somit eigentlich der italienischen Aussprache folgt. Dennoch haben sieben von elf italienischen Testteilnehmern eine lautliche Differenz bei diesem Laut perzipiert, was vermuten lässt, dass der Öffnungsgrad des produzierten Lautes nicht dem normalen Öffnungsgrad des Standarditalienischen entspricht. Bei der Auswertung der Eingaben wird ersichtlich, dass die Aufnahme zwischen ein und 18 Mal angehört wurde, sich die meisten Teilnehmer aber nach dem zweiten Abspielen der Aufnahme für ihre Markierungen entschieden haben. Bezieht man die soziodemographischen Daten der Testteilnehmer, die bei dieser Sprachaufnahme das erste <o> ausgewählt haben, in die Analyse mit ein, ist zu sehen, dass zwei Italiener aus der Toskana kommen und einer von ihnen in München wohnt, zwei weitere Italiener aus Sizilien stammen, von denen einer bereits in der Schweiz und in Spanien gelebt hat, und die restlichen drei Italiener aus dem Veneto kommen und sie alle bereits in Deutschland gelebt haben. Viele der Testteilnehmer, die das erste <o> bei der Sprachaufnahme 0001_terremoto markiert haben, haben also bereits in einem deutschsprachigen Land gelebt und dadurch vielleicht einen Unterschied herausgehört.
Im Allgemeinen wurde das Wort terremoto mit Blick auf den o-Laut am häufigsten markiert und weist bei den deutschen Sprechern eine durchschnittliche Markierungsrate von 3,5 bei den österreichischen Sprechern eine durchschnittliche Markierungsrate von 1,8 und bei den schweizerischen Sprechern eine durchschnittliche Markierungsrate von 5,0 auf. Die italienischen Testteilnehmer konnten bei den österreichischen Sprechern also mit Abstand am wenigsten lautliche Differenzen in Hinblick auf die Vokalphoneme /o/ und /ɔ/ wahrnehmen, während bei den schweizerischen Sprechern die meisten lautlichen Differenzen perzipiert werden konnten.
Die zweite Aufnahme, die nun analysiert werden soll, ist die Aufnahme 0001_cooperazione, die von den Testteilnehmern elfmal bearbeitet wurde und bei der folgende fünf Markierungen gesetzt wurden:
…..r..io.e
.o…r.z….
……a.io..
…….zio..
………o..
0001_cooperazione
Insgesamt gibt es fünf Einträge für die Sprachaufnahme 0001_cooperazione und diese zeigen vier Markierungen des letzten <o>s und eine Markierung des ersten <o>s auf. Es kann demnach die Vermutung aufgestellt werden, dass die Standardaussprache von cooperazione [kooperat’tsioːne] im Falle von Proband 0001 in Hinblick auf das letzte <o> abweicht. Das Wort cooperazione hat mit insgesamt 47 Markierungen die zweitmeisten Markierungen erhalten und hat bei den Sprechern aus Deutschland zu einem Durchschnitt von 2,7, bei den Sprechern aus Österreich zu einem Durchschnitt von 2,3 und bei den Sprechern aus der Schweiz zu einem Durchschnitt von 2,8 ausgewählten <o>-Graphemen geführt. Sieht man sich die Aufnahme 0001_cooperazione in Praat an, kann Folgendes in Bezug auf lautliche Differenzen festgestellt werden:
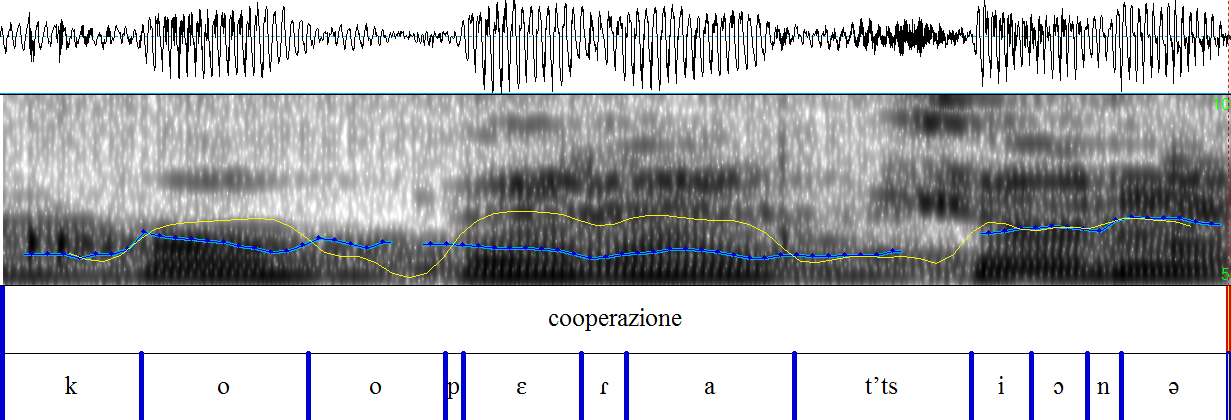
Oszillogramm, Sonogramm und Transkription der Sprachaufnahme 0001_cooperazione
Durch die Darstellung der Sprachaufnahme 0001_cooperazione in Praat ist deutlich zu erkennen, dass der finale o-Laut, der die meisten Markierungen erhalten hat, von Probandin 0001 einerseits offen und andererseits sehr kurz ausgesprochen wird, wodurch die geschlossene und lange geforderte Realisation von /oː/ der italienischen Standardaussprache nicht gegeben ist. Höchstwahrscheinlich haben die italienischen Testteilnehmer diese lautliche Differenz perzipiert und aus diesem Grund das finale Graphem <o> gekennzeichnet.
Bei der Sprachaufnahme 0013_ruolo, die von den italienischen Testteilnehmern insgesamt zwölfmal bearbeitet wurde und die die letzte zu analysierende Sprachaufnahme in Bezug auf das anklickbare Graphem <o> darstellt, wurden folgende Markierungen gesetzt:
ruo..
ruo.o
r.o..
….o
r…o
ruo..
..o..
0013_ruolo
Besonders interessant ist bei den Markierungen dieser Sprachaufnahme zu sehen, dass viermal das erste <o> und dreimal das finale <o> ausgewählt wurde und das erste <o> dreimal in Verbindung mit dem Graphem <u> auftritt. Die Kombination der Auswahl von <u> und <o> könnte bedeuten, dass in diesem Fall vor allem Unterschiede in Hinblick auf den Diphthong und nicht zwangsweise spezifisch bei dem ersten o-Laut von den italienischen Testteilnehmern perzipiert wurden. Das Oszillogramm sowie das Sonogramm der Aufnahme und ihre Transkription stellen sich in Praat wie folgt dar:
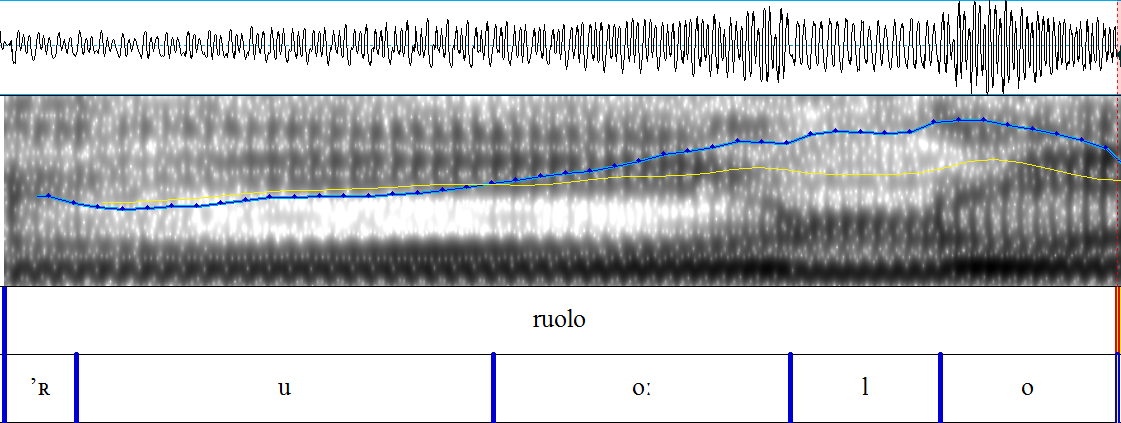
Oszillogramm, Sonogramm und Transkription der Sprachaufnahme 0013_ruolo
Bei Betrachtung der Darstellung der Sprachaufnahme 0013_ruolo in Praat wird sichtbar, dass der initiale o-Laut bei dem Wort ruolo [’ruɔːlo] geschlossen realisiert wurde und demzufolge von der Standardaussprache, die /ɔː/ voraussetzt, abweicht. Unter Einbezug aller Sprachaufnahmen, die das Wort ruolo betreffen, kann registriert werden, dass die Sprecher aus Deutschland einen durchschnittlichen Markierungswert von 2,5, die Sprecher aus Österreich einen durchschnittlichen Markierungswert von 0,8 und die Sprecher aus der Schweiz einen durchschnittlichen Markierungswert von 3,8 bei dem Graphem <o> erhalten haben. Diese Daten zeigen eine große Differenz zwischen Österreich, Deutschland und der Schweiz auf, da die österreichischen Sprecher im Schnitt unter einer Markierung erhalten haben, die deutschen und schweizerischen Sprecher im Gegensatz dazu aber zweieinhalb bzw. fast vier Markierungen vorweisen können. Demzufolge kann festgehalten werden, dass in diesem Fall bei den österreichischen Sprechern die wenigsten lautlichen Interferenzen von den italienischen Testteilnehmern perzipiert wurden.
Nach der letzten analysierten Sprachaufnahme in Hinblick auf die Phoneme /o/ und /ɔ/ soll nun die Analyse von /r/ folgen, die sich mit den lautlichen Realisierungen, die sich hinter dem Graphem <r> bzw. dem Graphempaar <rr> verbergen, befasst.
4.4.3. Analyse von /r/
Ein immer wieder auftretendes Problem stellt der Vibrant /r/ für deutschsprachige Italienischlerner dar, da dieser in der deutschen Sprache nur sehr selten vorkommt und in der Regel als /ʀ/ oder /ʁ/ realisiert wird. Aus diesem Grund konnten viele Markierungen bei dem Graphem <r> und dem Graphempaar <rr> vorgefunden werden, die bei den Wörtern terra, terremoto, risposta, eppure, cooperazione, ruolo sowie parchi möglich waren. Insgesamt konnte eine Anzahl von 328 Eingaben verzeichnet werden, bei denen entweder das Graphem <r> oder das Graphempaar <rr> ausgewählt und damit die Aussage getroffen wurde, dass in diesem Fall ein lautlicher Unterschied im Vergleich zum Italienischen existiert. Das Graphem <r> wurde in 189 Fällen und das Graphempaar <rr> in 139 Fällen markiert.
Wie auch bei den vorherigen Analysen der einzelnen Laute wurde ein Diagramm erstellt, in dem die Verteilung der markierten Grapheme <r> und <rr> nach den einzelnen Sprechern dargestellt wird. In dem Diagramm ist zu erkennen, dass die Anzahl der Markierungen, im Vergleich zu Abbildung 10, die die Verteilung der Grapheme <e> und <è> abbildet, sprecherspezifischer und damit heterogener ist. Diese Schlussfolgerung lässt sich durch die hohe Differenz der Markierungsanzahlen, die von Sprecher zu Sprecher und innerhalb der Sprecher eines Landes stark variieren, begründen. In Deutschland weisen die Sprecher eine Anzahl von Markierungen zwischen acht und 29, in Österreich zwischen sechs und 37 und in der Schweiz zwischen sieben und 40 auf.
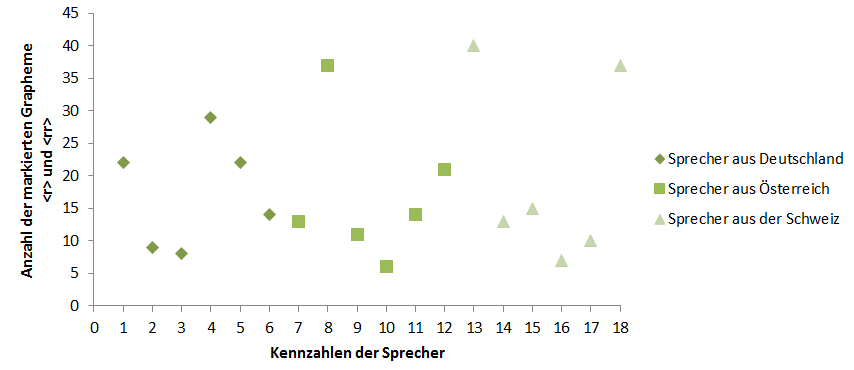
Verteilung der markierten Grapheme <r> und <rr> nach Sprechern
Das Diagramm zeigt also deutlich, dass es sowohl Sprecher eines Landes gibt, die unter zehn Markierungen erhalten haben und bei denen damit in weniger als 3% der Fälle das Graphem <r> oder das Graphempaar <rr> ausgewählt wurde, als auch Sprecher, die über 35 Markierungen erhalten haben und bei denen somit in über 10% aller Fälle das Graphem <r> oder das Graphempaar <rr> markiert wurde. Interessant ist zu beobachten, dass es drei Sprecher, davon zwei aus Österreich stammend und einer aus der Schweiz stammend, gibt, die mehr als dreimal so viele Markierungen wie die Sprecher mit den seltensten Markierungen aufweisen. Wie auch bei dem Graphem <o> kann bei den Markierungen des Graphems <r> und des Graphempaares <rr> festgestellt werden, dass sich die Anzahl der Markierungen sprecherspezifisch und nicht länderspezifisch darstellt. Proband 0004 ist mit 29 Markierungen der am häufigsten markierte deutsche Sprecher, während Proband 0008 mit 37 Markierungen der am häufigsten markierte österreichische Sprecher und Proband 0018 mit ebenfalls 37 Markierungen der am häufigsten markierte schweizerische Sprecher ist. Dennoch ist auffällig, dass die am häufigsten markierten Sprecher aus Österreich und der Schweiz fast zehn Markierungen mehr als der am häufigsten markierte deutsche Sprecher erhalten haben.
Doch wie sieht die genaue Verteilung der Markierungen nach Sprechern und nach Wörtern aus? Die tatsächliche Verteilung des markierten Graphems <r> und des Graphempaares <rr> veranschaulicht die folgende Abbildung 21.
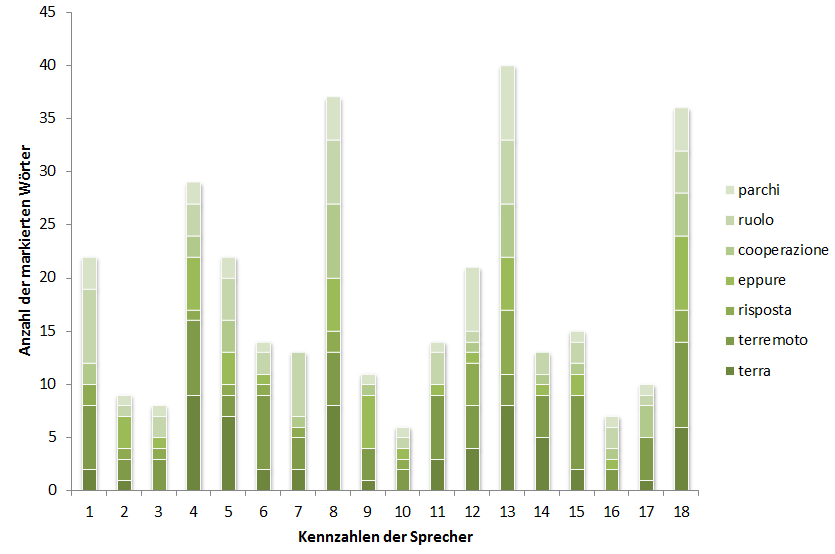
Anzahl der Markierungen von <r> und <rr> nach Wörtern und Sprechern
In Abbildung 21 wird sichtbar, dass die Probanden 0002, 0003, 0010 sowie 0016, die lediglich zwischen sechs und neun Markierungen erhalten haben, diese Markierungen nicht aufgrund einer oder zwei Sprachaufnahmen bekommen haben, sondern Unterschiede immer bei mindestens fünf Wörtern von den italienischen Testteilnehmern perzipiert wurden. Bei den Probanden mit den wenigsten Markierungen des Graphems <r> und des Graphempaares <rr> existieren demnach einige Sprachaufnahmen, die im Laufe des gesamten Perzeptionstests nur einmal von einem Testteilnehmer ausgewählt wurden. Dies lässt den Schluss zu, dass beispielsweise Proband 0010, der im Falle der Wörter risposta, eppure, ruolo sowie parchi jeweils nur eine Markierung erhalten hat, extrem geringe lautliche Differenzen in Hinblick auf den r-Laut aufzeigt und diese nur von jeweils einem aus 38 Probanden erkannt wurden.
Des Weiteren veranschaulicht das Diagramm, dass bei den Wörtern terra und terremoto sprecherübergreifend die meisten Markierungen gesetzt wurden und die Wörter cooperazione sowie risposta die wenigsten Markierungen vom Graphem <r> und dem Graphempaar <rr> generiert haben. Insgesamt können bei dem Wort terra 61 Einträge und bei dem Wort terremoto 78 Einträge mit Markierungen gezählt werden, während das Wort risposta lediglich 24 Einträge und das Wort cooperazione 32 Einträge aufweist. Besonders interessant in Bezug auf Interferenzen scheinen die Sprachaufnahmen 0004_terra, 0018_terremoto, 0013_risposta, 0018_eppure, 0008_cooperazione, 0001_ruolo sowie 0013_parchi zu sein, da sie überdurchschnittlich viele Markierungen des Graphems <r> und des Graphempaares <rr> erhalten haben. Da es naheliegend ist, dass bei ein und demselben Probanden immer der gleiche lautliche Unterschied in Hinblick auf den italienischen Vibranten /r/ festgestellt werden kann, werden im Folgenden die Audioaufnahmen 0001_ruolo mit sieben Markierungen, 0004_terra mit neun verzeichneten Markierungen, 0013_parchi mit sieben Markierungen und 0018_terremoto mit acht getätigten Markierungen analysiert werden. Diese Auswahl beinhaltet alle Probanden, die eine besonders hohe Markierungsrate bei einem oder mehreren Wörtern vorweisen können und ermöglicht gleichzeitig, einerseits die Laute hinter dem Graphempaar <rr> und andererseits die Laute hinter dem Graphem <r> zu untersuchen. Zudem kann das Graphem <r> in den ausgewählten Sprachaufnahmen einmal hinsichtlich der initialen Position des <r>s und einmal hinsichtlich der mittleren Position des <r>s analysiert werden.
Die erste Analyse findet also bei der Aufnahme 0001_ruolo statt, die sieben Markierungen bei insgesamt elf Bearbeitungen erhalten hat und damit über dem Durchschnitt von drei Markierungen pro Sprecher liegt. Der Durchschnitt für Deutschland beträgt 3,2 und liegt damit nur knapp über dem Gesamtdurchschnitt, während der Durchschnitt in Österreich 2,8 und der Durchschnitt in der Schweiz ebenfalls 2,8 beträgt. Betrachtet man die Sprecher nur bezüglich ihres Herkunftslandes, können bei dem Wort ruolo [’ruɔːlo] ausschließlich anhand der Anzahl der Markierungen also kaum Unterschiede zwischen den deutschen, österreichischen und schweizerischen Sprechern festgestellt werden.
0001_ruolo
Die Markierungen, die für die Sprachaufnahme 0001_ruolo vorgefunden werden können, sind die folgenden:
r…o
ruo..
r….
r…o
r…o
r….
r….
Siebenmal wurde das initiale <r> im Wort ruolo markiert, wobei nur in vier von sieben Fällen weitere Grapheme, darunter das <u> sowie das mittlere und finale <o>, ausgewählt wurden. Betrachtet man die Sprachaufnahme in Praat, ergibt sich folgende Transkription, die zeigt, dass Proband 0001 das /r/ alveolar ausgesprochen und somit gerollt hat:
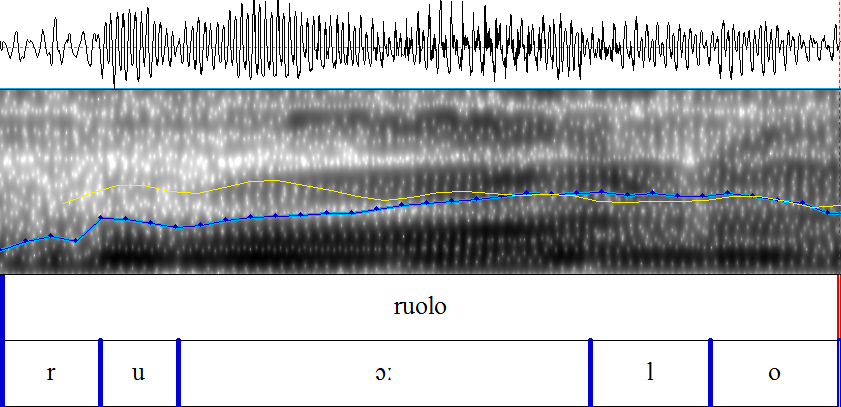
Oszillogramm, Sonogramm und Transkription der Sprachaufnahme 0001_ruolo
Doch wieso konnte der r-Laut so viele Markierungen generieren, obwohl die Probandin ihn nicht uvular ausgesprochen hat? Dies lässt sich vermutlich auf die Tatsache zurückführen, dass die Probandin aus Bayern stammt und den Dialekt Allgäuerisch beherrscht. In diesem Fall kann davon ausgegangen werden, dass die Aussprache des r-Lautes im muttersprachlichen Dialekt mit der italienischen Aussprache des Vibranten /r/ interferiert hat und deswegen zwar ein gerolltes r in der Sprachaufnahme vorhanden ist, die italienischen Testteilnehmer aber dennoch eine lautliche Differenz im Vergleich zur italienischen Sprache perzipiert haben.
Analysiert man die restlichen Sprachaufnahmen des Wortes ruolo und die produzierten Laute der Probanden, wird deutlich, dass 15 der 18 deutschsprachigen Sprecher den Vibranten /r/ nicht so stark gerollt wie die Italiener aussprechen, sondern eine weichere Variante des gerollten rs verwenden. Der r-Laut wird von der Mehrheit der deutschsprachigen Italienischlerner im Falle des Wortes ruolo also nicht uvular realisiert, spiegelt jedoch auch nicht exakt die italienische Aussprache wider.
Die nächste Aufnahme, die das Graphempaar <rr> zur Auswahl hatte und analysiert werden soll, ist die Sprachaufnahme 0004_terra, die wiederum von einem Probanden aus Deutschland stammt und elfmal bearbeitet wurde. Im Laufe des Perzeptionstests wurden bei der Aufnahme folgende neun Markierungen hinsichtlich des Graphempaares <rr> gesetzt:
..rr.
..rr.
..rr.
..rr.
..rr.
..rr.
..rr.
..rr.
..rr.
0004_terra
Interessant ist bei den Markierungen, die das Graphempaar <rr> beinhalten, zu sehen, dass in null von neun Fällen ein weiteres Graphem zum Graphempaar <rr> ausgewählt wurde und demnach gesagt werden kann, dass die lautliche Differenz beim r-Laut dominant war. Im Durchschnitt wurde das Graphempaar <rr> im Wort terra [’tɛrra] 3,4 Mal ausgewählt. Die deutschen Sprecher können bei dem Wort terra einen Durchschnittswert von 3,5 Markierungen verzeichnen, während dieser Wert bei den österreichischen Sprechern bei 3,0 Markierungen und bei den schweizerischen Sprechern bei 3,7 Markierungen liegt. Bindet man die Sprachaufnahme von Proband 0004 in das Analyseprogramm Praat ein, erscheint folgende Ansicht:
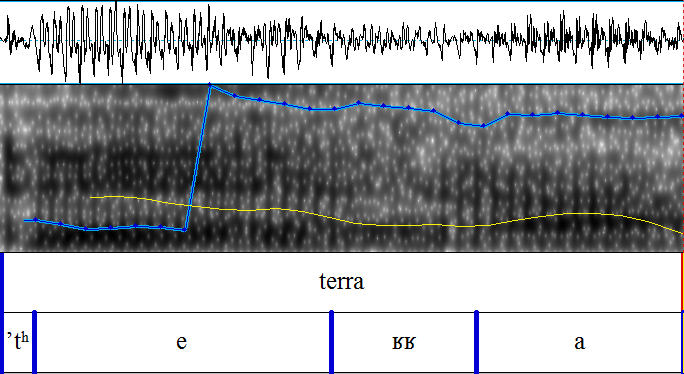
Oszillogramm, Sonogramm und Transkription der Sprachaufnahme 0004_terra
Die Transkription der Sprachaufnahme 0004_terra verdeutlicht, dass die Probandin 0004 für das Wort terra den Frikativ /ʁ/ verwendet hat und aus diesem Grund neun Markierungen bei elf Bearbeitungen und damit die Höchstanzahl aller Markierungen in Hinblick auf das Graphem <r> sowie das Graphempaar <rr> erhalten hat. Der r-Laut wird von der Probandin sehr schwach realisiert und wirkt dadurch nicht präsent. Bei dem Wort terra hat die allgemeine Analyse der Probanden aus Deutschland, Österreich und der Schweiz außerdem ergeben, dass acht von 18 Probanden den Vibranten /r/ produziert haben. Zwei von ihnen stammen aus Deutschland, drei aus Österreich und drei aus der Schweiz.
Die vorletzte Audioaufnahme, die im Zuge dieses Unterkapitels analysiert werden soll, ist Aufnahme 0013_parchi von einem Probanden aus der Schweiz, der bei insgesamt elf Bearbeitungen von Seiten der Testteilnehmer folgende Markierungen im Zuge des Online-Perzeptionstests für seine Sprachaufnahme erhalten hat:
..r..
..r..
.ar..
..r..
..rch.
.ar..
..r..
0013_parchi
Siebenmal wurde das Graphem <r> bei der Aufnahme 0013_parchi markiert und in zwei Fällen wurde zusammen mit dem Graphem <r> auch das Graphem <a> ausgewählt. Dies ist besonders interessant, da beim Anhören der Sprachaufnahme festgestellt werden kann, dass Proband 0013 bei dem Wort parchi [’parki] den r-Laut schlichtweg nicht ausspricht. Dass Proband 0013 parchi /’paki/ ausspricht, kann auch in der folgenden Praat-Ansicht erkannt werden20:
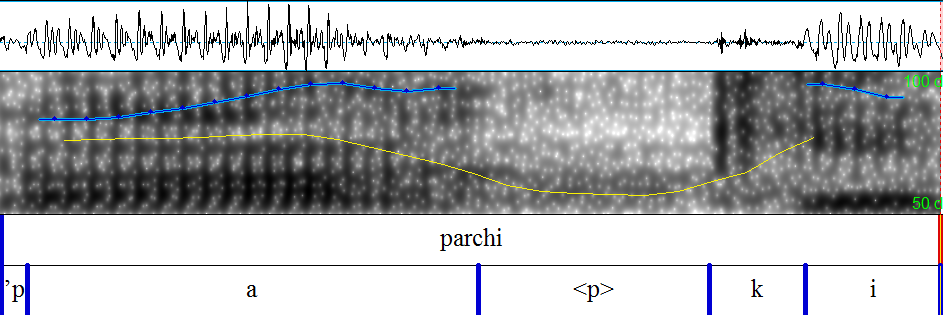
Oszillogramm, Sonogramm und Transkription der Sprachaufnahme 0013_parchi
Generell kann in Bezug auf die Aussprache des Wortes parchi die Feststellung getroffen werden, dass die italienischen Testteilnehmer im Schnitt nur 2,1 Markierungen des Graphems <r> ausgewählt haben und demnach weniger lautliche Differenzen als bei den zwei vorherigen Wörtern perzipiert haben. Die deutschen Sprecher weisen in Hinblick auf die Anzahl der markierten <r>s in parchi einen Durchschnittswert von 1,7 Markierungen auf, wohingegen die österreichischen Sprecher einen Durchschnittswert von 2,2 und die schweizerischen Sprecher einen Durchschnittswert von 2,3 Markierungen vorweisen können. Die Aufnahme 0013_parchi ist ein besonderer Fall, da der zu analysierende Laut nicht realisiert wurde, doch können bei den anderen deutschsprachigen Muttersprachlern uvulare sowie alveolare Aussprachen vorgefunden werden. Insgesamt haben die Probanden in fünf von 18 Fällen den italienischen Vibranten /r/ widergegeben und bei sieben von ihnen konnten das Phonem /ʀ/ registriert werden. Alles in allem waren die Probanden in Hinsicht auf das Wort parchi und seine Markierungen des Graphems <r> ansonsten eher unauffällig, was auch durch die niedrige Gesamtanzahl an Markierungen unterstrichen wird.
Die letzte Sprachaufnahme, die nun noch in Hinblick auf den r-Laut betrachtet werden soll, ist die Aufnahme 0018_terremoto, bei der das Graphempaar <rr> angeklickt werden konnte und die elfmal bearbeitet wurde. Die folgende Aufnahme hat insgesamt acht Markierungen erhalten:
..rremo..
..rre…o
..rre.o..
..rr..o..
.erre.o.o
t.rr…t.
..rr..ot.
..rr..ot.
0018_terremoto
Interessant ist zu sehen, dass das Graphempaar <rr> häufig, genauer gesagt in vier von acht Fällen, in Kombination mit dem folgenden Graphem <e> ausgewählt wurde. Im Schnitt konnten die deutschsprachigen Sprecher bei dem Wort terremoto eine Markierungsrate von 4,3 aufweisen, was den höchsten Durchschnittswert aller bisher analysierten ausgewählten Wörter darstellt. Die deutschen Sprecher haben im Durchschnitt 4,5 Markierungen, die österreichischen Sprecher 3,8 Markierungen und die schweizerischen Sprecher 4,7 Markierungen erhalten. Außer Proband 0018, der achtmal eine Markierung bekommen hat, gibt es drei weitere Sprecher, die jeweils sieben Markierungen vorweisen können.
Sieht man sich die Sprachaufnahme 0018_terremoto in Praat an, sieht sie wie folgt aus:
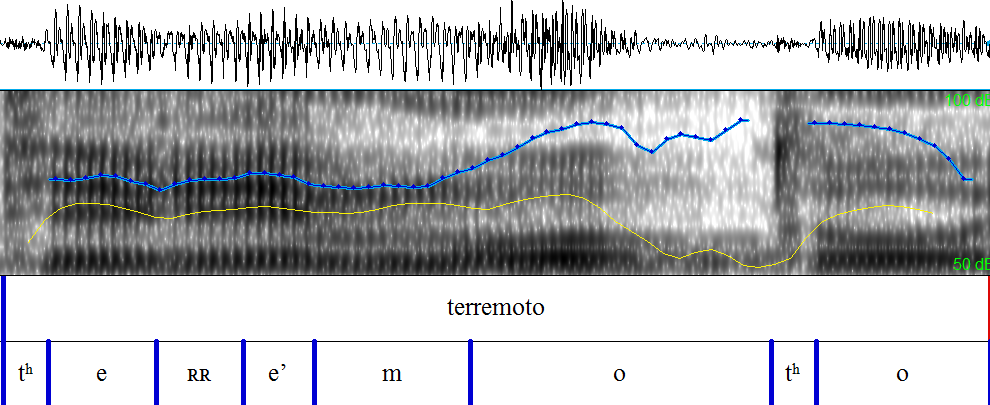
Oszillogramm, Sonogramm und Transkription der Sprachaufnahme 0018_terremoto
Abbildung 25 zeigt in Hinblick auf die Realisation des r-Lautes auf, dass Proband 0018 den Laut uvular realisiert hat und damit den geforderten Vibranten /r/ nicht wiedergibt, weswegen höchstwahrscheinlich die Markierungen bei dem Graphempaar <rr> gesetzt wurden. Eine uvulare Realisation kann bei acht weiteren Probanden festgestellt werden, während bei vier Probanden tatsächlich der Vibrant /r/ wiedergefunden werden kann. Da die Wörter terra und terremoto die meisten Markierungen erhalten haben, kann außerdem davon ausgegangen werden, dass die deutschsprachigen Sprecher mehr Schwierigkeiten bei der Realisation des doppelten r-Lautes als bei der Realisation des einfachen r-Lautes hatten. Die Position des Lautes innerhalb eines Wortes scheint allerdings nicht ausschlaggebend für eine korrekte oder inkorrekte Aussprache zu sein.
Nachdem in diesem Kapitel bereits die Laute /e/ und /ɛ/, /o/ und /ɔ/ sowie /r/ in Hinblick auf spezifische Sprecher der Länder Deutschland, Österreich und der Schweiz analysiert wurden, wird den Abschluss der Analyse der Sprachaufnahmen die Analyse des Phonems /t/ bilden.
4.4.4. Analyse von /t/
Den Abschluss der detaillierten lautlichen Analyse bildet der t-Laut, der im Perzeptionstest am vierthäufigsten markiert wurde. Da das Graphem <p> insgesamt relativ selten markiert wurde und beide Grapheme Plosive repräsentieren, soll der Fokus im Folgenden alleinig auf dem Phonem /t/ und seiner Realisation liegen. Insgesamt gibt es fünf Wörter, die den Laut ein- oder mehrmals in sich tragen: terra, terremoto, risposta, lento sowie tè. Diese Wörter konnten im Verlauf des Online-Perzeptionstests 65 Markierungen verzeichnen, die alle Sprecher aus allen Ländern betreffen. Da in Kapitel 2.3.2. Konsonantenrealisation deutscher Sprecher bereits erläutert wurde, dass Plosive im Deutschen stärker und gespannter als in anderen Sprachen ausgesprochen werden und zugleich oftmals von einer Aspiration begleitet werden, kann allgemein zunächst vermutet werden, dass sich diese Phänomene hinter den Markierungen des Graphems <t> verbergen.
Die Verteilung des markierten Graphems <t> kann in der folgenden Abbildung 26 begutachtet werden. Da das Graphem <t> am vierthäufigsten ausgewählt wurde, liegt der Gesamtmarkierungswert, und damit auch der Maximalwert der markierten Grapheme <t>, unter den Werten der anderen analysierten Grapheme.
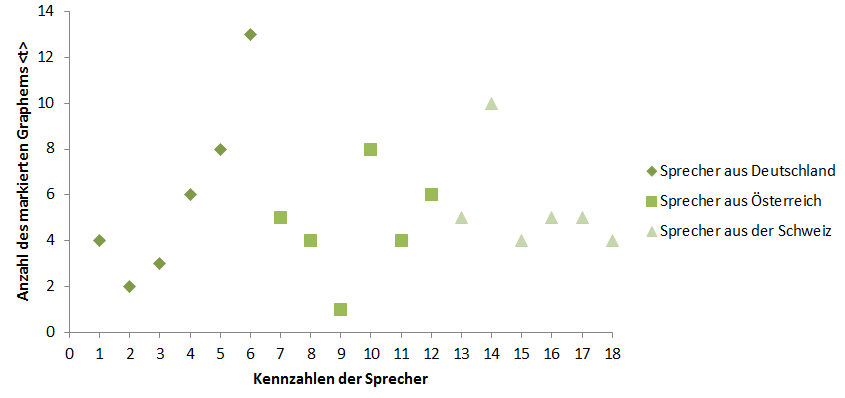
Verteilung des markierten Graphems <t> nach Sprechern
Abbildung 26 zeigt eine weitere heterogene Verteilung der markierten Grapheme nach Sprechern und dementsprechend auch nach Ländern auf. Unter den deutschen Probanden befindet sich der Sprecher mit den meisten Markierungen des Graphems <t> und unter den österreichischen Probanden der Sprecher mit den geringsten Markierungen des Graphems. Bei den deutschen Sprechern wurden zwischen zwei und 13 Markierungen gesetzt, wodurch sie einen Durchschnittswert von 6,0 Markierungen aufweisen, bei den österreichischen Sprechern wurden hingegen zwischen eine und acht Markierungen gesetzt, was zu einem Durchschnittswert von 4,7 führt, und die Sprecher aus der Deutschschweiz weisen zwischen vier und zehn Markierungen auf und haben dadurch einen Durchschnittswert von 5,5. Die meisten Markierungen, nämlich 36, lassen sich also bei den Sprechern aus Deutschland feststellen. Die Schweiz folgt mit 33 Markierungen und Österreich weist mit 28 Markierungen die niedrigste Anzahl an Markierungen auf. Beachtenswert ist in diesem Fall die Tatsache, dass sich die Gesamtanzahl der Markierungen nach Land nicht stark voneinander unterscheidet, sondern alle drei Länder ungefähr 30 Markierungen erhalten haben. Des Weiteren lassen sich bei den deutschen und österreichischen Sprechern große sprecherspezifische Unterschiede feststellen, da die minimale und maximale Anzahl von Markierungen bei den deutschen Sprechern eine Diskrepanz von über zehn Markierungen aufzeigt und bei den österreichischen Sprechern ebenfalls eine Diskrepanz von sieben Markierungen nachgewiesen werden kann. Bei den schweizerischen Sprechern zeigt sich jedoch eine starke sprecherbezogene Homogenität, da fünf von sechs Probanden vier oder fünf Markierungen aufweisen und damit sehr eng zusammenliegen. Nur Proband 0014 zeigt eine höhere Anzahl an Markierungen auf und setzt sich mit zehn Markierungen ab.
Die meisten Markierungen haben die Probanden mit den Kennzahlen 0006, 0014, 0005 und 0010 erhalten. Bei Proband 0006 haben die italienischen Testteilnehmer 13 Mal, bei Proband 0014 zehnmal und bei Proband 0005 sowie 0010 jeweils achtmal das Graphem <t> markiert. Wirft man einen Blick auf die persönlichen Daten, die die Probanden zu Beginn der Aufnahmen angeben mussten, kann festgestellt werden, dass die Probanden 0005 und 0006 seit acht bzw. fünf Jahren Italienisch lernen und beide das Sprachniveau C1 in Italienisch besitzen, den Masterstudiengang Italienstudien studieren, drei weitere Fremdsprachen sprechen, von denen zwei den romanischen Sprachen zugeordnet werden können, beide Sprecher regelmäßigen Kontakt zu italienischen Muttersprachlern haben und sogar einen Auslandsaufenthalt in einem italienischsprachigen Land genossen haben. Proband 0010 lernt ebenfalls seit fünf Jahren Italienisch und besitzt das Niveau C1, befindet sich im Masterstudiengang Translation, spricht keine weitere romanische Sprache und hat regelmäßigen Kontakt zu italienischen Muttersprachlern. Proband 0014 ist in diesem Fall der einzige Proband, der keine Sprachen studiert, doch lernt auch er bereits seit fünf Jahren Italienisch, besitzt das Niveau B2, spricht eine weitere romanische Sprache und hat sechs Monate im Ausland verbracht. Diesen Angaben zufolge weisen die Sprecher mit den meisten Markierungen ein hohes Niveau der italienischen Sprache auf, weswegen nicht vermutet werden kann, dass die lautlichen Unterschiede, die von den italienischen Testteilnehmern wahrgenommen wurden, mit dem Sprachniveau der Probanden zusammenhängt. Vielmehr liegt die Vermutung nahe, dass trotz eines hohen Sprachniveaus Interferenzen zwischen der deutschen und der italienischen Sprache auftreten. Wahrscheinlich ist zudem, dass die Sprecher 0005, 0006, 0010 sowie 0014 eine starke Aspiration bei der Realisierung von /t/ aufweisen und dies eventuell zu der erhöhten Anzahl an Markierungen beigetragen hat.
Nachdem ein Überblick über die Sprecher und ihre erhaltenen Markierungen in Bezug auf das Graphem <t> gegeben wurde, soll nun auch bei der letzten lautlichen Analyse eine Darstellung der Verteilung des markierten Graphems <t> nach Sprechern und Wörtern folgen, um die interessantesten Sprachaufnahmen herauszufiltern und diese im Folgenden analysieren zu können.
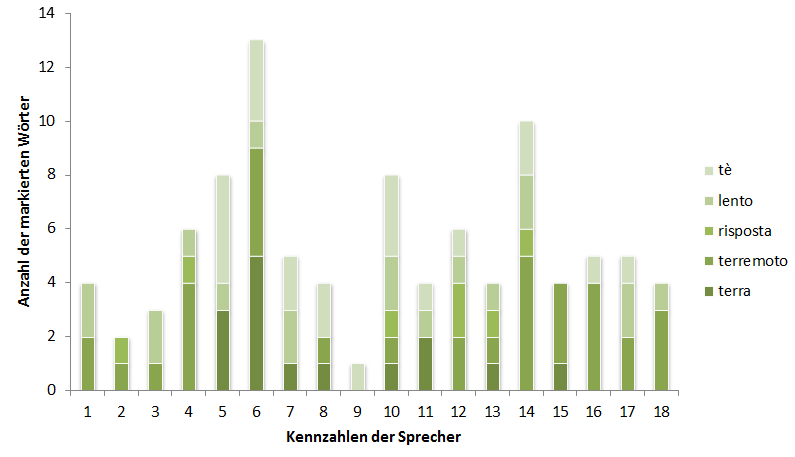
Anzahl der Markierungen von <t> nach Wörtern und Sprechern
Betrachtet man die Verteilung der markierten Grapheme <t> nach Sprechern und Wörtern, die in Abbildung 27 veranschaulicht wird, fällt auf, dass nur bei Proband 0010 alle Wörter Markierungen des Graphems <t> erhalten haben und die restlichen Probanden Markierungen bei maximal vier und mindestens einem Wort aufweisen. Generell kann konstatiert werden, dass bei dem Wort risposta die wenigsten und bei dem Wort terremoto die meisten Markierungen durch die italienischen Testteilnehmer stattgefunden haben. Das Wort terra kann hinsichtlich aller Sprecher 15 Markierungen aufweisen, während das Wort terremoto 34 Markierungen, das Wort risposta sieben Markierungen, das Wort lento 19 Markierungen und das Wort tè 21 Markierungen erhalten hat.
Auffällig sind die Probanden 0005, 0006 sowie 0014, die bei den Wörtern tè, terra und terremoto eine überdurchschnittlich hohe Anzahl an Markierungen des Graphems <t> erhalten haben. Deswegen sollen im Folgenden die Sprachaufnahmen 0005_tè, 0006_terra und 0014_terremoto in Bezug auf den Laut /t/ analysiert werden. Insbesondere soll bei der Analyse auf die Position der ausgewählten Grapheme <t> geachtet werden, da diese initial oder in der Mitte des Wortes vorzufinden sein können. Dies soll Aufschluss darüber geben, ob die Position des Plosivs /t/ die Aussprache erschwert oder erleichtert.
0005_tè
Die Aufnahme 0005_tè, die als erste analysiert werden soll, hat im Perzeptionstest die folgenden vier Markierungen bei zwölf Bearbeitungen erhalten:
t.
t.
t.
t.
Durchschnittlich wurden bei den Sprachaufnahmen, die das Wort tè betreffen, 1,2 Markierungen vergeben, was deutlich zeigt, dass die Aufnahme 0005_tè mit ihrer Anzahl von vier Markierungen über dem Durchschnitt liegt. Die deutschen Sprecher, zu denen auch Proband 0005 zählt, haben einen Durchschnittswert von 1,2 Markierungen erreicht, während die österreichischen Sprecher bei einem Durchschnittswert von 1,7 Markierungen und die schweizerischen Sprecher bei einem Durchschnittswert von 0,7 Markierungen angelangt sind. Interessant ist also zu sehen, dass ein deutscher Sprecher die häufigsten Markierungen erhalten hat, durchschnittlich gesehen aber die österreichischen Sprecher die meisten Markierungen erhalten haben. Wichtig ist hierbei jedoch auch der Einbezug der Tatsache, dass vier der sechs deutschen Sprecher für das Wort tè keine Markierungen vorweisen können und demnach lediglich die Probanden 0005 sowie 0006 für die Gesamtzahl der Markierungen bei den deutschen Sprechern verantwortlich sind. Von den österreichischen Sprechern hat hingegen jeder Proband mindestens eine Markierungen erhalten, aber niemand mehr als drei Markierungen. Die schweizerischen Sprecher zeigen in der Hinsicht eine ähnliche Tendenz wie die deutschen Sprecher auf, dass nur drei der sechs Probanden Markierungen des Graphems <t> erhalten haben, lehnen sich aber von der maximalen Anzahl der Markierungen pro Sprecher an die österreichischen Sprecher an, da die Sprecher aus der Schweiz, sofern sie markierte Grapheme vorweisen können, maximal zwei Markierungen erhalten haben.
Doch warum kann die Aufnahme 0005_tè überdurchschnittlich viele Markierungen des Graphems <t> verzeichnen?
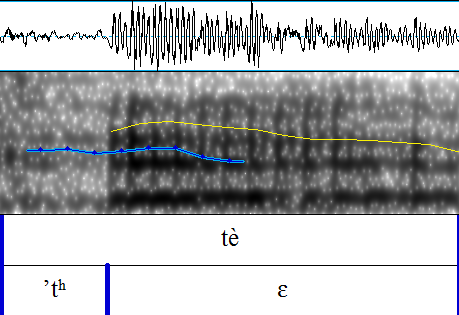
Oszillogramm, Sonogramm und Transkription der Sprachaufnahme 0005_tè
Betrachtet man die Sprachaufnahme 0005_tè und ihr Sonogramm in Praat, kann eine geringe Aspiration bei dem Laut /t/ erkannt werden, doch scheint die Aussprache des deutschen Probanden ansonsten nicht weiter von der italienischen Standardaussprache abzuweichen. Bei der Realisierung des Plosivs /t/ kann auch bei 16 weiteren Teilnehmern eine geringe bis sehr deutliche Aspiration vorgefunden werden, doch stellt die Aufnahme 0005_tè diejenige mit den meisten Markierungen dar. Die Testteilnehmer, die das <t> ausgewählt haben, haben die Aufnahme ein- bis zehnmal angehört, in drei von vier Fällen mit einem Smartphone den Test gemacht und außerdem haben zwei von den Testteilnehmern angegeben in Deutschland bzw. in der Schweiz sowie in Spanien gelebt zu haben. Drei der vier Testteilnehmer sprechen überdies Deutsch und jeweils zwei Testteilnehmer stammen aus dem Norden und zwei aus dem Süden Italiens. Anhand dieser Angaben können wenige Parallelen festgestellt werden und keine Rückschlüsse auf den Grund für die Auswahl des Graphems <t> gezogen werden. In zwei Fällen wurde die Sprachaufnahme aber dem richtigen Herkunftsland zugeordnet, weswegen die Möglichkeit besteht, dass die Probanden aufgrund ihrer Kenntnisse des Deutschen feststellen konnten, dass es sich bei dieser Aufnahme um keinen Italiener handelt.
Eine weitere Aufnahme, die im Zuge der Analyse des t-Lautes untersucht werden soll, ist die Sprachaufnahme 0006_terra, die einem deutschen Sprecher zugeordnet werden kann und von den italienischen Testteilnehmern folgende Markierungen bei 14 Bearbeitungen erhalten hat:
t…
t…
t…
t…
te..
0006_terra
In vier der fünf Markierungsfälle wurde das Graphem <t> als einziges Graphem ausgewählt und nur in einem der fünf Markierungsfälle wurde zusätzlich das Graphem <e> markiert. Das Wort terra [’tɛrra] wurde mit insgesamt 15 Markierungen am zweitseltensten für Markierungen des Graphems <t> ausgewählt und weist einen Durchschnittswert von 0,8 Markierungen, die alle Sprecher betreffen, auf. Dies bedeutet, dass jeder Sprecher im Schnitt weniger als eine Markierung erhalten hat und somit besonders wenige lautliche Unterschiede in Hinblick auf den Plosiv /t/ bei dem Wort terra perzipiert werden konnten. Der Durchschnittswert für die deutschen Sprecher liegt bei 1,3 Markierungen, für die österreichischen Sprecher bei 0,8 Markierungen und für die schweizerischen Sprecher bei 0,3 Markierungen. Die deutschen Sprecher haben also ein weiteres Mal den höchsten Durchschnittswert, doch muss auch in diesem Fall erwähnt werden, dass nur die Probanden 0005 und 0006 Markierungen erhalten haben und somit bei vier von sechs deutschen Sprechern keine lautlichen Unterschiede in Hinblick auf den Plosiv /t/ perzipiert wurden. Bei den österreichischen Sprechern ist zu sehen, dass vier von sechs Sprechern Markierungen aufgrund ihrer Sprachaufnahmen erhalten haben und bei den Sprechern aus der Deutschschweiz lediglich bei zwei Probanden Markierungen gesetzt wurden. Generell erscheint der t-Laut in Hinblick auf alle drei deutschsprachigen Länder also eher unauffällig. Sieht man sich die Sprachaufnahme 0006_terra in Praat an, erscheint folgende Ansicht:
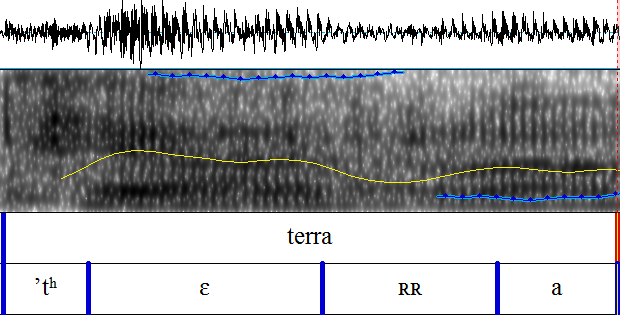
Oszillogramm, Sonogramm und Transkription der Sprachaufnahme 0006_terra
Bei der Betrachtung der Sprachaufnahme 0006_terra in Praat ist auffällig, dass der Proband zu Beginn des Wortes sehr stark aspiriert, was höchstwahrscheinlich der Grund für die erhöhte Anzahl an Markierungen des Graphems <t> bei dieser Aufnahme ist. Proband 0006 ist der Sprecher mit der am stärksten ausgeprägten Aspiration bei den Plosiven /t/ und /p/ und hat aus diesem Grund häufiger Markierungen als andere Probanden erhalten. Diese starke Aspiration lässt sich folglich nicht nur bei der Aufnahme 0006_terra feststellen, sondern kann unter anderem auch bei der Aufnahme 0006_terremoto vorgefunden werden, die vier Markierungen des Graphems <t> erhalten hat und damit wiederum den maximal vergebenen Markierungswert aufweist. Der durch die italienischen Sprecher perzipierte lautliche Unterschied scheint in diesem Fall sprecherbezogen zu sein, da vier von sechs deutschen Sprechern keine ausgewählten <t>s aufweisen, die lautlichen Unterschiede demnach nicht wortspezifisch sind, und kein Land durch seine Anzahl an markierten Graphemen hervorsticht, weswegen es sich auch um keinen länderspezifischen Unterschied handelt.
Die letzte Aufnahme, die im Zuge dieses Teilkapitels analysiert werden soll, stammt von Proband 0014, der der Schweiz zugehörig ist und den vier Markierungen bei zwölf Bearbeitungen des Graphems <t> bei der Aufnahme 0014_terremoto betreffen:
….moto
..rr..ot.
t.rr..ot.
…..ot.
0014_terremoto
Fünfmal wurde bei der Sprachaufnahme 0014_terremoto das <t> ausgewählt und die Aussage getroffen, dass an dieser Stelle lautliche Unterschiede in Bezug auf die italienische Sprache konstatiert werden können. Interessant ist zu sehen, dass das initiale <t> nur einmal markiert wurde, während bei dem zweiten <t> viermal lautliche Unterschiede gekennzeichnet wurden. In den vorherigen Aufnahmen, die überdurchschnittlich viele Markierungen erhalten haben, stand immer das initiale <t> im Vordergrund, doch in diesem Fall scheint der wahrgenommene lautliche Unterschied nicht am Anfang des Wortes terremoto [terre’mɔːto] zu liegen.
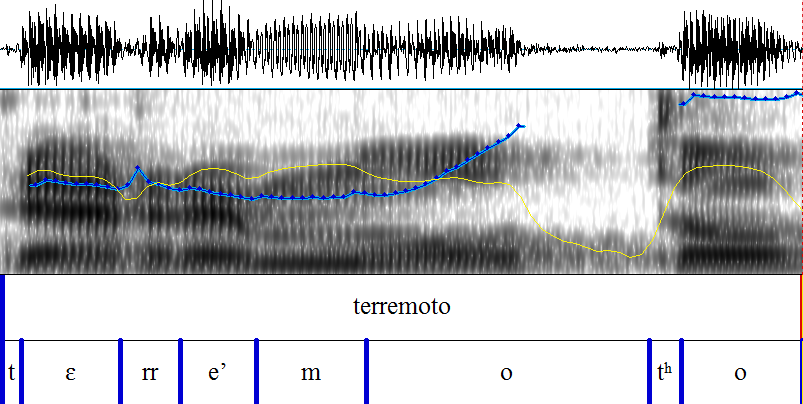
Oszillogramm, Sonogramm und Transkription der Sprachaufnahme 0014_terremoto
Die Darstellung der Sprachaufnahme 0014_terremoto in Praat zeigt deutlich, dass eine starke Aspiration bei dem zweiten Plosiv /t/ vorhanden ist. Dies ist wahrscheinlich der Grund, warum Proband 0014 vier Markierungen an dieser Stelle erhalten hat. Im Schnitt haben die deutschen Sprecher 2,0 Markierungen, die österreichischen Sprecher 1,0 Markierungen und die schweizerischen Sprecher, zu denen Proband 0014 zählt, 3,0 Markierungen bei den vorhandenen Graphemen <t> im Wort terremoto erhalten. Vergleicht man die restlichen Probanden mit Proband 0014, ist zu erkennen, dass alle der 18 Probanden eine Aspiration beim zweiten /t/ aufweisen. Da bei dem Wort terremoto die meisten Markierungen hinsichtlich des Graphems <t> gesetzt wurden, kann davon ausgegangen werden, dass die hohe Anzahl an Markierungen, die bei dem Graphem <t> nicht so deutlich wie bei den Graphemen <e>, <è>, <o>, <r> und dem Graphempaar <rr> ausgefallen ist, mit der Aspiration und der gespannteren Aussprache des Plosivs der deutschsprachigen Italienischlerner zusammenhängt.
Auf die Frage, ob die Position des Plosivs /t/ die Aussprache für die deutschsprachigen Italienischlerner erschwert oder nicht, kann geantwortet werden, dass sowohl Markierungen am Anfang als auch innerhalb eines Wortes vorgefunden werden konnten und sich die Anzahl dieser Markierungen kaum voneinander unterscheidet. Demzufolge scheint die Position des Plosivs /t/ unerheblich für die korrekte Realisation des Lautes zu sein.
Diese Analyse bildet bereits das Ende der qualitativen Analyse der Sprachaufnahmen ausgewählter Sprecher, bei denen überdurchschnittlich viele Markierungen in Hinblick auf die untersuchten Laute konstatiert werden konnten. Eine Zusammenfassung aller Forschungsergebnisse sowie Kritik an der durchgeführten Studie und ein Ausblick auf weitere Forschungsansätze wird nun im nächsten Kapitel folgen.
5. Zusammenfassung und Forschungsausblick
Nachdem in den vorherigen Kapiteln die Ergebnisse des Perzeptionstests auf Basis der Perzeption durch die italienischen Testteilnehmer sowie unter Einbezug der einzelnen Sprachaufnahmen und ihrer Transkriptionen dargestellt und erläutert wurden, soll nun zunächst eine Zusammenfassung der Ergebnisse sowie eine kurze Methodenkritik folgen und im Anschluss an ebendiese über weitere Forschungsansätze mit Blick auf L1 interferierte lautliche Merkmale beim Italienischerwerb deutschsprachiger Lerner diskutiert werden.
Die Auswertung der Daten des Perzeptionstests wurde in drei verschiedenen Schritten durchgeführt: zunächst stand die allgemeine Auswertung der Perzeption von lautlichen Differenzen im Vordergrund, dann die Länderzuordnung der Sprachaufnahmen und zuletzt die detaillierte Analyse ausgewählter Sprachaufnahmen in Hinblick auf die meistmarkierten Grapheme und Graphempaare, die bei der allgemeinen Auswertung der perzipierten lautlichen Differenzen festgestellt werden konnten.
Im ersten Schritt der Analyse wurde also die Perzeption der lautlichen Differenzen auf allgemeiner Basis analysiert und es konnte konstatiert werden, dass bei den Phonemen /e/ und /ɛ/, /o/ und /ɔ/, /r/ sowie /t/ die meisten lautlichen Differenzen und Interferenzen auf Seiten der deutschsprachigen Italienischlerner durch die italienischen Testteilnehmer festgestellt werden konnten. Damit wurden die in den Kapitel zum deutschen und italienischen Lautsystem aufgestellten Hypothesen, dass bei den deutschsprachigen Italienischlernern Schwierigkeiten und Ungenauigkeiten bei der Unterscheidung von offenen und geschlossenen Vokalen vorliegen könnten, bestätigt und gleichzeitig gezeigt, dass auch der Plosiv <t> häufig markiert wurde. Interessant war in dieser Hinsicht zu beobachten, dass der Plosiv /p/ tatsächlich für eine eher geringe Anzahl an Markierungen verantwortlich war und infolgedessen nur selten Unterschiede in Hinblick auf die italienische Standardaussprache bemerkt werden konnten. Vergleicht man die Anzahl an Markierungen der ausgewählten Vokale und des r-Lautes mit denen des Plosivs /t/, ist des Weiteren zu erkennen, dass die Differenzen der absoluten Markierungen relativ hoch sind und der Plosiv demnach nicht für die am häufigsten perzipierten lautlichen Differenzen verantwortlich war. Erwähnenswert ist jedoch, dass ein lautlicher Unterschied bei dem Plosiv /t/ besonders oft mit Deutschland in Verbindung gebracht wurde, während die Länder Österreich und die Schweiz wesentlich seltener ausgewählt wurden. Von den Lauten, die in den Eingangshypothesen nicht genannt wurden, hat die Aussprache des Vokals /a/ hingegen zu den meisten Markierungen geführt. Leider war der Markierungswert aber zu gering, um in der detaillierten Analyse der Sprachaufnahmen näher betrachtet zu werden. Sollte in dieser Hinsicht weitergeforscht werden, wäre es dennoch mit Sicherheit interessant, die aufgenommenen Sprachaufnahmen in Hinblick auf den Vokal /a/ auszuwerten und zu analysieren, welche lautlichen Differenzen sich bei ebendiesem ergeben haben. Bei der Gegenüberstellung der markierten Grapheme und Graphempaare nach Ländern konnte außerdem festgestellt werden, dass die schweizerischen Sprecher im Ländervergleich den höchsten Wert an Markierungen erzielt haben. Im Gegenzug konnten bei den österreichischen Sprechern jeweils die niedrigsten Markierungsraten vorgefunden werden. Die deutschen Sprecher liegen demnach zwischen den Ländern Österreich und der Schweiz, was die Wahrnehmbarkeit der lautlichen Differenzen betrifft. Dieses Ergebnis ist in der Hinsicht überraschend, dass die Schweiz ein polyglottes Land ist und die Sprachen Deutsch, Französisch, Italienisch sowie Rätoromanisch unter sich vereint. Diese Tatsache führt dazu, dass schweizerische Sprecher normalerweise besonders früh mit der italienischen Sprache in Kontakt kommen und regelmäßiger der italienischen Sprache ausgesetzt sind, da sich auch viele italienische Muttersprachler in der Deutschschweiz befinden.
Durch den zweiten Auswertungsschritt, der die Analyse der Länderzuordnung umfasst hat, konnte zum einen erfasst werden, dass die italienischen Testteilnehmer lautliche Differenzen überdurchschnittlich oft mit den Sprechern aus Deutschland verbunden haben und die Anzahl an markierten lautlichen Differenzen bei den Ländern Österreich und Schweiz sehr ähnlich ausgefallen ist und zum anderen, dass sich die italienischen Testteilnehmer in 34,5% aller Fälle für das Land Italien als Herkunftsland der Italienischlerner entschieden haben. Die deutschsprachigen Italienischlerner, die am häufigsten anhand ihrer Sprachaufnahmen nach Italien verortet wurden, konnten ein sehr hohes Sprachniveau, genauer gesagt ein Niveau von C1 bzw. C2, des Italienischen vorweisen und hatten die Gemeinsamkeiten, dass sie regelmäßigen Kontakt zu italienischen Muttersprachlern pflegen und einen längeren Auslandsaufenthalt von fast einem Jahr in Italien absolviert haben. Interessant war bei der Auswertung zu sehen, dass andere Sprecher mit sehr guten Italienischkenntnissen und regelmäßigem Kontakt zu italienischen Muttersprachlern, sei es im Wohnort oder im Ausland, ebenfalls oft nach Italien verortet wurden, aber ein Unterschied in der Anzahl der Verortungen dennoch gegeben war und sich dieser oftmals auf einen fehlenden Auslandsaufenthalt der Probanden, der als einziges Indiz für den vorhanden Unterschied erfasst werden konnte, zurückführen ließ. Die sprachlichen Kompetenzen, die während eines Auslandaufenthaltes vermittelt werden, scheinen zumindest bei den aufgenommenen deutschsprachigen Sprechern ein wichtiger Faktor bei der Zuordnung nach Italien gewesen zu sein und es kann davon ausgegangen werden, dass ein Auslandsaufenthalt besonders hilfreich für die Verringerung lautlicher Interferenzen im Italienischen ist.
Des Weiteren konnte ermittelt werden, dass nur 16,6% der Sprachaufnahmen korrekt zugeordnet werden konnten, und demnach die Aussage getroffen werden kann, dass die italienischen Testteilnehmer nur einzelne Aufnahmen korrekt zuweisen und im Großen und Ganzen keine präzise Unterscheidung zwischen den Italienischlernern aus Deutschland, Österreich und der Schweiz machen konnten. Zusammenfassend kann in Hinblick auf die Länderzuordnung der Sprachaufnahmen also festgehalten werden, dass die deutschsprachigen Italienischlerner untereinander keine so großen lautlichen Differenzen in der Aussprache des Italienischen aufweisen, dass sie klar voneinander unterschieden werden könnten, und deutschsprachige Lerner tatsächlich einen Punkt in ihrem Prozess des Fremdsprachenerlernens erreichen können, an dem sie anhand lautlicher Differenzen, die durch Interferenzen der deutschen Muttersprache entstehen können, nur in seltenen Fällen von italienischen Muttersprachlern distinguiert werden können.
Die finale detaillierte Analyse ausgewählter Sprachaufnahmen hat schließlich ergeben, dass die Laute /e/ und /ɛ/ zu den L1 interferierten lautlichen Merkmalen deutscher Italienischlerner gezählt werden können, da diese Merkmale bei allen Sprechern, und somit auch in allen der drei vertretenen deutschsprachigen Ländern, vorgefunden werden konnten. Besonders oft konnten Interferenzen bei den österreichischen und schweizerischen Sprechern in Hinblick auf den Laut /ɛ/ festgestellt werden, da sie diesen meistens als /e/ realisiert haben. Der Laut /ə/ konnte in 18 Fällen im Auslaut der Wörter pane, eppure und cooperazione vorgefunden werden und wurde demnach in 33,3% der möglichen Fälle verwendet. Bei einem Drittel der Auslaute konnten also Interferenzen durch das Deutsche festgestellt werden, wobei die deutschen Sprecher dabei einen Anteil von 16,7%, die österreichischen Sprecher einen Anteil von 11,1% und die schweizerischen Sprecher einen Anteil von 5,6% ausmachen. Die deutschen Sprecher haben demzufolge am häufigsten den Laut /ə/ produziert, der vor allem bei den Aufnahmen des Wortes cooperazione registriert werden konnte.
Die differenzierte Analyse der Laute /o/ und /ɔ/ hat zudem ergeben, dass die Mehrheit der Sprecher Schwierigkeiten bei der korrekten Realisierung ebendieser hat und sich dieses Phänomen über alle Länder erstreckt. Die schweizerischen Sprecher konnten die meisten Markierungen in Hinblick auf das Graphem <o> verzeichnen, während die österreichischen Sprecher die wenigsten Markierungen des Graphems <o> erhalten haben. Interessant war bei der Analyse der Laute /o/ und /ɔ/ überdies zu sehen, dass eine höhere Heterogenität im Vergleich zu den Lauten /e/ und /ɛ/ in Bezug auf die Sprecher vorherrschte und sie folglich eine sehr unterschiedliche Anzahl an Markierungen vorweisen konnten. Die Wörter, bei denen die meisten Markierungen gesetzt wurden, waren terremoto, cooperazione sowie ruolo und bei ihnen konnten sowohl Realisierungsschwierigkeiten in Hinblick auf die Attribute ‚offen‘ oder ‚geschlossen‘ festgestellt werden als auch herausgefunden werden, dass auch in Hinblick auf die Länge der Laute /o/ und /ɔ/ Diskrepanzen im Vergleich zur italienischen Sprache bestehen.
Die Analyse von /r/ hat überdies gezeigt, dass die wenigsten deutschsprachigen Sprecher den r-Laut typisch italienisch als /r/ realisieren. Manchmal wird er mit einem uvularen /ʀ/ oder in seltenen Fällen mit dem Frikativ /ʁ/ wiedergegeben und in anderen Fällen findet sich ein leichtes Rollen bei den Probanden wieder, das an das Phonem /ɾ/ erinnert. Die meisten Markierungen konnten bei den Sprechern aus der Schweiz vorgefunden werden, während die Sprecher aus Österreich die wenigsten Markierungen bei dem Graphem <r> und dem Graphempaar <rr> erhalten haben. Dem muss allerdings hinzugefügt werden, dass die deutschen Sprecher insgesamt nur zwei Markierungen mehr als die österreichischen Sprecher verzeichnen konnten. Wie bei den Lauten /o/ und /ɔ/ konnte überdies auch bei der Analyse von /r/ eine sehr hohe Diskrepanz mit Blick auf die Sprecher festgestellt werden, was zeigt, dass die korrekte Realisation des Lautes nicht länder- sondern vielmehr sprecherabhängig ist.
Nach Analyse von /t/ kann des Weiteren die Aussage getroffen werden, dass zwar bei jedem Sprecher lautliche Unterschiede von den italienischen Testteilnehmern perzipiert wurden, die Gesamtanzahl an Markierungen nach Sprecher jedoch stark variiert und einzelne Sprecher, wie Proband 0009 und Proband 0002, insgesamt nur eine oder zwei Markierungen des Graphems <t> erhalten haben und damit zeigen, dass bei ihnen lautliche Unterschiede in Hinblick auf den Plosiv /t/ nur sehr selten wahrgenommen werden können. Die meisten Markierungen des Graphems <t> konnten die deutschen Sprecher verzeichnen, während bei den österreichischen Sprechern die wenigsten Markierungen gesetzt wurden. Eine starke Aspiration kann auf Seiten der Italiener perzipiert werden, doch scheint eine normale Aspiration, die bei deutschsprachigen Sprechern der Norm entspricht und bei 95% aller Sprachaufnahmen vorhanden war, nicht zwangsläufig perzipiert werden zu können bzw. zu einer Markierung zu führen und demzufolge keine allzu große Abweichung zur italienischen Standardaussprache darzustellen.
Nach der Rekapitulation der Ergebnisse, die durch den Online-Perzeptionstest und die Sprachanalyse ermittelt werden konnten, soll nun eine kurze Methodenkritik folgen. Im Fokus wird dabei die Frage stehen, inwiefern der Studienaufbau verbessert werden kann, welche Probleme sowohl bei den Aufnahmen als auch bei der Auswertung entstanden sind und wie ebendiese zukünftig vermieden werden könnten.
Bei der Festlegung der Trägersätze hätte beispielsweise noch genauer darauf geachtet werden können, dass sich die zu untersuchenden Vokale in einer konsonantischen Umgebung befinden. Zwar haben die einzelnen Trägersätze, die diese Regeln nicht vollständig beachtet haben, zu keinen Problemen bei der Erfassung und Auswertung der Ergebnisse geführt, doch musste beim Schneiden der Sprachaufnahmen mehr Zeit aufgewendet werden, um die Grenzen zwischen den angrenzenden Vokalen zu finden und diese präzise zu definieren. Des Weiteren würden Testaufnahmen eines Testprobanden der zu verwendenden Trägersätze sicherlich hilfreich sein, um zu erkennen, welche Sätze für Aufnahmen gut geeignet sind und bei welchen Sätzen eventuell Probleme, sei es anhand ihrer Länge oder durch die Wortwahl innerhalb der Sätze, auftreten könnten. Dieses Vorgehen wurde aus zeitlichen Gründen bei dieser Arbeit nicht in Betracht gezogen und hätte vermutlich auch zu keinen Änderungen geführt, da die deutschsprachigen Italienischlerner während der Aufnahmen die Sätze wiederholen durften, sofern sie sich versprochen hatten, doch wäre ein solcher Testdurchlauf für eine größer angesetzte Studie sicherlich von Vorteil.
Wendet man sich dem genutzten Online-Perzeptionstest zu, kann auch hier Kritik geübt werden. Der Aufbau des Tests und die Möglichkeiten, die durch ihn gegeben waren, können nur als vorteilhaft bezeichnet werden. Dennoch konnten einige technische Komplikationen während der Durchführung des Perzeptionstests festgestellt werden, wie beispielsweise das Problem, dass etliche Testteilnehmer nur eine gewisse Anzahl an Aufnahmen bearbeiten konnten, bis sich das System plötzlich blockiert hat, und es gilt, diese zu verringern, bevor weitere Tests durchgeführt werden können. Außerdem steht weiterhin die Frage im Raum, ob die Eingaben, bei denen ein Land, aber kein Graphem ausgewählt wurde, lediglich auf ein technisches Problem zurückzuführen sind oder ob die italienischen Testteilnehmer die Aufgabenstellung nicht verstanden bzw. nicht gelesen haben. Um in Zukunft Verständnisprobleme zu vermeiden, könnte zumindest bei einem Testaufbau, der nur eine geringe Anzahl an Arbeitsschritten umfasst, eine Animation erstellt werden, die den Ablauf des Perzeptionstests zu Beginn exemplarisch aufzeigt. Eine solche Animation könnte durch eine Kombination von Momentaufnahmen, die zusätzlich nummeriert oder beschriftet werden könnten, mit einem gemeinen GIF Animator erstellt und beispielsweise auf einer neuen Seite nach der Eingabe der soziodemographischen Daten abgespielt werden. Der Online-Perzeptionstest hat zudem gezeigt, dass die Länderzuordnung einzelner deutschsprachiger Sprecher anhand eines einzelnen italienischen Wortes sehr schwierig ist, weswegen die Überlegung aufgestellt werden könnte, dass ein weiterer Online-Perzeptionstest nicht nur mit Wörtern, sondern mit ganzen Sätzen arbeiten könnte und die Testteilnehmer dadurch nicht nur anhand der einzelnen Laute, sondern auch anhand der Intonation eines gesamten Satzes Rückschlüsse auf die Herkunft eines Sprechers ziehen könnten. Diese Methode könnte einerseits Aufschluss darüber geben, ob die Länderzuordnung in einem solchen Fall tatsächlich besser und präziser funktionieren würde und andererseits eventuell auch die Höhe des Frustrationsgrades der Testteilnehmer durch die reduzierte Schwierigkeit der Aufgabe senken und dazu führen, dass eine höhere Anzahl an Sprachaufnahmen bearbeitet werden würde und weniger Testteilnehmer vorzeitig den Test abbrechen würden.
Nachdem Kritik an der Methode geübt und Vorschläge gegeben wurden, um zukünftige Studien, die sich mit L1 interferierten lautlichen Merkmalen beim Fremdsprachenerwerb von Lernern beschäftigen, noch besser zu konzipieren, soll nun ein Ausblick auf weitere Forschungsmöglichkeiten im Bereich des Fremdsprachenerwerbs und im Bereich der Phonologie und Phonetik gegeben werden.
Zunächst sollte erwähnt werden, dass eine qualitative Analyse aller aufgenommenen Sprachaufnahmen der Probanden aus Deutschland, Österreich und der Schweiz sicherlich ebenfalls sehr interessant gewesen wäre, jedoch in Hinblick auf den angestrebten Umfang dieser Arbeit, Entscheidungen hinsichtlich der Art der durchgeführten Analyse und Auswertung der erhobenen Daten getroffen werden mussten und sich in diesem Sinne für eine quantitative Analyse mit einer kurzen Ergänzung durch eine qualitative Analyse, die auf einer strengen Selektion beruht hat, entschieden wurde.
Eine weitere Möglichkeit, die mit Blick auf Analysen von L2 Akzenten deutscher Italienischlerner interessante Ergebnisse liefern könnte, wäre die Aufnahme von Italienischlernern, die erst ein Sprachniveau von A1 oder A2 besitzen. Die in dieser Arbeit analysierten Sprachaufnahmen stammen zum Großteil von Sprechern, die bereits ein Italienischniveau von B2 bis C2 aufweisen und demzufolge schon einige Kompetenzen in Hinblick auf die italienische Aussprache erworben haben. In der detaillierten Analyse der Sprachaufnahmen ist aber deutlich geworden, dass beispielsweise Proband 0018, der ein Niveau von B1 besitzt und erst seit eineinhalb Jahren Italienisch lernt, offenkundig eine höhere Anzahl an Markierungen bei allen untersuchten Wörtern erhalten hat, als Sprecher, die seit längerer Zeit Italienisch lernen und ein höheres Sprachniveau vorweisen können. Aus diesem Grund wäre es interessant, einen Vergleich zwischen Lernanfängern und fortgeschrittenen Fremdsprachenlernern aufzustellen. Sowohl in Hinblick auf die Anzahl als auch auf die Auswahl der markierten Grapheme und Graphempaare könnten interessante Ergebnisse erwartet werden und zudem wäre es spannend zu sehen, ob Italiener lautliche Differenzen, die die deutschsprachigen Probanden in der italienischen Sprache aufzeigen würden, klarer den jeweiligen Ländern zuordnen könnten. Mit Blick auf die Erweiterung des Probandenprofils könnten auch Personen fortgeschrittenen Alters, die sich beispielsweise zwischen 40 und 70 Jahren befinden, in die Analyse integriert werden, um Rückschlüsse auf lautliche Interferenzen bei jungen und alten Lernern zu geben und wiederum zu ermitteln, ob bei der Anzahl und Auswahl der Grapheme sowie Graphempaare und zudem bei der Länderzuordnung Parallelen zu erkennen sind. Selbstverständlich könnten aber auch Überlegungen in Hinblick auf die Erweiterung der untersuchten Phoneme angestellt werden. Wie im Kapitel 2.4. Lautsystem der italienischen Sprache bereits angedeutet wurde, könnten beispielsweise auch bei den Frikativen sowie Affrikaten interessante lautliche Interferenzen bei deutschsprachigen Italienischlernern vorkommen.
Die Betrachtung weiterer Bundesländer und Kantone in Deutschland, Österreich und der Schweiz wäre in Hinblick auf weitere Unterschiede der Aussprache deutscher Lerner mit Sicherheit ebenfalls sehr interessant, da beispielsweise große Unterschiede in Hinblick auf die Realisierung von /e/ und /ɛ/ zwischen norddeutschen und süddeutschen Sprechern bestehen und zum Beispiel auch in den unterschiedlichen Gebieten der Schweiz verschiedene Realisationen des r-Lautes, die von /r/ über /ɹ/ bis zu /ʀ/ reichen, vorgefunden werden können (vgl. Schrambke 2010, 56-59). Deutschland, Österreich und die Schweiz zeigen außerdem eine hohe Anzahl an Dialekten auf, die die deutschen L1 Sprecher beim Fremdsprachenerwerb beeinflussen könnten und wären deswegen ebenfalls interessant zu betrachten, sollte das Probandenprofil erweitert und ein stärkerer Fokus auf unterschiedliche dialektale Gebiete in Deutschland, Österreich und der Schweiz gelegt werden.
Alles in allem kann also gesagt werden, dass es noch zahlreiche Forschungsmöglichkeiten in Hinblick auf L1 interferierte lautliche Merkmale beim Italienischerwerb deutscher Lerner gibt und durch die empirische Studie die Tendenz dargelegt werden konnte, dass deutschsprachige Italienischlerner anhand lautlicher Merkmale im Italienischen nur schwierig voneinander differenziert werden können, Interferenzen vor allem bei den Lauten /o/ und /ɔ/, /e/ und /ɛ/ sowie /r/ und /t/ vorgefunden werden können und der L2 Akzent der deutschsprachigen Sprecher zwar selbst bei einem Niveau von C1 oder C2 nie zu 100% vermieden werden konnte, einige Sprecher aber überdurchschnittlich oft nach Italien verortet wurden und somit oftmals keine lautlichen Differenzen bei ihnen hinsichtlich der italienischen Sprache vorgefunden werden konnten und die Tendenz besteht, dass sie ihren L2 Akzent komplett ablegen könnten. Für den Fremdsprachenerwerb an sich würde dies bedeuten, dass ein erhöhter Fokus auf die oben als am häufigsten identifizierten lautlichen Merkmale, bei denen Differenzen festgestellt werden konnten, gelegt werden sollte und die regelmäßige praktische Anwendung der Sprache, die vor allem im Zuge von Auslandsaufenthalten gelehrt wird, im Vordergrund stehen sollte, sofern lautliche Interferenzen der L1 vermieden werden möchten.
6. Tabellenverzeichnis
Tabelle 1: Konsonanten im Deutschen nach Pittner (2013, 22) (Kap. 2.3.2., Absatz 16)
Tabelle 2: Konsonanten im Italienischen (vgl. Michel 2016, 84) (Kap. 2.4.2., Absatz 25)
Tabelle 3: Mögliche Graphemauswahl im Online-Perzeptionstest (Kap. 4.3.1., Absatz 54)
Tabelle 4: Anzahl aller markierten Grapheme und Graphempaare (Kap. 4.3.1., Absatz 56)
Tabelle 5: Verortung der deutschsprachigen Italienischlerner (Kap. 4.3.2., Absatz 66)
7. Abbildungsverzeichnis
Abb. 1: Die Vokale im Deutschen nach Becker (2012, 11) (Kap. 2.3.1., Absatz 13)
Abb. 2: Vocali toniche dell’italiano nach Calamai (2008, 37) (Kap. 2.4.1., Absatz 21)
Abb. 3: Testseite des Online-Perzeptionstests (Kap. 4.2.1., Absatz 45)
Abb. 4: Verteilung der markierten Grapheme und Graphempaare nach Ländern (Kap. 4.3.1., Absatz 58)
Abb. 5: Verteilung der markierten Grapheme und Graphempaare bei Sprechern aus Deutschland (Kap. 4.3.1., Absatz 59)
Abb. 6: Verteilung der markierten Grapheme und Graphempaare bei Sprechern aus Österreich (Kap. 4.3.1., Absatz 60)
Abb. 7: Verteilung der markierten Grapheme und Graphempaare bei Sprechern aus der Schweiz (Kap. 4.3.1., Absatz 61)
Abb. 8: Übersicht über die korrekte und inkorrekte Zuordnung der Länder durch die Testteilnehmer (Kap. 4.3.2., Absatz 65)
Abb. 9: Anzahl der Sprachaufnahmen nach Sprechern mit Länderzuordnung Italien (Kap. 4.3.2., Absatz 69)
Abb. 10: Verteilung der markierten Grapheme <e> und <è> nach Sprechern (Kap. 4.4.1., Absatz 73)
Abb. 11: Anzahl der Markierungen von <e> und <è> nach Wörtern und Sprechern (Kap. 4.4.1., Absatz 74)
Abb. 12: Oszillogramm, Sonogramm und Transkription der Sprachaufnahme 0005_pane (Kap. 4.4.1., Absatz 79)
Abb. 13: Oszillogramm, Sonogramm und Transkription der Sprachaufnahme 0006_penna (Kap. 4.4.1., Absatz 87)
Abb. 14: Oszillogramm, Sonogramm und Transkription der Sprachaufnahme 0012_cioè (Kap. 4.4.1., Absatz 101)
Abb. 15: Verteilung des markierten Graphems <o> nach Sprechern (Kap. 4.4.2., Absatz 104)
Abb. 16: Anzahl der Markierungen von <o> nach Wörtern und Sprechern (Kap. 4.4.2., Absatz 105)
Abb. 17: Oszillogramm, Sonogramm und Transkription der Sprachaufnahme 0001_terremoto (Kap. 4.4.2., Absatz 110)
Abb. 18: Oszillogramm, Sonogramm und Transkription der Sprachaufnahme 0001_cooperazione (Kap. 4.4.2., Absatz 114)
Abb. 19: Oszillogramm, Sonogramm und Transkription der Sprachaufnahme 0013_ruolo (Kap. 4.4.2., Absatz 118)
Abb. 20: Verteilung der markierten Grapheme <r> und <rr> nach Sprechern (Kap. 4.4.3., Absatz 121)
Abb. 21: Anzahl der Markierungen von <r> und <rr> nach Wörtern und Sprechern (Kap. 4.4.3., Absatz 122)
Abb. 22: Oszillogramm, Sonogramm und Transkription der Sprachaufnahme 0001_ruolo (Kap. 4.4.3., Absatz 128)
Abb. 23: Oszillogramm, Sonogramm und Transkription der Sprachaufnahme 0004_terra (Kap. 4.4.3., Absatz 132)
Abb. 24: Oszillogramm, Sonogramm und Transkription der Sprachaufnahme 0013_parchi (Kap. 4.4.3., Absatz 136)
Abb. 25: Oszillogramm, Sonogramm und Transkription der Sprachaufnahme 0018_terremoto (Kap. 4.4.3., Absatz 140)
Abb. 26: Verteilung des markierten Graphems <t> nach Sprechern (Kap. 4.4.4., Absatz 143)
Abb. 27: Anzahl der Markierungen von <t> nach Wörtern und Sprechern (Kap. 4.4.4., Absatz 144)
Abb. 28: Oszillogramm, Sonogramm und Transkription der Sprachaufnahme 0005_tè (Kap. 4.4.4., Absatz 149)
Abb. 29: Oszillogramm, Sonogramm und Transkription der Sprachaufnahme 0006_terra (Kap. 4.4.4., Absatz 153)
Abb. 30: Oszillogramm, Sonogramm und Transkription der Sprachaufnahme 0014_terremoto (Kap. 4.4.4., Absatz 157)
Abb. 31: Transkriptionen der Sprachaufnahmen (Anhang 6, Absatz 660)
8. Anhang
Alle Anhänge sind digital in der Online-Version dieser Masterarbeit hinterlegt und können über die Webseite DH-Lehre eingesehen werden. Der ausgedruckten Version dieser Arbeit sind die Sprachaufnahmen in Form einer CD beigelegt.
8.1. Anhang 1: Fragebogen ‚Persönliche Daten‘
Fragebogen ‚Persönliche Daten‘
Tabelle ‚Persönliche Daten‘ aller Probanden
8.2. Anhang 2: Vorlage Einverständniserklärung der Probanden
Vorlage Einverständniserklärung
8.3. Anhang 3: Wortliste und Trägersätze
Wortliste
|
Laut |
Beispiel |
Anzahl |
|
[ɛ] |
terra, lento, cioè, tè |
4 |
|
[e] |
pane, penna, eppure, terremoto, cooperazione |
8 |
|
[ɔ] |
terremoto, ruolo, |
2 |
|
[o] |
risposta, lento, terremoto, ruolo, cooperazione, cioè |
8 |
|
[t] |
terra, lento, terremoto, risposta, tè |
6 |
|
[p] |
pane, eppure, penna, risposta, cooperazione, parchi |
6 |
|
[r] |
risposta, terra, ruolo, eppure, terremoto, parchi |
6 |
Trägersätze
- Dobbiamo salvare la terra.
- Una forte scossa di terremoto è stata registrata questa mattina.
- Dammi una risposta.
- Il pane appena sfornato è uno dei semplici piaceri della vita.
- Scrivere a un amico di penna può essere un’esperienza profondamente stimolante e appagante.
- Muore sola e povera eppure era milionaria.
- Daimler e BMW si alleano per una cooperazione strategica a lungo termine.
- I genitori hanno un ruolo estremamente importante nell’educare i figli in tenera età.
- Il treno più lento d’Italia è l’Intercity.
- Abito a Monaco, cioè in Baviera.
- Una tazza di tè, per favore.
- I parchi nazionali d’Italia sono molto belli.
8.4. Anhang 4: Perzeptionstest
Datenbank (DHVLab)
8.5. Anhang 5: Sprachaufnahmen
Sprecher 0001
0001_terra
0001_terremoto
0001_risposta
0001_pane
0001_penna
0001_eppure
0001_cooperazione
0001_ruolo
0001_lento
0001_cioè
0001_tè
0001_parchi
Sprecher 0002
0002_terra
0002_terremoto
0002_risposta
0002_pane
0002_penna
0002_eppure
0002_cooperazione
0002_ruolo
0002_lento
0002_cioè
0002_tè
0002_parchi
Sprecher 0003
0003_terra
0003_terremoto
0003_risposta
0003_pane
0003_penna
0003_eppure
0003_cooperazione
0003_ruolo
0003_lento
0003_cioè
0003_tè
0003_parchi
Sprecher 0004
0004_terra
0004_terremoto
0004_risposta
0004_pane
0004_penna
0004_eppure
0004_cooperazione
0004_ruolo
0004_lento
0004_cioè
0004_tè
0004_parchi
Sprecher 0005
0005_terra
0005_terremoto
0005_risposta
0005_pane
0005_penna
0005_eppure
0005_cooperazione
0005_ruolo
0005_lento
0005_cioè
0005_tè
0005_parchi
Sprecher 0006
0006_terra
0006_terremoto
0006_risposta
0006_pane
0006_penna
0006_eppure
0006_cooperazione
0006_ruolo
0006_lento
0006_cioè
0006_tè
0006_parchi
Sprecher 0007
0007_terra
0007_terremoto
0007_risposta
0007_pane
0007_penna
0007_eppure
0007_cooperazione
0007_ruolo
0007_lento
0007_cioè
0007_tè
0007_parchi
Sprecher 0008
0008_terra
0008_terremoto
0008_risposta
0008_pane
0008_penna
0008_eppure
0008_cooperazione
0008_ruolo
0008_lento
0008_cioè
0008_tè
0008_parchi
Sprecher 0009
0009_terra
0009_terremoto
0009_risposta
0009_pane
0009_penna
0009_eppure
0009_cooperazione
0009_ruolo
0009_lento
0009_cioè
0009_tè
0009_parchi
Sprecher 0010
0010_terra
0010_terremoto
0010_risposta
0010_pane
0010_penna
0010_eppure
0010_cooperazione
0010_ruolo
0010_lento
0010_cioè
0010_tè
0010_parchi
Sprecher 0011
0011_terra
0011_terremoto
0011_risposta
0011_pane
0011_penna
0011_eppure
0011_cooperazione
0011_ruolo
0011_lento
0011_cioè
0011_tè
0011_parchi
Sprecher 0012
0012_terra
0012_terremoto
0012_risposta
0012_pane
0012_penna
0012_eppure
0012_cooperazione
0012_ruolo
0012_lento
0012_cioè
0012_tè
0012_parchi
Sprecher 0013
0013_terra
0013_terremoto
0013_risposta
0013_pane
0013_penna
0013_eppure
0013_cooperazione
0013_ruolo
0013_lento
0013_cioè
0013_tè
0013_parchi
Sprecher 0014
0014_terra
0014_terremoto
0014_risposta
0014_pane
0014_penna
0014_eppure
0014_cooperazione
0014_ruolo
0014_lento
0014_cioè
0014_tè
0014_parchi
Sprecher 0015
0015_terra
0015_terremoto
0015_risposta
0015_pane
0015_penna
0015_eppure
0015_cooperazione
0015_ruolo
0015_lento
0015_cioè
0015_tè
0015_parchi
Sprecher 0016
0016_terra
0016_terremoto
0016_risposta
0016_pane
0016_penna
0016_eppure
0016_cooperazione
0016_ruolo
0016_lento
0016_cioè
0016_tè
0016_parchi
Sprecher 0017
0017_terra
0017_terremoto
0017_risposta
0017_pane
0017_penna
0017_eppure
0017_cooperazione
0017_ruolo
0017_lento
0017_cioè
0017_tè
0017_parchi
Sprecher 0018
0018_terra
0018_terremoto
0018_risposta
0018_pane
0018_penna
0018_eppure
0018_cooperazione
0018_ruolo
0018_lento
0018_cioè
0018_tè
0018_parchi
8.6. Anhang 6: Transkriptionen der Sprachaufnahmen
Tabellarische Darstellung der transkribierten Sprachaufnahmen (Excel-Tabelle)
Transkriptionen der Sprachaufnahmen
8.7. Anhang 7: Eidesstattliche Erklärung
Die eidesstattliche Erklärung ist der ausgedruckten Version dieser Masterarbeit beigefügt.
Bibliographie
- Amenta/Castiglione 2010 = Amenta, Luisa / Castiglione, Marina (2010): Nuovi criteri per la definizione di italiano regionale: tra (auto)rappresentazioni e realizzazioni effettive, in: Krefeld, Thomas / Pustka, Elissa (Hrsgg.), Perzeptive Varietätenlinguistik, Frankfurt am Main, Lang, 181-208.
- Ammon 1995 = Ammon, Ulrich (1995): Die deutsche Sprache in Deutschland, Österreich und der Schweiz. Das Problem der nationalen Varietäten, Berlin, De Gruyter.
- Ammon 1996 = Ammon, Ulrich (1996): Deutsch als plurinationale Sprache: Unterschiedliche Aussprachestandards für Deutschland, Österreich und die deutschsprachige Schweiz, in: Krech, Eva-Maria / Stock, Eberhard (Hrsgg.), Hallesche Schriften zur Sprechwissenschaft und Phonetik, vol. 1, Hanau/Halle, Dausien, 194-203.
- Ammon 2017 = Ammon, Ulrich (2017): Grundbegriffe für plurizentrische Sprachen und ihre Operationalisierung - mit Bezug auf die deutsche Sprache und das "Variantenwörterbuch des Deutschen", in: Eke, Norbert Otto / Friedrich, Udo / Geulen, Eva / Schausten, Monika / Solms, Hans-Joachim (Hrsgg.), Zeitschrift für deutsche Philologie, vol. 136, Berlin, Schmidt, 5-22.
- Becker 2012 = Becker, Thomas (2012): Das Vokalsystem der deutschen Standardsprache, Bamberg, Opus (Link).
- Bhela 1999 = Bhela, Baljit (1999): Native language interference in learning a second language: Exploratory case studies of native language interference with target language usage, in: Reynolds, Reaburn / Keeves, John (Hrsgg.), International Education Journal, vol. 1, 1, North Haven, Shannon Research Press, 22-31.
- Bickel/Hofer 2013 = Bickel, Hans / Hofer, Lorenz (2013): Gutes und angemessenes Standarddeutsch in der Schweiz, in: Schneider-Wiejowski, Karina / Kellermeier-Rehbein, Birte / Haselhuber, Jakob (Hrsgg.), Vielfalt, Variation und Stellung der deutschen Sprache, Berlin/Boston, De Gruyter, 79-100.
- Brito u.a. 2015 = Brito, Natalie H. / Sebastián-Gallés, Núria / Barr, Rachel (2015): Differences in language exposure and its effects on memory flexibility in monolingual, bilingual, and trilingual infants, in: Bilingualism: Language and Cognition, vol. 18, 4, Cambridge, Cambridge University Press, 670-682.
- Bürkle 1993 = Bürkle, Michael (1993): Zur Aussprache des österreichischen Standards. Österreich-Typisches in der Nebensilbe, in: Muhr, Rudolf (Hrsg.), Internationale Arbeiten zum österreichischen Deutsch und seinen nachbarsprachlichen Bezügen, Wien, Hölder-Pichler-Tempsky, 53-66.
- Bundesministerium für Bildung, Wissenschaft und Forschung 2018 = Bundesministerium für Bildung, Wissenschaft und Forschung (2018): Lehrpläne der Allgemein bildenden Schulen (Link).
- Calamai 2008 = Calamai, Silvia (2008): L'italiano: suoni e forme, Roma, Carocci.
- Canepari 2007 = Canepari, Luciano (2007): Pronunce straniere dell'italiano "ProSIt". Applicazioni geo-socio-linguistiche del Metodo della Fonetica e tonetica naturali per successive applicazioni fono-didattiche, München, LINCOM.
- Canepari 2014 = Canepari, Luciano (2014): German Pronunciation & Accents. Geo-social Applications of the Natural Phonetics & Tonetics Method, München, LINCOM.
- Clyne 1989 = Clyne, Michael (1989): Pluricentricity: National Variety, in: Ammon, Ulrich (Hrsg.), Status and Function of Languages and Language Varieties, Berlin/New York, De Gruyter, 357-371.
- Costamagna u.a. 2010 = Costamagna, Lidia / Spinelli, Barbara / Parizzi, Francesca (2010): I livelli di riferimento e l'insegnamento della fonetica e della fonologia, in: Profilo della lingua italiana. Livelli di riferimento del QCER A1, A2, B1, B2, Mailand, La Nuova Italia, 75-86.
- D'Agostino/Pinello 2010 = D'Agostino, Mari / Pinello, Vincenzo (2010): La Sicilia linguistica tra frammentazione e continuità, in: Krefeld, Thomas / Pustka, Elissa (Hrsgg.), Perzeptive Varietätenlinguistik, Frankfurt am Main, Lang, 313-336.
- Diadori 2011 = Diadori, Pierangela (2011): Introduzione, in: Diadori, Pierangela (Hrsg.), Insegnare italiano a stranieri, Mailand, Le Monnier, XII-XV.
- Gärtig/Rocco 2018 = Gärtig, Anne-Kathrin / Rocco, Goranka (2018): Soziophonetisches Projekt Salzburg-Triest (SoPhoProST). Untersuchungen zur L1- und L2-Phonetik und Phonologie junger italienischer Deutschlerner, in: Vogt, Barbara (Hrsg.), Gesprochene (Fremd-)Sprache als Forschungs- und Lehrgegenstand, Triest, EUT, 109-137 (Link).
- Graefen/Liedke 2012 = Graefen, Gabriele / Liedke, Martina (22012): Germanistische Sprachwissenschaft. Deutsch als Erst-, Zweit- oder Fremdsprache, Tübingen/Basel, Francke [https://opac.ub.uni-muenchen.de/TouchPoint/perma.do?q=+0%3D%224650635%22+IN+%5B2%5D&v=sunrise&l=de].
- Grassegger 1988 = Grassegger, Hans (1988): Signalphonetische Untersuchungen zur Differenzierung italienischer Plosive durch österreichische Sprecher, in: Wodarz, Hans Walter (Hrsg.), Forum phoneticum, vol. 40, Hamburg, Buske.
- Hengartner/Niederhauser 1993 = Hengartner, Thomas / Niederhauser, Jürg (1993): Phonetik, Phonologie und phonetische Transkription, Aarau/Frankfurt am Main/Salzburg, Sauerländer.
- Hollmach 2007 = Hollmach, Uwe (2007): Untersuchungen zur Kodifizierung der Standardaussprache in Deutschland, Frankfurt am Main, Lang.
- Iivonen 1996 = Iivonen, Antti (1996): Unterschiede des Vokalismus und der Intonation in der ostmitteldeutschen und wienerdeutschen Standardaussprache, in: Krech, Eva-Maria / Stock, Eberhard (Hrsgg.), Hallesche Schriften zur Sprechwissenschaft und Phonetik, vol. 1, Hanau/Halle, Dausien, 225-240.
- Ille/Vetter 2010 = Ille, Karl / Vetter, Eva (2010): Wahrnehmungsaspekte im deutsch-italienischen Varietätenkontakt in Wien, in: Krefeld, Thomas / Pustka, Elissa (Hrsgg.), Perzeptive Varietätenlinguistik, Frankfurt am Main, Lang, 233-261.
- Kellermeier-Rehbein 2014 = Kellermeier-Rehbein, Birte (2014): Plurizentrik. Einführung in die nationalen Varietäten des Deutschen, Berlin, Schmidt.
- Korhonen 2013 = Korhonen, Jarmo (2013): Die süddeutsche und österreichische Aussprache mit Nord- und Südstandard des Deutschen in deutsch-finnischen Allgemeinwörterbüchern, in: Schneider-Wiejowski, Karina / Kellermeier-Rehbein, Birte / Haselhuber, Jakob (Hrsgg.), Vielfalt, Variation und Stellung der deutschen Sprache, Berlin/Boston, De Gruyter, 101-118.
- Krefeld/Pustka 2010 = Krefeld, Thomas / Pustka, Elissa (Hrsgg.) (2010): Perzeptive Varietätenlinguistik, vol. Spazi comunicativi - Kommunikative Räume, 8, Frankfurt , Lang.
- Krefeld/Pustka 2014 = Krefeld, Thomas / Pustka, Elissa (Hrsgg.) (2014): Perzeptive Linguistik: Phonetik, Semantik, Varietäten, in: Zeitschrift für Dialektologie und Linguistik Beihefte, vol. 157, Stuttgart, Steiner.
- Krings 2016 = Krings, Hans P. (2016): Fremdsprachenlernen mit System. Das große Handbuch der besten Strategien für Anfänger, Fortgeschrittene und Profis, Hamburg, Buske.
- Ladefoged 2011 = Ladefoged, Peter (92011): Phonetic Data Analysis. An Introduction to Fieldwork and Instrumental Techniques, Malden/Oxford/Carlton, Blackwell.
- Luise 2006 = Luise, Maria Cecilia (2006): Italiano come lingua seconda. Elementi di didattica, Turin, UTET Università.
- Maturi 2009 = Maturi, Pietro (22009): I suoni delle lingue, i suoni dell'italiano. Introduzione alla fonetica, Bologna, il Mulino.
- Michel 2006 = Michel, Andreas (2006): Die Didaktik des Französischen, Spanischen und Italienischen in Deutschland einst und heute, Hamburg, Dr. Kovač.
- Michel 2016 = Michel, Andreas (22016): Einführung in die italienische Sprachwissenschaft, Berlin/Boston, De Gruyter.
- Muhr 1993 = Muhr, Rudolf (1993): Österreichisch - Bundesdeutsch - Schweizerisch. Zur Didaktik des Deutschen als plurizentrische Sprache, in: Muhr, Rudolf (Hrsg.), Internationale Arbeiten zum österreichischen Deutsch und seinen nachbarsprachlichen Bezügen, Wien, Hölder-Pichler-Tempsky, 108-123.
- Muhr 2017 = Muhr, Rudolf (2017): Das Österreichische Deutsch, in: Eke, Norbert Otto / Friedrich, Udo / Geulen, Eva / Schausten, Monika / Solms, Hans-Joachim (Hrsgg.), Zeitschrift für deutsche Philologie, vol. 136, Berlin, Schmidt, 23-41.
- Noak 2010 = Noak, Christina (2010): Phonologie, Heidelberg, Winter.
- Pittner 2013 = Pittner, Karin (2013): Einführung in die germanistische Linguistik, Darmstadt, WBG.
- Pustka/Meisenburg 2017 = Pustka, Elissa / Meisenburg, Trudel (2017): Les germanophones, in: Detey, Sylvain / Racine, Isabelle / Kawaguchi, Yuji / Eychenne, Julien (Hrsgg.), La prononciation du français dans le monde: du natif à l’apprenant, Paris, CLE International, 130-136 (Link).
- Rash 1998 = Rash, Felicity (1998): The German Language in Switzerland. Multilinguism, Diglossia and Variation, Bern, Lang.
- Reumuth/Winkelmann 2013 = Reumuth, Wolfgang / Winkelmann, Otto (2013): Praktische Grammatik der portugiesischen Sprache, Wilhelmsfeld, Egert.
- Rues u.a. 2009 = Rues, Beate / Redecker, Beate / Wallraff, Uta / Koch, Evelyn / Simpson, Adrian P. (22009): Phonetische Transkription des Deutschen. Ein Arbeitsbuch, Tübingen, Narr.
- Rues u.a. 2014 = Rues, Beate / Redecker, Beate / Koch, Evelyn / Wallraff, Uta / Simpson, Adrian P. (32014): Phonetische Transkription des Deutschen. Ein Arbeitsbuch, Tübingen, Narr.
- Schmidlin 2011 = Schmidlin, Regula (2011): Die Vielfalt des Deutschen: Standard und Variation. Gebrauch, Einschätzung und Kodifizierung einer plurizentrischen Sprache, Berlin/Boston, De Gruyter.
- Schrambke 2010 = Schrambke, Renate (2010): Realisierung von /r/ im alemannischen Sprachraum, in: van Nahl, Astrid (Hrsg.), Dialectologia et Geolinguistica. Journal of the International Society for Dialectology and Geolinguistics, vol. 18, Berlin/Boston, De Gruyter, 52-72.
- Schweizerische Konferenz der kantonalen Erziehungsdirektoren 2018 = Schweizerische Konferenz der kantonalen Erziehungsdirektoren (2018): Fremdsprachen: Zweisprachiger / immersiver Unterricht (Link).
- Siebs 1969 = Siebs, Theodor (191969): Deutsche Aussprache. Reine und gemäßigte Hochlautung mit Aussprachewörterbuch, Berlin, De Gruyter.
- Soares De Sousa 2016 = Soares De Sousa, Diana (2016): The Effect of Bilingualism on Working Memory in Monolingual and Bilingual Children in South Africa, in: Wilson, Carroll E. (Hrsg.), Bilingualism. Cultural Influences, Global Perspectives and Advantages/Disadvantages, New York, Nova, 141-178.
- Solari 1997 = Solari, Roberto (1997): Italiano e tedesco a confronto: foni e fonemi, in: Bosco Coletsos, Sandra (Hrsg.), Italiano e tedesco: un confronto. Appunti morfo-sintattici, lessicali e fonetici, Turin, dell'Orso, 221-227.
- Soriani 2010 = Soriani, Guido (2010): Percezioni e comportamenti linguistici. Un caso siciliano, in: Krefeld, Thomas / Pustka, Elissa (Hrsgg.), Perzeptive Varietätenlinguistik, Frankfurt am Main, Lang, 361-397.
- Ternes 2012 = Ternes, Elmar (32012): Einführung in die Phonologie, Darmstadt, WBG.
- Trubetzkoy 1962 = Trubetzkoy, Nikolaj Sergeevič (31962): Grundzüge der Phonologie, Göttingen, Vandenhoeck & Ruprecht.
- Ulbrich 2002 = Ulbrich, Christiane (2002): A Comparative Study of Intonation in Three Standard Varieties of German, in: Bel, Bernard / Marlien, Isabelle (Hrsgg.), Proceedings of the Speech Prosody 2002 Conference, 11-13 April 2002, Aix-en-Provence, Laboratoire Parole et Langage, 671-674.
- Vogel/Vogel 1975 = Vogel, Klaus / Vogel, Sigrid (1975): Lernpsychologie und Fremdsprachenerwerb, Tübingen, Niemeyer.