
1. Ein contrat social für die Wissenschaftskommunikation im Internet1
Forschung ist in ihrem Wesen kollaborativ: Denn Fortschritt gibt es nur auf der Grundlage des jeweils bereits verfügbaren Wissens. Im Rahmen der Wissensgesellschaft (Link), die sich durch die medial garantierte, permanente und flächendeckende Verfügbarkeit eines praktisch unbegrenzten Wissens auszeichnet, hat sich auch der Horizont der wissenschaftlichen Kollaboration radikal erweitert. Dafür ist vor allem die Tatsache verantwortlich, dass die totale Mediatisierung nicht nur den Wissenskonsum, sondern gleichermaßen die Wissensgenerierung durch Forschung betrifft, indem sie eine sehr breite, ortsunabhängige Kooperation ermöglicht. Ins Schlaraffenland sind die Forscher*innen damit freilich nicht gelangt, denn die Option auf Kooperation konkretisiert sich keineswegs automatisch. Sie erfordert vielmehr die Beachtung einiger elementarer Regeln, die seit kurzem von einer wichtigen Initiative mit dem prägnanten Akronym FAIR benannt und lanciert wurden (Link). Damit werden vier grundlegende ethische Prinzipien für die Wissenschaftskommunikation unter den Bedingungen der digitalen Medien identifiziert. Ihnen zufolge müssen Forschungsdaten
- F_indable (‘auffindbar’),
- A_ccessible (‘zugänglich’),
- I_nteroperable (‘kompatibel’),
- R_eusable (‘nachnutzbar’)
sein (Link). Die Anforderungen von drei (F, A, R) der vier Prinzipien zielen darauf ab, sowohl human readable als auch machine readable zu sein; sie gelten also sowohl für die Mensch↔Maschine↔Mensch-Kommunikation als auch für die Maschine↔Maschine-Kommunikation. Das vierte Prinzip (I) gilt nur für letztere; es ist jedoch im skizzierten virtuell-medialen Rahmen zentral für den Fortschritt der Forschung. Denn es repräsentiert die Unverzichtbarkeit der technologischen Komponente und die Transformation der LESER zu interaktiven NUTZERn, die je nach den (z.B. romanistischen) Interessen auf einem Kontinuum zwischen hochspezialisiertem Expertentum und völliger Laienschaft abgebildet werden können. Die interaktiven Nutzer*innen nähern sich den Daten nicht nur lesenden Auges, sondern womöglich mit der Absicht, sie für eigene Forschungszwecke zu verwenden und dafür maschinelle ‘Erntehelfer’ einzusetzen (sog. harvesting). Die FAIRness liefert nun nicht mehr und nicht weniger als die Grundlage eines Gesellschaftsvertrags, mit dem Forschung zu einer wirklichen res publica, einer öffentlichen Angelegenheit, werden kann.
Die Operationalisierung der FAIR-Prinzipien erfordert jedoch ein komplexes Zusammenspiel von Forscher*innen, das heißt de facto von befristeter und deshalb mehr oder weniger prekärer Projektarbeit einerseits und andererseits von Institutionen, die Dauerhaftigkeit in Aussicht stellen können; das sind in allererster Linie die großen Bibliotheken. Die Entwicklung von Prozeduren für diese ganz spezielle Art der Kooperation gehört zu den aktuellen Herausforderungen der Forschung, die mit dem Ausdruck Forschungsdatenmanagement (FDM) bezeichnet werden (vgl. Kümmet u.a. 2018b; Link).
Während sich der mit FAIR gemeinte Gesamtkomplex also klar umreißen lässt, sind Unterschiede in der Auslegung der einzelnen Kriterien nicht zu übersehen; sie sind wohl auch unvermeidbar (und letztlich unproblematisch), weil es sich nicht um ganz trennscharfe, sondern um sachlich mit einander verschränkte Anforderungen handelt. Im Folgenden werden die vier Prinzipien im Sinne von Lücke (2018b) und Krefeld/Lücke (2020) ausgelegt.
1.1. Findability - Über die beiden Suchwelten und ihre Verflechtung
Dieses Kriterium hat die längste Vorgeschichte, denn das Suchen und Finden der bereitgehaltenen Informationen begleitet die Sammelplätze des auf Papier niedergelegten Wissens, die Bibliotheken, seit eh und je. Es bedarf auch keiner Erwähnung, dass sich das Problem der Findbarkeit mit zunehmender Bibliotheksgröße verschärft. Mittlerweile bewegen wir uns jedoch in parallelen Suchwelten, um Wissensbestände zu finden.
1.1.1. Bibliothekskataloge
Die traditionelle Suche ist aus der Welt der gedruckten Publikationen entstanden und besteht in Katalogen, ursprünglich Kästen mit alphabetisch geordneten Karteikarten, die Verfassernamen, Titel und andere Angaben enthalten; idealerweise werden sie durch Schlagwortkataloge ergänzt, in denen man die Titel und Autor*innen nach KONZEPTEN, meist Themenbereichen ordnet; aus der Schlagwortvergabe sind wichtige Normdatenregister entstanden wie die (bereits erwähnte) GND der Deutschen Bibliothek in Frankfurt am Main:

Schlagwortkatalog (Quelle)
Mittlerweile wurden die Kästen weitestgehend durch elektronische Suchoberflächen (OPAC) ersetzt, wie z.B. an der Universitätsbiblothek der LMU (Link). Zudem wurde dieser Katalog in denjenigen des Bibliotheksverbunds Bayern integriert, so dass ein Buch auch dann gefunden wird, wenn es physisch an einem anderen Standort als in München aufbewahrt wird:
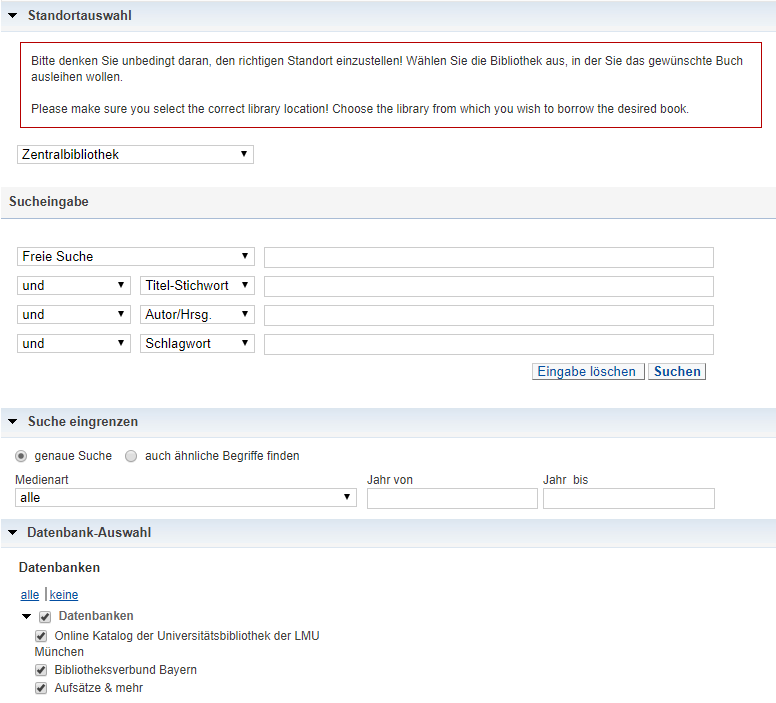
Man beachte den Unterschied zwischen den Suchkategorien ‘Titelstichwort’ und ‘Schlagwort’; erstere werden aus bestehenden Titeln extrahiert. Die zweite Kategorie besteht aus einer vorgegebenen Liste (informationstechnisch gesprochen: aus einem ‘kontrollierten Vokabular’) und wird - von Hand - einer Publikation zugeordnet, So findet man einen Titel wie Sprachliche Dynamiken nur deshalb unter ‘Titelstichwort’, weil es einen entsprechenden Titel gibt (Ellena 2015). Unter ‘Schlagwort’ ergibt die Suche nach Sprachlichen Dynamiken keine Treffer, weil der zuständige Bibliothekar diesen Ausdruck nicht als Schlagwort aufgenommen hat; andererseits findet man unter dem ‘Schlagwort’ Sprachwandel auch Titel, in denen engl. change auftaucht, oder solche, in den weder deu. Wandel noch engl. change steht, wenn der Gegenstand der Publikation als relevant für das gewählte Schlagwort, das heißt: das Konzept SPRACHWANDEL identifiziert wurde (Link). Die Dokumentation des Titel nennt auch eine eindeutige Identifikationsnummer für Verlagspublikation, die sogenannte International Standard Book Number (ISBN), die letzlich nur für die Bestellung des Buch im kommerziellen Handel erforderlich ist, jedoch für eine Suche, die nicht durch Kaufinteresse geleitet wird, keine Bedeutung hat.
1.1.2. Suchmaschinen im Web
Die Parallelwelt besteht in der Aktivierung von Suchmaschinen, die über Webbrowser angesprochen werden können. Suchmaschinen finden jedoch nicht nur Texte im alltagssprachlichen Sinn, sondern alle Dateien die ein Stück Text enthalten, z.B. Bilder, Sound usw.
1.1.3. Die hybride Welt
Suchmaschinen suchen Ketten von Zeichen (en. strings), die in identischen Kontexten auftreten. Wenn ich also z.B. in Google Chrome sprachliche Dynamiken suche, finde ich zwar auch - und zwar an erster Stelle und in Gestalt mehrerer Einträgen - den bereits zitierten Titel von Sandra Ellena, jedoch finde ich auch andere Titel wie (bei Abruf am 26.5.2020 auf Seite 10) z.B. die Masterarbeit von Monika (Hausmann), in deren Titel Dynamik und in deren erster Textzeile sprachliche vorkommt. Zu Grunde liegt offensichtliche eine Volltextsuche, die auch unvollständige Strings erfasst (so Dynamik bei der Eingabe von Dynamiken usw.). Das Beispiel zeigt, dass die Suchmaschinen auch Titel erfassen, die ausschließlich als Druckerzeugnis zugänglich sind, wie ((Ellena 2015); Link), und deshalb offenkundig aus der Welt der Kataloge extrahiert wurden.
Andererseits finden sich in den virtuellen Bibliothekskatalogen inzwischen auch genuine, niemals gedruckte Web-Publikationen, so führt die Suche nach Verba Alpina im OPAC der UB der LMU zu einem Treffer (Link), der auf die Projektseite weiterleitet. Um die Suchlogik zu verstehen, ist es wichtig darauf hinzuweisen, das die Projektseite im Katalog nicht über eine einfache URL identifiziert wird sondern über einen sogenannten DOI (‘digital object identifier’): http://dx.doi.org/10.5282/verba-alpina.
"Um gefunden werden können, müssen Daten selbstverständlich auch physisch existent sein. Hierbei geht es weniger um die Frage der technischen Realisierung, die z.B. durch die flächendeckend bestehenden Rechenzentren geleistet werden kann, sondern vielmehr um die Frage nach der institutionellen Zuständigkeit. Auch unter diesem Aspekt bieten sich wiederum die Bibliotheken an, die aufgrund ihrer Geschichte, ihrer genuinen Aufgabe als Wissensbewahrer sowie ihrer langfristigen Bestandsperspektive eigentlich als konkurrenzlose Kandidaten für diese Aufgabe angesehen werden können. Sie sollten die Verantwortung für die nachhaltige Bewahrung der digitalen Daten übernehmen. In welcher Form dies schließlich geschieht, ob die Bibliotheken eigene Repositorien aufbauen und verwalten oder auf Rechenzentren als Dienstleister zurückgreifen, ist von nachrangiger Bedeutung und kann von Fall zu Fall unterschiedlich gehandhabt werden.
Große Bedeutung besitzt die Konzeption und Vergabe von Metadaten, über die die eigentlichen Forschungsdaten auffindbar gemacht werden müssen. Unverzichtbar erscheint die Verwendung mindestens eines verbindlichen, hierarchisch aufgebauten Metadatenschemas, das unter Einbindung ebenfalls verbindlicher kontrollierter Vokabulare eine inhaltliche Kategorisierung der abgelegten Forschungsdaten erlaubt. VerbaAlpina hat sich vorläufig für das weit verbreitete und auch von der UB der LMU gewählte Datacite-Schema entschieden. Der Einsatz mehrerer konkurrierender Metadatenschemata wäre möglich, jedoch nur sinnvoll, wenn sie jeweils konsequent für alle erfassten Forschungsdaten angelegt werden. Untergeordnete fachspezifische Metadatenschemata können eine sinnvolle Ergänzung der übergeordneten Metadatenschemata darstellen." (Lücke 2018b)
1.2. Accessibility - Rechte von Urhebern und Nutzern
Auch in der Forschungspraxis spielen juristische Aspekte eine grundlegende Rolle: Darf ich Daten, die für mich relevant sind, weil sie in den Horizont meines Erkenntisinteresses fallen, überhaupt verwenden? Stephan Lücke (Link) sieht im eindeutigen Umgang mit dieser Frage den Kern des Accessibility-Prinzips: Empfohlen werden die international weithin anerkannten Lizenzierungen der (gemeinnützigen) Creative Commons-Organisation (Link), insbesondere die Regelung CC BY SA (Link), die auch für die Lehr-, Lern- und Forschungsumgebung der LMU gilt, in der diese Vorlesung publiziert wird. Die Lizenzierung erfordert vom Nutzer die Nennung des Urhebers (BY) und die Weitergabe der Daten unter genau denselben Bedingungen, die bereits für die Quelle gelten (S[hare] A[like]).
Zu beachten ist allerdings der Hinweis, dass
"nicht alle [CC Lizenzierungen; Th.K.] die Kriterien für Open Access erfüllen. Insbesondere verstößt das Verbot kommerzieller Nutzung, das Teil einer CC-Lizenz sein kann, gegen das Konzept von Open Access. Der Grund besteht darin, dass nahezu jede Verwendung von Daten unter Umständen als "kommerzielle Nutzung" angesehen werden kann und eine klare Grenzziehung diesbezüglich aus juristischer Sicht so gut wie unmöglich ist". (Lücke 2018b)
Ganz und gar nicht vereinbar mit dem Accessibility-Prinzip ist das traditionelle Copyright (©), das in der Verlagswelt noch weithin Gültigkeit besitzt. Verlage verlangen übrigens von ihren Autoren in der Regel die Abtretung aller Rechte, um so in den Besitz des Copyrights zu gelangen. Am Beispiel des kürzlich von Antje Lobin u.a. herausgegebenen Sammelbands liest sich das auf der Rückseite der Titelseite folgendermaßen:

Es wäre jedoch (leider) ein Irrtum zu glauben, die juristische Einschränkung des Zugangs sei fest mit dem Format des gedruckten Buchs verbunden und würde sich mit dem Medienwechsel zur Webpublikation von selbst erübrigen. Denn es finden sich sogar genuine und technisch durchaus avancierte Webprojekte mit entsprechenden Beschränkungen. Ein (ärgerliches) Beispiel ist der TLIO (Link), also das noch im Aufbau befindliche, maßgebliche Wörterbuch des Altitalienischen. Dieses Werk basiert auf einem digitalen Korpus von 2700 Texten (Link). Es ist alles bestens dokumentiert, überaus informativ und entsprechend nützlich; jede erfasste Form wird im Gebrauchkontext präsentiert. Einen Lizenzierungshinweis findet man freilich nicht, auch kein Copyright; ebenso wenig werden persistente Identifikatoren (IDs) der einzelnen Lemmata, geschweige denn ihrer oft zahlreichen Varianten geliefert. Jeder Download wird explizit verboten, Das Lexikon verhält sich, mit anderen Worten, genauso wie ein gedrucktes Wörterbuch:
"Il corpus interrogabile a questo indirizzo è quello costituito e utilizzato dall’Opera del Vocabolario Italiano per la redazione del Tesoro della Lingua Italiana delle Origini.
Contiene 2700 testi per complessive 22.638.114 occorrenze di 471.357 forme grafiche distinte.
È reso disponibile in rete per le ricerche linguistiche e consente di scaricare brevi citazioni per uso di ricerca.
Lo scaricamento dei testi è vietato." (Quelle)
Wichtig für die Perspektive der Digital Humanities ist die Tatsache, das der Schutz intellektueller und künstlerischer Produkte nach dem Urheberrecht (Link) auch verfallen kann; in der EU und in der Schweiz erlischt der Schutz 70 Jahre nach dem Tod des Urhebers (Link) und das geschützte Gut wird ‘gemeinfrei’ (Link). So ist eine erhebliche Menge von gedruckten Texten, Bildern, Filmen und Audioaufnahmen für eine digitale Tiefenerschließung und nachfolgende Analysen in Portalen wie dem Internet Archive (Link) verfügbar; hier besteht ein erhebliches Potential für DH-Projekte. Oft werden die Materialien in zwar digitaler, aber kaum oder gar nicht strukturierter Form angeboten, wie z.B. die Ausgabe der Promessi sposi von Alessandro Manzoni aus dem Jahre 1840 (Link). Noch vollkommen unerschlossen erscheinen vor allem Sound und Filmdokumente, wie zum Beispiel der bemerkenswerte Dokumentarfilm Comizi d’amore von Pier Paolo Pasosolini (Link; zum Film vgl. diesen Link). Überhaupt ist die frühe Phase der Audiodokumentation seit der Etablierung des Radios und des Kinos sprachgeschichtlich kaum aufgearbeitet worden (verfügbar wären z.B. öffentliche Politikerreden, etwa Mussolinis Kriegserklärung; Link).
1.3. Interoperability - Kommunikation zwischen Maschinen
Die Zugänglichkeit (A) ist notwendige und - mindestens in der Praxis - auch hinreichende Voraussetzung für die informationstechnische Interoperabilität (I).
"Interoperabilität in dem Sinn, dass persistente projekt- bzw. datenbestandsübergreifende Verknüpfungen zwischen Teilmengen der jeweiligen Datenbestände möglich sind. Eine wichtige Rolle spielen dabei die sog. DOIs, ‘Digital Object Identifier’. Diese stellen die technische Voraussetzung für die dauerhafte, URL-unabhängige Adressierbarkeit ‘digitaler Objekte’ dar und sind für alle elektronischen Inhalte erzeugbar, die über eine URL erreichbar sind. Im Umfeld des Bibliothekswesens wurden DOIs zunächst zur persistenten Identifizierung von elektronischen Buchpublikationen (z.B. https://doi.org/10.5282/ubm/epub.25627) oder auch ganzen Websites (z.B. http://dx.doi.org.emedien.ub.uni-muenchen.de/10.5282/asica) verwendet." (Kümmet u.a. 2018b)
Ein solcher DOI wurde von der UB der LMU auch für das Projekt VerbaAlpina vergeben. In Verbindung mit der URL der DOI Foundation lässt sich die Seite des Projekt über
- http://dx.doi.org/10.5282/verba-alpina
ansprechen. Allerdings ist die technische Interoperabilität damit noch nicht gewährleistet; es muss ja die Möglichkeit bestehen auch spezifische Daten(gruppen) aus dem Gesamtbestand anzusprechen und womöglich zu extrahieren. Nur solche Dateien, die im Internet über eine Adresse zuverlässig (‘persistent’) identifiziert werden können, bilden gewissermaßen digitale Objekte; je spezifischer diese Dateien sind, umso feiner ist die ‘Granulierung’ des Datenbestands. Wenn also z.B. Lexika verknüpft werden sollen, ist es erforderlich (mindestens) jedes Lemma, oder: Stichwort, als spezifisches Objekt zu definieren.
"V[erba]A[lpina] erzeugt zu diesem Zweck eine Reihe von im Internet über URLs erreichbaren Dateien, die das gesammelte Sprachmaterial gruppiert nach morpholexikalischen Typen, Konzepten, Herkunftsgemeinden und Einzelbelegen enthalten. Die Dateien sind mit den jeweils von VA vergebenen IDs der jeweiligen Datenkategorie benannt. Dateien der Kategorie "Gemeinde" tragen am Anfang des Dateinamens ein "A", "C" markiert Konzepte und "L" morpholexikalische Typen. Die jeweils nachfolgende Nummer ist die von VA vergebene ID. Der Zugriff auf diese Daten ist über die Adresse https://www.verba-alpina.gwi.uni-muenchen.de/export möglich. Die Zuweisung der DOIs erfolgt zunächst im Rahmen des Projekts "eHumanities – interdisziplinär" durch die UB der LMU, die überdies die Daten in ihren eigenen Datenbestand übernimmt und dort durch noch zu entwickelnde Verfahren und unter Anwendung eines geeigneten Metadatenschemas zusätzlich in der Tiefe inhaltlich erschließt. Ziel ist neben der Bereitstellung der Forschungsdaten im Repositorium die Integration und Auffindbarkeit der feingranulierten VA-Daten in den Bibliothekskatalogen. Aus dem Bestand der UB der LMU werden die VA-Daten außerdem in den Index des DFG-Projekts GeRDI übernommen und damit einer Nachnutzung in interdisziplinären Kontexten zugeführt." (Kümmet u.a. 2018b)
Die Funktionalität soll an einem konkreten Beispiel illustriert werden. Für das Konzept ALMHÜTTE (Karte) finden sich (in Version 19/2) insgesamt 1314 dialektale Bezeichnungen (Link). Von der UB wurden nun alle mit diesem Konzept verbundenen Datensätze gemäß dem Datacite-Metadatenschema dargestellt und mit Normdaten zu den beteiligten Personen (GND ID, orcid) und Institutionen angereichert. So wird am Schluss jedes Datacite-Eintrags die finanzierende Einrichtung, die DFG, folgendermaßen kodiert ist:
<fundingReferences>
-<fundingReference>
<funderName>DFG</funderName>
<funderIdentifier funderIdentifierType="ISNI">http://isni.org/isni/0000000120969829</funderIdentifier><awardNumber awardURI="http://gepris.dfg.de/gepris/projekt/253900505">253900505</awardNumber><awardTitle>VERBA ALPINA. Der alpine Kulturraum im Spiegel seiner Mehrsprachigkeit</awardTitle>
</fundingReference>
Im Folgenden werden nur Auszüge dieses einen Beispiels wiedergegeben, um das Prinzip zu illustrieren. Man beachte, dass eingangs der DOI des Projekts mit der Konzept-ID aus VerbaAlpina (= C1) und der Versionsnummer der VerbaAlpina-Seite (182) spezifiziert wird. Außerdem werden

Anfang des Datacite-Schemas für das VA Konzept C1 (ALMHÜTTE)
Weiterhin werden dann alle Gemeinden mit den von VerbaAlpina (samt Geocodes) und alle zugehörigen Belege mit den ebenfalls von VerbaAlpina vergebenen S-IDs für die erfassten sprachlichen Formen (‘Tokens’) verknüpft, wie der folgenden Ausschnitt zeigt:
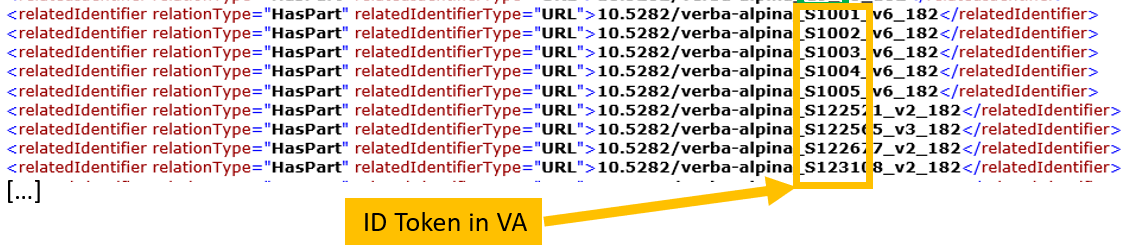
Datacite mit S IDs von Einzelbelegen
Die S-ID der letzten Zeile des Ausschnitts (= S 123108) ist mit dem entsprechenden Eintrag in der VA-Datenbank (Tabelle der Tokens) verbindbar, wie der nächste Ausschnitt belegt. Wir erfahren, dass die Form von einem Nutzer der Crowdsourcing-Funktion namens <paoloroseano> am 17. Februar 2017 eingetragen wurde:

Dokumentation der S-ID 123108 in der VerbaAlpina-Datenbank
Analoge Datacite-Schemata werden für jede Gemeinde (G-ID), jeden Morpho-lexikalischen Typen (L-ID) und jede belegte sprachliche Form (S-ID) automatisch generiert. Im Datacite-File der einzelnen Belege werden übrigens auch die IDs der Informanten erfasst, so dass die Zuweisung der Belege zu den Informanten jederzeit vollkommen transparent ist; aus der VA-Datenbank lässt daher ermitteln, wie viele (103) und welche Belege dieser Informant an welchem Datum geliefert hat:
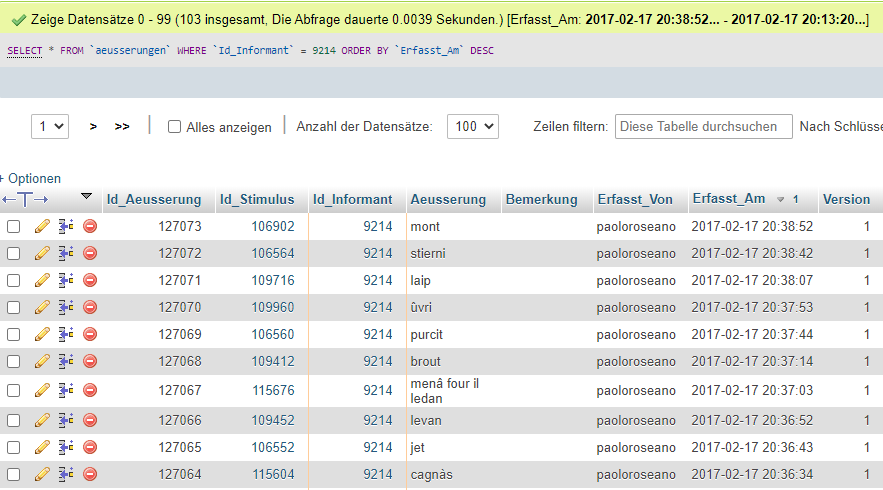
Ausschnitt zur Dokumentation eines Nutzers der Crowdsourcing -Funktion
Eine besondere Erwähnung verdient übrigens die Sprachkodierung; wie der folgende Ausschnitte zeigt, wird die Klassifikation des Glottolog (Link) zu Grunde gelegt:

Normdaten für die Sprachcodierung in der VA Datacite-Abbildung
Den erfassten alpinen Dialekten der germanischen, romanischen und slawischen Sprachfamilie entsprechen die Kategorien: ‘High German’ (ID 1286), ‘Shifted Western Romance’ (ID 1235) und ‘Western South Slavic’ (ID 3147). Diese Klassifikation verdient eine genauere Auseinandersetzung, die hier nicht geleistet werden kann; sie bietet jedenfalls den Vorteil, große Ausschnitte von Dialektkontinua zu identifizieren, ohne auf Standardsprachen oder Dialekte unklarer Abgrenzung rekurrieren zu müssen.
1.4. Reusability - das Weiterleben der Projekte nach ihrem Ende
Wärend sich I, A und F logisch implizieren (I → A → F), ist das Verhältnis von R zu den drei anderen Prinzipien komplexer, denn über die reine Implikation hinaus - auch R impliziert A, I und F (R → {A, I, F}) - setzt die Nachnutzbarkeit eine verlässliche, d.h. dauerhafte Sicherung und Betreuung der Forschungsdaten voraus. Das zu garantieren liegt leider nicht mehr in der Hand der Wissenschaften, sondern ist Aufgabe der Wissenschaftspolitik. Sehr wohl sind die Wissenschaften jedoch in der Pflicht, die Schaffung geeigneter Strukturen von der Politik einzufordern.
Zusammenfassend lassen sich unsere vier Prinzipien mit den folgenden Schlagworten charakterisieren:
| semantisch: Wissen gezielt vermehren können | |
| juristisch: vorhandenes Wissen verwenden dürfen | |
| informationstechnisch: vorhandenes Wissen maschinell verarbeiten können | |
| verlässlich: auf garantiertes Wissen zurückgreifen können |
2. Jenseits der Gutenberg-Galaxis - ein polemischer Epilog
Es wurde in der Vorstellung des Accessibility-Prinzips bereits angedeutet, dass sich eine FAIRe webbasierte Forschung jenseits der Gutenberg-Galaxis bewegt: Die genannten Prinzipien sind mit kommerzieller Publikationspraxis, wie sie durch Verlage betrieben wird, praktisch nicht vereinbar ist. Entsprechende virtuelle Umgebungen müssen daher von Wissenschaftsverlagen als existentielle Bedrohung empfunden werden. Das mag man angesichts ihrer kulturgeschichtlichen Bedeutung bedauern; es ist jedoch eine unvermeidbare Folge des medialen Fortschritts.
Trotzdem ist es nicht akzeptabel, wenn Verlage in irreführender Weise für ihr Verhalten in der Wissenschaftkommunikation den Begriff open access reklamieren, wie es zum Beispiel eines der führenden Verlagshäuser im Bereich der Sprachwissenschaft, der de Gruyter-Verlag, offensiv unternimmt:
"Open Access ermöglicht freien und unbeschränkten Zugang zu Ihren Inhalten. Ihre Inhalte sind von überall auf der Welt zugänglich und erreichen somit eine größere, vielfältigere, internationale Leserschaft." (Quelle)
Nichts, gar nichts an der Art und Weise, wie dieses Haus seine Produkte bereitstellt, wird der Open Access-Bewegung gerecht.
Bibliographie
- Ellena 2015 = Ellena, Sandra (2015): Maria Selig/Gerald Bernhard (edd.), Sprachliche Dynamiken. Das Italienische in Geschichte und Gegenwart (Studia Romanica et Linguistica, 34), Frankfurt am Main et al., Lang, 2011, 253 p., in: Zeitschrift für romanische Philologie, vol. 131, 4, De Gruyter Mouton, 1206-1212.
- Hausmann 2019 = Hausmann, Monika (2019): Varietätenkontakt und diagenerationelle Dynamik in Praia a Mare (CS), München, LMU (Link).
- Krefeld 2020l = Krefeld, Thomas (2020): FAIRness: ein contrat social für die Wissenschaftskommunikation im Internet, FID Romanistik (Link).
- Krefeld/Lücke (2020) = Krefeld, Thomas / Lücke, Stephan (2020): 54 Monate. VerbaAlpina – auf dem Weg zur FAIRness, in: Ladinia, vol. XLIII, 139-155.
- Kümmet u.a. 2018b = Kümmet, Sonja / Lücke, Stephan / Schulz, Julian / Zacherl, Florian (2018): Forschungsdatenmanagement, in: Methodologie, VerbaAlpina-de 19/1 (Link).
- Lobin u.a. 2020 = Lobin, Antje / Dessì Schmid, Sarah / Fesenmeier, Ludwig (Hrsgg.) (2020): Norm und Hybridität / Ibridità e norma. Linguistische Perspektiven / Prospettive linguistiche, Berlin, Frank & Thimme.
- Lücke 2018b = Lücke, Stephan (2018): FAIR-Prinzipien, in: Methodologie, VerbaAlpina-de 18/2 (Link).
- Lücke 2019d = Lücke, Stephan (2019): Lizenzierung, in: Methodologie, VerbaAlpina-de 19/1 (Link).
- Lücke/Schulz 2018 = Lücke, Stephan / Schulz, Julian (2018): Digital Object Identifier (DOI), in: Methodologie, VerbaAlpina-de 18/2 (Link).
- TLIO = Leonardi, Lino (2017): Tesoro della Lingua Italiana delle Origini Il primo dizionario storico dell'italiano antico che nasce direttamente in rete fondato da Pietro G. Beltrami. Data di prima pubblicazione: 15.10.1997 (Link).
- Wilkinson u.a. 2016b = Wilkinson, M. / Dumontier, M. / Aalbersberg, I. (2016): The FAIR Guiding Principles for scientific data management and stewardship, in: Sci Data, vol. 3 (Link).