1. Computergestützte literarische Gattungsstilistik (CLiGS)
Mit der Bereitstellung von Texten, die den FAIR-Prinzipen entsprechen, eröffnen sich neue Horizonte der Textanalyse. Im Folgenden sollen die Erfahrungen der Nachwuchsgruppe CLiGS (Link) bei der Erstellung und Veröffentlichung des Korpus textbox (https://github.com/cligs/textbox) (https://journals.openedition.org/jtei/2085) reflektiert und illustriert werden; Grundlage der Darstellung ist Schöch u.a.. Die textbox ist einerseits im großen Repositorium GitHub abgelegt:
"In addition, because GitHub as a commercial entity does not provide any guarantee for the long-term availability of the data, stable versions of the text collections are designated as releases (using semantic versioning) and archived on Zenodo.org, a long-term data and publications archiving service for researchers across Europe managed by OpenAire and supported by CERN (see Nielsen 2013). The textbox repository on Github is connected to Zenodo.org so that any new release is automatically archived and published on Zenodo.org. This includes the requirement that each release receives a DOI (Digital Object Identifier)" (Schöch u.a., Link, Abs. 38)
Dieses Korpus literarischer Texte ist zwar nicht im statischen Sinn repräsentativ für die erfassten romanischen Literaturen, aber durchaus hinreichend für quantitative Arbeit mit diesen Texten:
"The textbox currently contains novels, novellas, and short stories published between 1830 and 1940 in France, Italy, Spain, Portugal, and Spanish-America, as well as plays published between 1640 and 1680 in France, with a total of 388 texts or about 13.6 million words." (Schöch u.a., Link, Abs. 5)
Das Korpus ist ausdrücklich in der Perspektive möglichst breiter Nachnutzung (FAIR-Kriterium R) angelegt worden:
"[...] we suggest several ways in which the text collections can be used for research in literary studies. We aim to document some of the work of the CLiGS group, to showcase the unique TEI XML-based collections of French, Spanish, Spanish-American, and Portuguese novels and French drama we make available, and to encourage reuse of these text collections by others. We argue that agreement on common formats and procedures for text preparation, encoding, and publication fosters the accessibility, analysis, and reuse potential of literary text collections." (Schöch u.a., Link, Abstract)
Hier ein Überblick über die italienische Komponente:
"The textbox contains two collections of Italian texts: the Collection of Italian Short Stories and Novellas (1880s–1920s) and the Collection of Italian Novels. The collection of short stories contains 90 texts written by three authors. It amounts to approximately 300,000 words and can, for example, be used to test authorship attribution. The corpus of Italian novels includes 21 texts by 15 authors, written between 1850 and 1915. It contains about 2.3 million words." (Schöch u.a., Link, Abs. 11)
Jeder Text wird in unterschiedlichen Ausgabeformaten angeboten:
Exportformate der CLiGS Textbox (Quelle)
Der Anfang der Erzählung Le figurine (1918) von Afolfo Albertazzi soll im Folgenden einen Eindruck dieser Formate geben.
- tei
Bei der Annotation der Texte werden zwei Arten von Metadaten unterschieden , die als "descriptive and administrative" bezeichnet (Link, Abs 27) werden; mit den deskriptiven Tags wird der Text als ganzer kategorisiert; die administrativen Tags erlauben eine detaillierte Erschließung seiner sprachlichen Gestaltung. Die Auszeichnung (Annotation) des Gesamttextes folgt dem sogenannten TEI-Schema (der Text Encoding Initiative) im Format XML (Link), das am Anfang jeder Textdatei (im Header) grundlegende Metadaten und korpusspezifische Keywords identifiziert (Link). Nach dem Header folgt der eigentliche Text (<text><body>...</body></text>), dessen Anfang sich folgendermaßen präsentiert:
| <text> | |
| <body> | |
| <div> | |
| <head>Le figurine.</head> | |
| <p>— Mulattiere!</p> | |
| <p>Al vicino, che gli chiedeva del suo servizio, rispose con l’impeto d’una coscienza | |
| aperta a tutti i doveri e a tutti i pericoli della carica. E per dimostrarne meglio | |
| la gravità, aggiunse:</p> | |
| <p>— Addetto al vettovagliamento!</p> | |
| <p>Anche la voce, forte, sonora, era espressione di vigoria.</p> | |
| <p>— Di dove venite?</p> | |
| <p>— Dal Trentino.</p> | |
| <p>— E siete in licenza?</p> | |
| <p>— Sì. Otto giorni di licenza straordinaria. Vado a casa a divertirmi.</p> |
- annotated
Mit diesem Ausdruck wird eine Version bezeichnet, in der die Textgliederung (Wort, Satz, Absatz u.a.) sowie jedes Einzelwort annotiert wird:
"Moreover, the collections of French, Spanish, Spanish-American, Italian, and Portuguese novels, novellas, and short stories are made available in a version combining basic structural markup (chapter and sentence divisions) with token-level linguistic annotation (including lemma, part-of-speech, morphology, and basic semantic annotation using FreeLing and WordNet)." (Schöch u.a., Link, Abs. 21)
Informationen über den eingesetzten Tagger FreeLing geben Padró/Stanislovsky 2012 (Link). Sehr gut ist die semantische Annotation auf der Grundlage von WordNet (Link), die auch durch den Tagger mitgeliefert wurde (vgl. DEFAULT); WordNet enthält ja im Unterschied zum darauf aufbauenden, mehrsprachigen BabelNet (Link) nur das englische Vokabular. Immerhin lässt sich die Granulierung des Taggers an der Analyse von una zeigen; diese Form wird dem Lemma uno zugeordnet:
<w cligs:form="una" lemma="uno" cligs:tag="AQ0FS00" cligs:wnsyn="02186338-a" cligs:wnlex="adj.all">una</w>
Etwas transparenter ist das Tagging des folgenden spanischen Beispiels aus Schöch u.a.:
pasaron dos días. ‘zwei Tage vergingen’
<w cligs:form="Pasaron" lemma="pasar" cligs:tag="VMIS3P0" cligs:ctag="VMI" pos="verb" type="main" cligs:mood="indicative" cligs:tense="past" cligs:person="3" cligs:num="plural" cligs:wnsyn="00339934-v" cligs:wnlex="verb.change">Pasaron</w> <w cligs:form="dos_días" lemma="TM_d:2" cligs:tag="Zu" cligs:ctag="Zu" pos="number" type="unit" cligs:wnsyn="xxx" cligs:wnlex="xxx">dos_días</w> <w cligs:form="." lemma="." cligs:tag="Fp" cligs:ctag="Fp" pos="punctuation" type="period" cligs:wnsyn="xxx" cligs:wnlex="xxx">.</w></s>Der Anfang der oben genannten ita. Beispielerzählung sieht folgendermaßen aus:
| <text> | |
| <body> | |
| <div xml:id="it0001_d1"><ab><s><w cligs:form="—" lemma="—" cligs:tag="Fz" cligs:wnsyn="xxx" cligs:wnlex="xxx">—</w><w cligs:form="Mulattiere" lemma="mulattiere" cligs:tag="NP00000" cligs:wnsyn="xxx" cligs:wnlex="xxx">Mulattiere</w><w cligs:form="!" lemma="!" cligs:tag="Fat" cligs:wnsyn="xxx" cligs:wnlex="xxx">!</w></s></ab><ab><s><w cligs:form="Al" lemma="al" cligs:tag="NCMS000" cligs:wnsyn="xxx" cligs:wnlex="xxx">Al</w><w cligs:form="vicino" lemma="vicino" cligs:tag="AQ0MS00" cligs:wnsyn="xxx" cligs:wnlex="xxx">vicino</w><w cligs:form="," lemma="," cligs:tag="Fc" cligs:wnsyn="xxx" cligs:wnlex="xxx">,</w><w cligs:form="che" lemma="che" cligs:tag="VMIP3S0" cligs:wnsyn="xxx" cligs:wnlex="xxx">che</w><w cligs:form="gli" lemma="gli" cligs:tag="RG" cligs:wnsyn="xxx" cligs:wnlex="xxx">gli</w><w cligs:form="chiedeva" lemma="chiedeva" cligs:tag="VMIP3S0" cligs:wnsyn="xxx" cligs:wnlex="xxx">chiedeva</w><w cligs:form="del" lemma="del" cligs:tag="NCMS000" cligs:wnsyn="xxx" cligs:wnlex="xxx">del</w><w cligs:form="suo" lemma="suar" cligs:tag="VMIP1S0" cligs:wnsyn="00067545-v" cligs:wnlex="verb.body">suo</w><w cligs:form="servizio" lemma="servizio" cligs:tag="AQ0MS00" cligs:wnsyn="xxx" cligs:wnlex="xxx">servizio</w><w cligs:form="," lemma="," cligs:tag="Fc" cligs:wnsyn="xxx" cligs:wnlex="xxx">,</w><w cligs:form="rispose" lemma="rispose" cligs:tag="NCFS000" cligs:wnsyn="xxx" cligs:wnlex="xxx">rispose</w><w cligs:form="con" lemma="con" cligs:tag="NCFS000" cligs:wnsyn="xxx" cligs:wnlex="xxx">con</w><w cligs:form="l" lemma="l" cligs:tag="NCMS000" cligs:wnsyn="13624190-n" cligs:wnlex="noun.quantity">l</w><w cligs:form="’" lemma="’" cligs:tag="Frc" cligs:wnsyn="xxx" cligs:wnlex="xxx">’</w><w cligs:form="impeto" lemma="impeto" cligs:tag="AQ0MS00" cligs:wnsyn="xxx" cligs:wnlex="xxx">impeto</w><w cligs:form="d" lemma="d" cligs:tag="NCMS000" cligs:wnsyn="06831498-n" cligs:wnlex="noun.communication">d</w><w cligs:form="’" lemma="’" cligs:tag="Frc" cligs:wnsyn="xxx" cligs:wnlex="xxx">’</w><w cligs:form="una" lemma="uno" cligs:tag="AQ0FS00" cligs:wnsyn="02186338-a" cligs:wnlex="adj.all">una</w><w cligs:form="coscienza" lemma="coscienza" cligs:tag="NCFS000" cligs:wnsyn="xxx" cligs:wnlex="xxx">coscienza</w><w cligs:form="aperta" lemma="apertar" cligs:tag="VMIP3S0" cligs:wnsyn="00304422-v" cligs:wnlex="verb.change">aperta</w><w cligs:form="a" lemma="o" cligs:tag="DA0FS0" cligs:wnsyn="xxx" cligs:wnlex="xxx">a</w><w cligs:form="tutti" lemma="tutti" cligs:tag="AQ0CN00" cligs:wnsyn="xxx" cligs:wnlex="xxx">tutti</w><w cligs:form="i" lemma="i" cligs:tag="NCMS000" cligs:wnsyn="06832033-n" cligs:wnlex="noun.communication">i</w><w cligs:form="doveri" lemma="doveri" cligs:tag="AQ0CN00" cligs:wnsyn="xxx" cligs:wnlex="xxx">doveri</w><w cligs:form="e" lemma="e" cligs:tag="CC" cligs:wnsyn="xxx" cligs:wnlex="xxx">e</w><w cligs:form="a" lemma="o" cligs:tag="DA0FS0" cligs:wnsyn="xxx" cligs:wnlex="xxx">a</w><w cligs:form="tutti" lemma="tutti" cligs:tag="AQ0CN00" cligs:wnsyn="xxx" cligs:wnlex="xxx">tutti</w><w cligs:form="i" lemma="ir" cligs:tag="VMN0000" cligs:wnsyn="01835496-v" cligs:wnlex="verb.motion">i</w><w cligs:form="pericoli" lemma="pericoli" cligs:tag="RG" cligs:wnsyn="xxx" cligs:wnlex="xxx">pericoli</w><w cligs:form="della" lemma="della" cligs:tag="NCFS000" cligs:wnsyn="xxx" cligs:wnlex="xxx">della</w><w cligs:form="carica" lemma="carica" cligs:tag="AQ0FS00" cligs:wnsyn="xxx" cligs:wnlex="xxx">carica</w><w cligs:form="." lemma="." cligs:tag="Fp" cligs:wnsyn="xxx" cligs:wnlex="xxx">.</w></s></ab><ab><s><w cligs:form="E" lemma="e" cligs:tag="CC" cligs:wnsyn="xxx" cligs:wnlex="xxx">E</w><w cligs:form="per" lemma="per" cligs:tag="SP" cligs:wnsyn="xxx" cligs:wnlex="xxx">per</w><w cligs:form="dimostrarne" lemma="dimostrarne" cligs:tag="NCFS000" cligs:wnsyn="xxx" cligs:wnlex="xxx">dimostrarne</w><w cligs:form="meglio" lemma="meglio" cligs:tag="NCMS000" cligs:wnsyn="xxx" cligs:wnlex="xxx">meglio</w><w cligs:form="la" lemma="o" cligs:tag="PP3FSA0" cligs:wnsyn="xxx" cligs:wnlex="xxx">la</w><w cligs:form="gravità" lemma="gravità" cligs:tag="VMIP3S0" cligs:wnsyn="xxx" cligs:wnlex="xxx">gravità</w><w cligs:form="," lemma="," cligs:tag="Fc" cligs:wnsyn="xxx" cligs:wnlex="xxx">,</w><w cligs:form="aggiunse" lemma="aggiunse" cligs:tag="AQ0CS00" cligs:wnsyn="xxx" cligs:wnlex="xxx">aggiunse</w><w cligs:form=":" lemma=":" cligs:tag="Fd" cligs:wnsyn="xxx" cligs:wnlex="xxx">:</w><w cligs:form="—" lemma="—" cligs:tag="Fz" cligs:wnsyn="xxx" cligs:wnlex="xxx">—</w><w cligs:form="Addetto" lemma="addetto" cligs:tag="NP00000" cligs:wnsyn="xxx" cligs:wnlex="xxx">Addetto</w><w cligs:form="al" lemma="al" cligs:tag="NCMS000" cligs:wnsyn="xxx" cligs:wnlex="xxx">al</w><w cligs:form="vettovagliamento" lemma="vettovagliamento" cligs:tag="NCMS000" cligs:wnsyn="xxx" cligs:wnlex="xxx">vettovagliamento</w><w cligs:form="!" lemma="!" cligs:tag="Fat" cligs:wnsyn="xxx" cligs:wnlex="xxx">!</w></s></ab><ab><s><w cligs:form="Anche" lemma="anche" cligs:tag="NP00000" cligs:wnsyn="xxx" cligs:wnlex="xxx">Anche</w><w cligs:form="la" lemma="o" cligs:tag="PP3FSA0" cligs:wnsyn="xxx" cligs:wnlex="xxx">la</w><w cligs:form="voce" lemma="voce" cligs:tag="VMIP3S0" cligs:wnsyn="xxx" cligs:wnlex="xxx">voce</w><w cligs:form="," lemma="," cligs:tag="Fc" cligs:wnsyn="xxx" cligs:wnlex="xxx">,</w><w cligs:form="forte" lemma="forte" cligs:tag="AQ0CS00" cligs:wnsyn="01190683-a" cligs:wnlex="adj.all">forte</w><w cligs:form="," lemma="," cligs:tag="Fc" cligs:wnsyn="xxx" cligs:wnlex="xxx">,</w><w cligs:form="sonora" lemma="sonoro" cligs:tag="AQ0FS00" cligs:wnsyn="01455221-a" cligs:wnlex="adj.all">sonora</w><w cligs:form="," lemma="," cligs:tag="Fc" cligs:wnsyn="xxx" cligs:wnlex="xxx">,</w><w cligs:form="era" lemma="ser" cligs:tag="VMII1S0" cligs:wnsyn="02604760-v" cligs:wnlex="verb.stative">era</w><w cligs:form="espressione" lemma="espressione" cligs:tag="NCMS000" cligs:wnsyn="xxx" cligs:wnlex="xxx">espressione</w><w cligs:form="di" lemma="di" cligs:tag="VMIS1S0" cligs:wnsyn="xxx" cligs:wnlex="xxx">di</w><w cligs:form="vigoria" lemma="vigoria" cligs:tag="NCFS000" cligs:wnsyn="xxx" cligs:wnlex="xxx">vigoria</w><w cligs:form="." lemma="." cligs:tag="Fp" cligs:wnsyn="xxx" cligs:wnlex="xxx">.</w> |
- txt_id
Diese Version liefert reinen Text, ohne jede Annotierung, in einer einzigen Codezeile (Link).
Die Annotation verwandelt einen Text in einen strukturierten Datenbestand, der ganz unterschiedliche Anwendungen gestattet, die im Folgenden angedeutet werden sollen.
1.1. Autorschaftsbstimmungen
Sehr klar tritt die gemeinsame Autorschaft (vgl. Schöch u.a., Link, Abs. 41) von Texten hervor, wenn man die die häufigsten 5000 Wörter bestimmt; geichzeitig zeigt sich in der Visualisierung durch Baumgraphen die relative Ähnlichkeit unterschiedlicher Autoren:
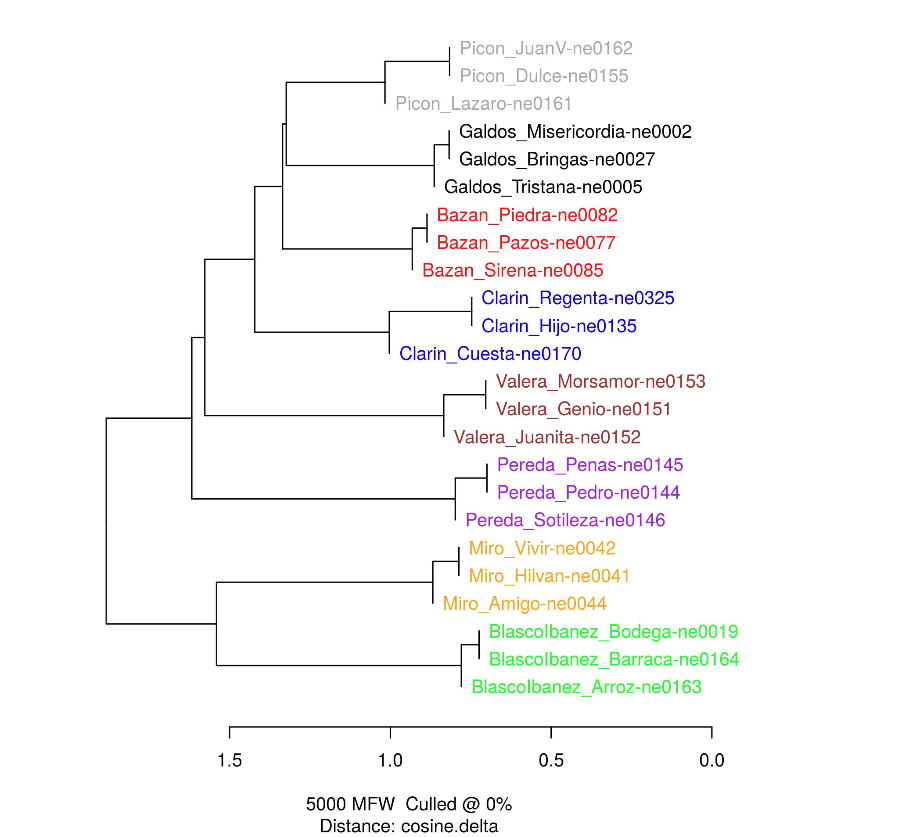
Figure 1. Results of using Cosine Delta on the corpus of Spanish novels (aus: Schöch u.a., Abs. 41)
1.2. Netzwerk der Personen
Da in Theaterstücken jeweils bei jeder Szene die auftretenden Personen explizit aufgezählt werden, ist es möglich sehr genau die Intensität ihrer (sprachlichen) Interaktion zu bemessen und in Gestalt von Netzwerken zu visualisieren. Die folgende Abbildung zeigt die Beziehungen des dramatischen Personals der Tragödie Britannicus (1669) von Jean Racine, wobei die Dicke der Verbindungslinien von der Menge der gewechselten Wörter in den Szenen abhängt, in denen die verbunden Personen gemeinsam auftreten:
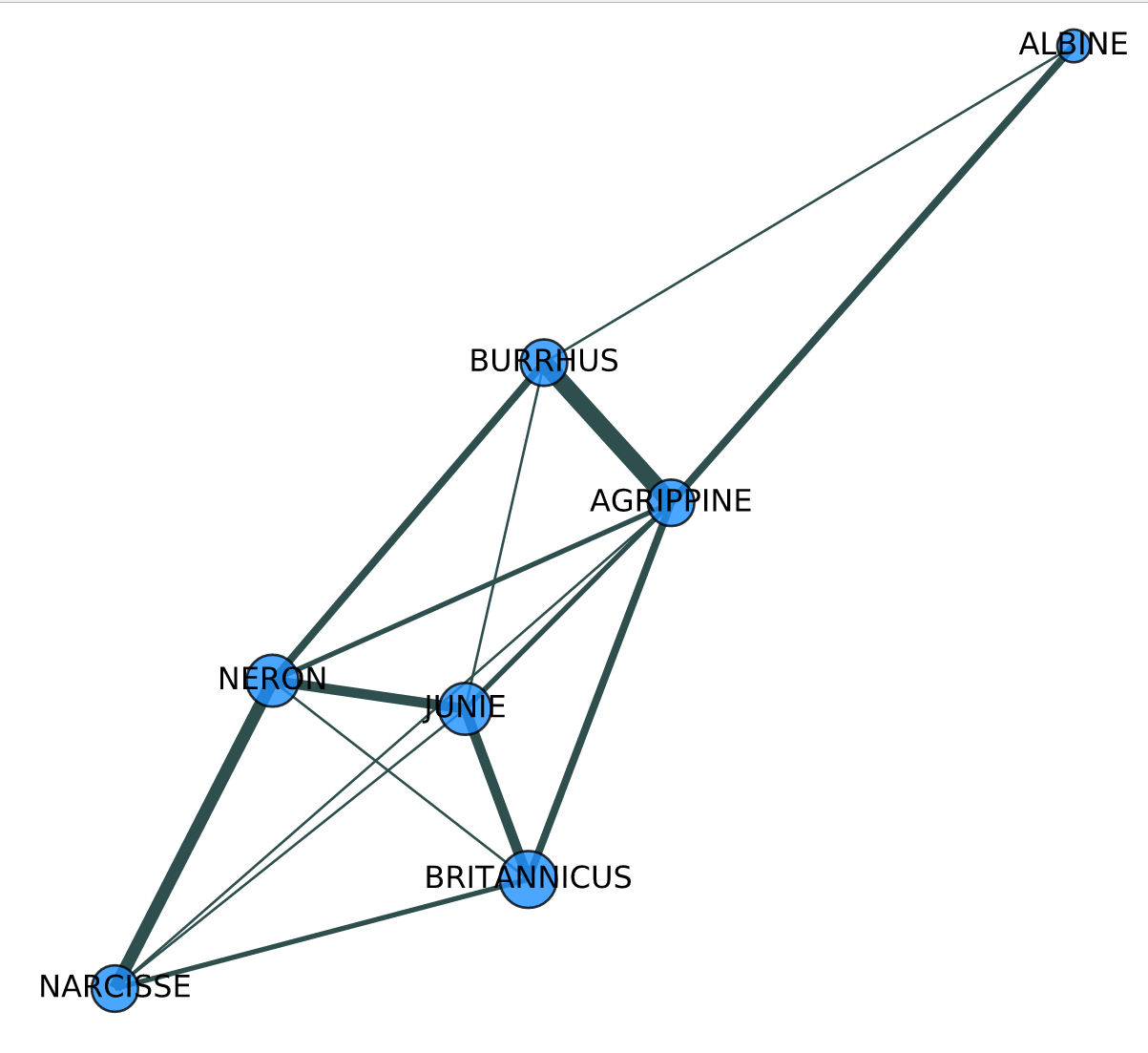
Figure 2. Character network based on number of words spoken in mutual presence (represented by the thickness of lines), for Jean Racine’s tragedy Britannicus (1669) (aus: (Schöch u.a., Abs. 44))
1.3. Textometrische Analyse
Das folgende, interessante Beispiel zeigt die Nützlichkeit der semantischen Annotation; die hier herausgearbeitete spezifische Unterscheidungsmerkmal historischer Romane, wäre wohl bei menschlicher Lektüre nicht so leicht zu entdecken:
"Figure 4 shows an example of a specificities analysis with TXM where the collection of 24 Spanish-American novels has been partitioned by subgenre. The distinctive features of historical novels were calculated in comparison to the novels of other subgenres, using WordNet semantic classes as features (so-called lexnames, for lexicographer file names 13). The five most distinctive features are shown in the figure. Nouns denoting natural objects (noun.object), people (noun.people), and body parts (noun.body) have particularly high values for historical novels. Verbs of grooming, dressing, and bodily care (verb.body) and verbs of being, having, and spatial relations (verb.stative) are underrepresented in historical novels when compared to novels from other subgenres. Interestingly, by far the most distinctive feature (verb.stative) is one that is particularly weak in historical novels." (Schöch u.a., Link, Abs. 49)
Diese für das Englische eingerichteten semantischen Kategorien von lexnames wurden durch den FreeLing-Tagger mit den äquivalenten Bezeichnungen der romanischen Sprachen verknüpft:
"We decided to use the tagger of the NLP package FreeLing (see Padró and Stanislovsky 2012) for the linguistic annotations because its tagset is quite fine-grained and it comprises WordNet-based sense annotation and disambiguation (on WordNet in general, see Miller 1995 and Fellbaum 1998)." (Schöch u.a., Link, Abs. 21
So lässt sich die im vorletzten Zitat erwähnte Sonderstellung der Subgattung ‘historischer Romane’ eindrucksvoll herausarbeiten:
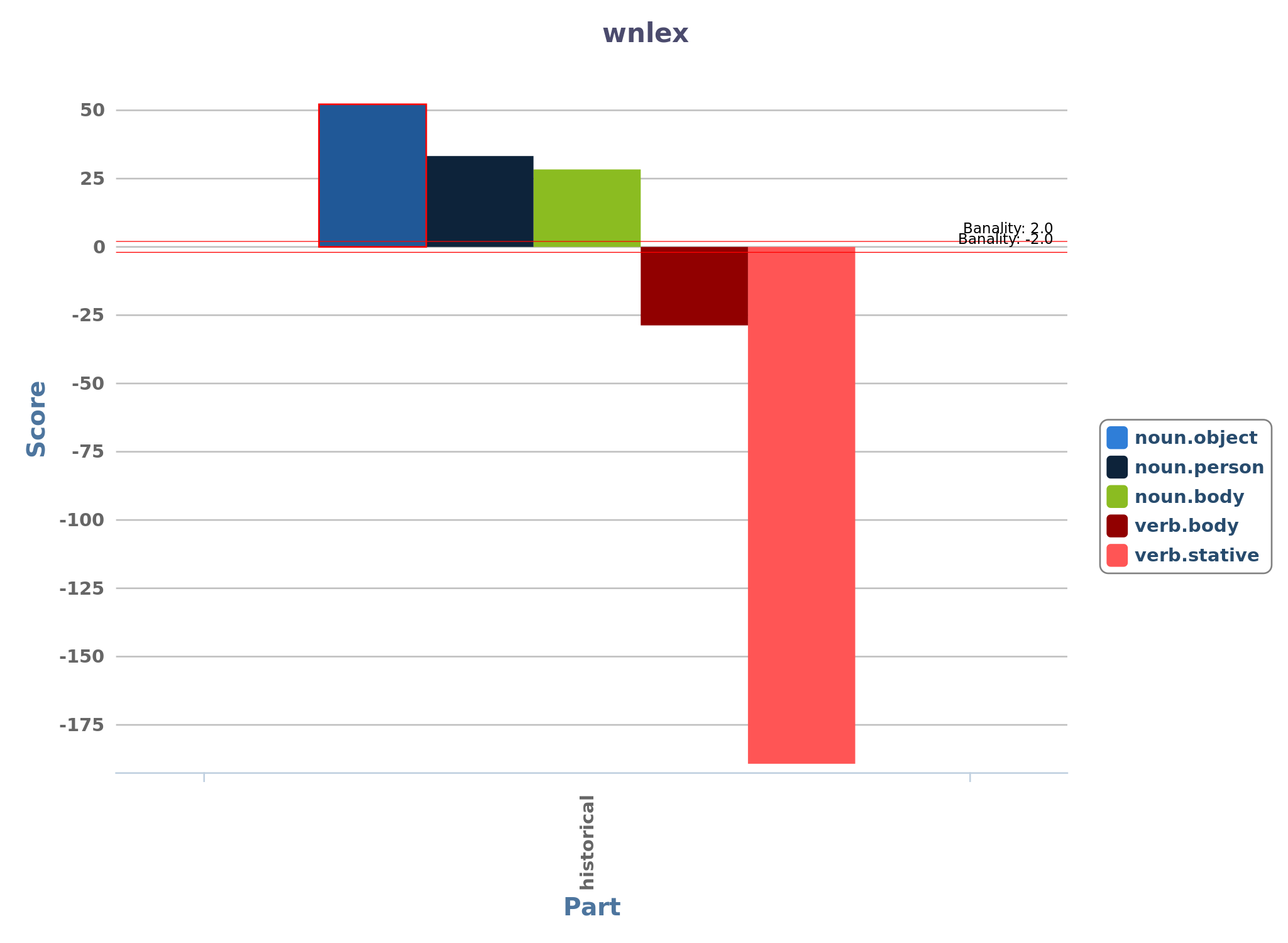
Figure 4. Specificities analysis with TXM (aus: (Schöch u.a.), Link, Abs. 49
2. Voyant Tools
Neben Texten werden auch webbasierte analytische Tools für Einzeltexte angeboten. Ein sehr nutzerfreundlicher Dienst ist Voyant Tools (Link ). Dieser Dienst liefert unterschiedliche Funktionen, die am Beispiel der Erzählung La patente (1911) von Luigi Pirandello (Quelle) vorgestellt werden sollen. Gibt man den Text im Format txt in das Upload-Fenster, wird ein Überblick mit allen Funktionen generiert (Link). Jede Funktion kann durch spezielle Links eingebettet werden, so wie die Summary:

Die 25 häufigsten Wörter der Novelle La patente (Link)
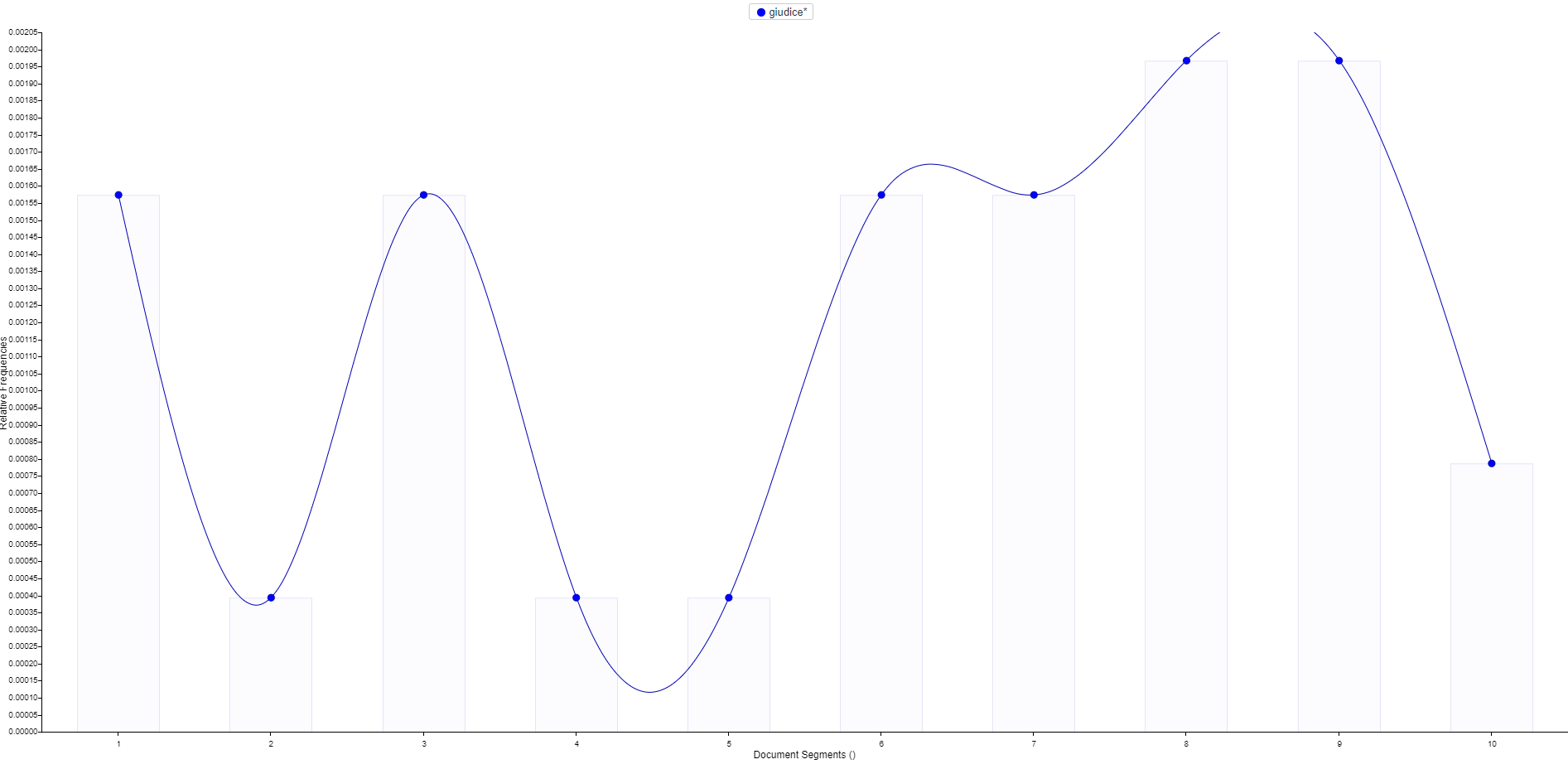
Häufigkeitsverteilung von giudice in La patente (Quelle)
Die Häufigkeitsverteilung von giudice (●), giustizia (●) und jettatore (●) zeigt ferner, dass die Gerechtigkeit nicht siegt, denn davon ist in der zweiten Hälfte nicht mehr die Rede:
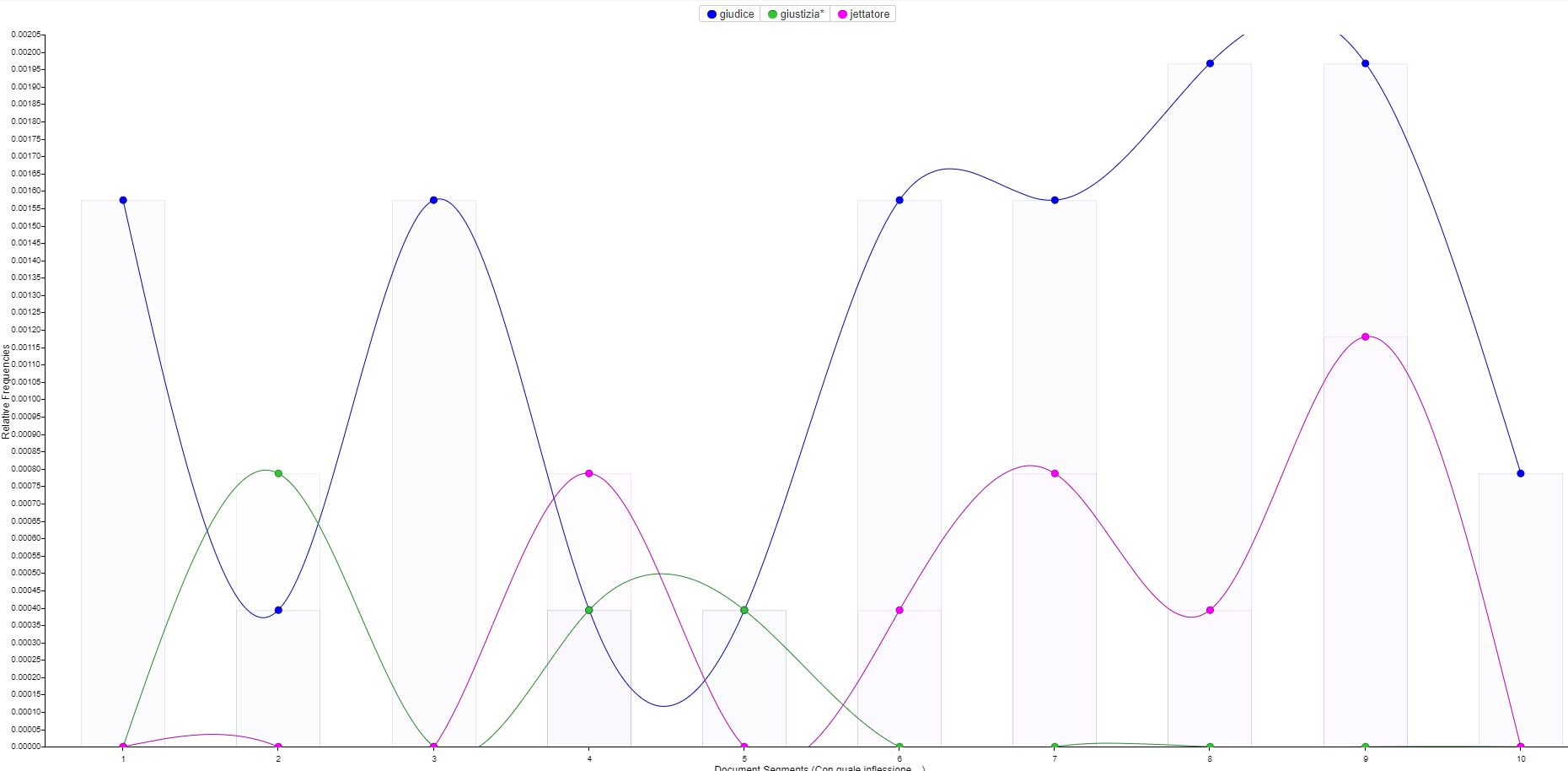
Verteilung von giudice (●), giustizia (●) und jettatore (●) in La patente (Quelle)
Die ganze Novelle erweist sich als Gegensatz von giustizia (●) und jettatura (●), bei konstantem Vorkommen des giudice, der vom einen ausgeht und beim anderen landet:
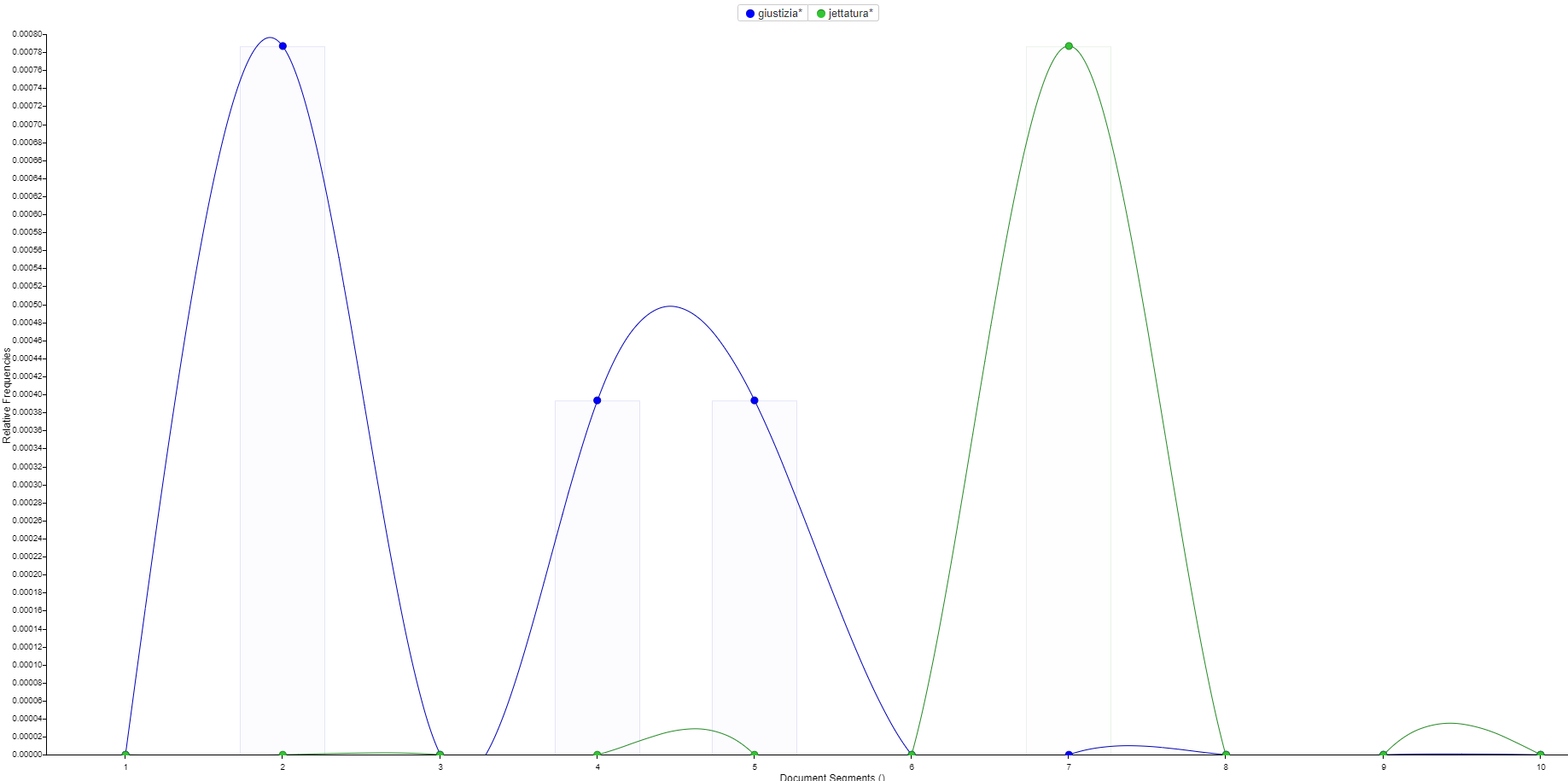
Der Gegensatz von giustizia (●) und jettatura (●) in La patente (Quelle)
Das Ungerechte (ita. iniquo, ●) lässt sich geradezu als Kern der Gerechtigkeit (ita. giustizia, ●) abbilden:
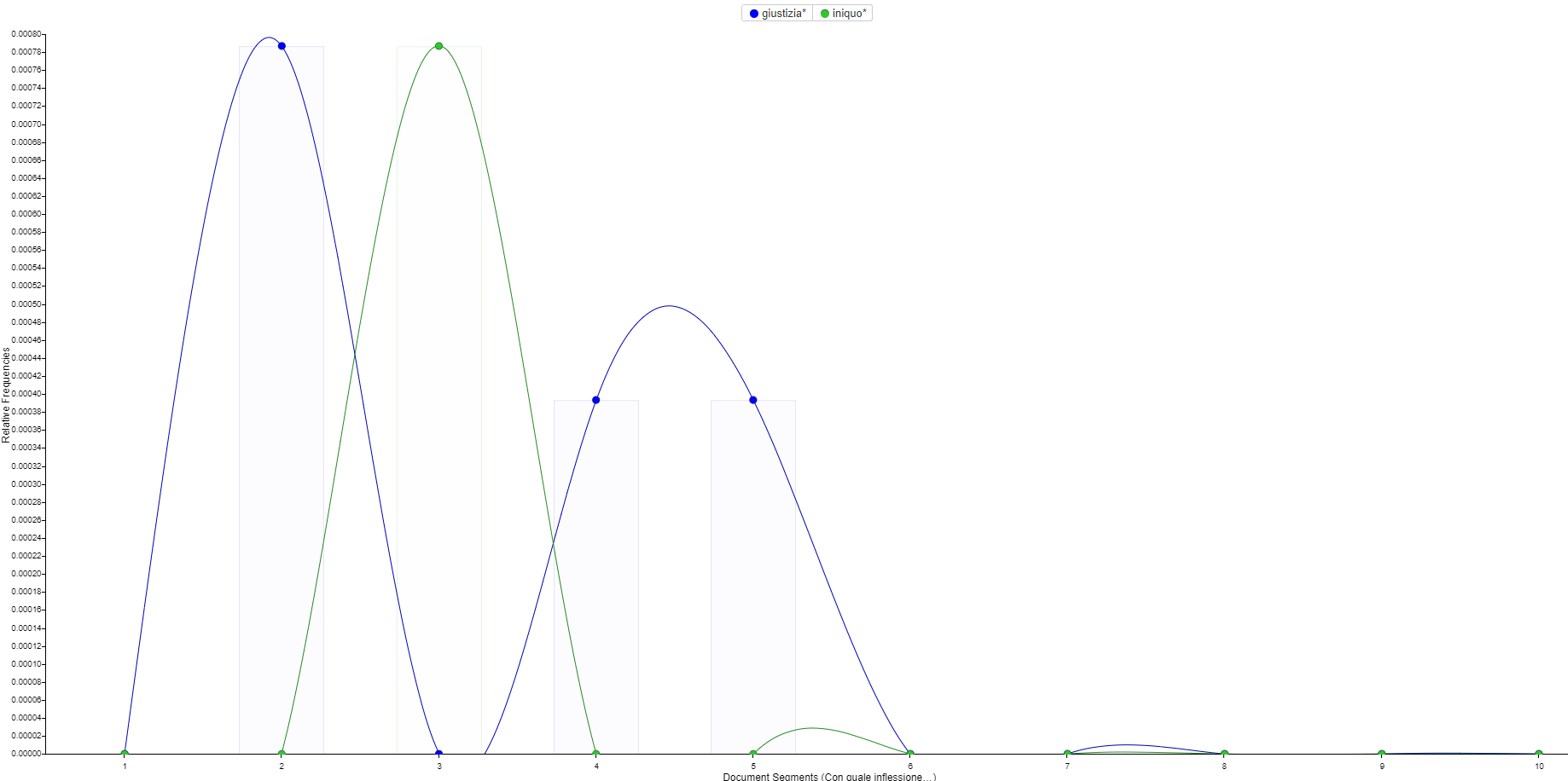
Iniquo (●) als Kernproblem von giustizia (●) in La patente (Quelle)
Bemerkenswert ist schließlich die Tatsache, dass die Überschrift, la patente ‘das Diplom/die Zulassung’, erst ganz zum Schluss auftritt auftritt (Segmente 9, 10) und sogar das letzte Wort darstellt: Darin manifestiert sich die titelgebende Schlusspointe - vermutlich ein prototypisches Merkmal der Gattung Novelle:
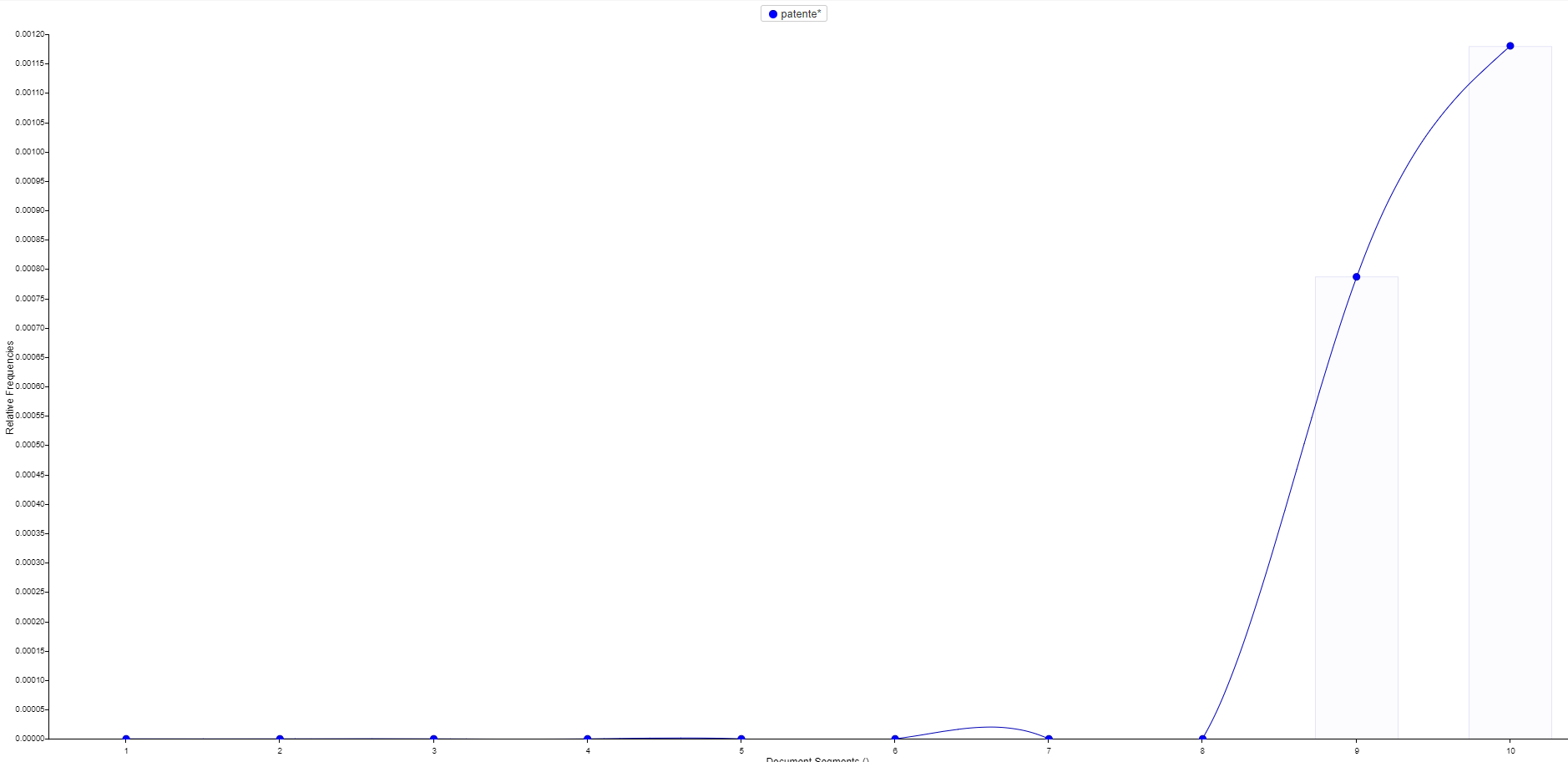
Der Titel als Pointe: la patente (Quelle)
Sehr schön ist auch die Auswahl an unterschiedlichen Visualisierungen, die allerdings zur etwas beunruhigenden Frage führt, was die Visualisierungen eigentlich leisten...
Bibliographie
- Fellbaum 2010 = Fellbaum, Christiane (Hrsg.) (2010): WordNet: An Electronic Lexical Database, Princeton, Princeton University (Link).
- Miller 1995 = Miller, George A. (1995): WordNet: A Lexical Database for English, in: Communications of the ACM, vol. 38, 39–41 (Link).
- Padró/Stanislovsky 2012 = Padró, Lluís / Stanislovsky, Evgeny (2012): FreeLing 3.0: Towards Wider Multilinguality , in: Proceedings of LREC 2012, Eighth International Conference on Language Resources and Evaluation, European Language Resources Association (Link).
- Schöch u.a. = Schöch, Christof / Calvo Tello, José / Henny-Krahmer, Ulrike / Popp, Stefanie (2019): The CLiGS Textbox: Building and Using Collections of Literary Texts in Romance Languages Encoded in TEI XML, in: Journal of the Text Encoding Initiative [Online] (Link).
- Schöch/Betz 2017 = Schöch, Christof / Betz, Kathrin (Hrsgg.) (2017): Corpus of Italian Novels, in: CLiGS, Würzburg (Link).