
Diese Veranstaltung ist Teil der IDK Ringvorlesung "Vormoderne Praktiken der Philologie" im Wintersemester 2022/2023 (6. Februar 2023).

digitales begreifen: qr code
1. "Digitales begreifen" und "digitales Begreifen"
Die digitale Welt läßt sich zunächst nur schwer begreiflich machen. Wenn wir einen Blick in unseren Serverraum werfen, sieht man von vorne nicht viel (die Serveranlage der geisteswissenschaftlichen Fakultäten in 4 Schränken mit Rechnern, Speicher- und Netzkomponenten, Batterien, Konsolenmonitore, Tastatur, darüber die Klimaanlage) ...

ITG: Serveranlage Vorderansicht
... und von hinten nur einen verwirrenden Kabelsalat. So sieht Vernetzung aus.

ITG: Serveranlagen Rückansicht
Was sich in den Rechnern und Kabeln abspielt bleibt zunächst verborgen - fast möchte man Antoine de Saint-Exupéry zitieren: "Das Wesentliche ist für die Augen unsichtbar". Die Welt der Signale und Signalzustände, die Welt der Bits und Bytes, die Welt der Maschinensprache, offenbart sich aber dann doch wieder für uns auf analoge Art und Weise wahrnehmbar auf den sog. Datensichtgeräten: Monitore, Displays mobiler Geräte, Beamer, Lautsprecher, Drucker. Andererseits stehen uns neben einfachen Tastaturen eine Reihe von Geräten wie z.B. Scanner, Kameras, digitale Video- und Audiotechnik usw. zur Verfügung, um Texte, Dokumente, Bilder, Filme, Musik, Architektur usw. in die Welt der Rechner und Kabel hineinzubekommen und sie darin zu teilen.
All diese Techniken - und letztlich auch die Tatsache, dass diese von einer dauerhaften Stromversorgung und Netzanbindung abhängig sind - sind für uns mittlerweile mehr oder weniger selbstverständlich geworden und daher halte ich es umso sinnvoller, darüber nachzudenken, wie diese beiden Welten - analoge Welt und digitale Welt, Menschenwelt und Maschinenwelt, Mensch und Computer - sich zu einander verhalten und wie diese in Dialog miteinander treten können.
Der Titel der Vorlesung - digitales begreifen - ist so gewählt, dass zwei Deutungen möglich sind:
- Digitales begreifen hat mehr die menschliche Seite im Blick: Was muss der Mensch tun bzw. lernen, um das Digitale zu begreifen? Welche Voraussetzungen müssen geschaffen werden, damit die menschliche Welt dem Computer mitgeteilt und vom Computer verarbeitet werden kann? (Frage der Data Literacy/Datenkompetenz)
- digitales Begreifen hat mehr die Seite des Computers im Blick: Wie kann der Computer etwas begreifen bzw. mit vorgegebenen Daten rechnen? Was muss auf Seiten des Computers geschehen, damit Daten berechnet, Entscheidungen getroffen und Ergebnisse präsentiert werden können? (u.a. Frage nach Explainable AI)
Nehmen wir diese kurze Textpassage - im Rückblick auf die wunderschönen Auszüge von Handschriften und Drucke der vorhergehenden Vorlesungen - als Beispiel von Text (in normalen Lettern) und Kommentar (in kursiven Lettern):
Wie kann der Computer zwischen Text und Kommentar unterscheiden?
Wie kann der Computer Wortarten unterscheiden (Substantiv + Verb/Infinitiv vs. Adjektiv + Substantiv<Infinitiv)?
Dem Computer müssen zusätzliche Informationen gegeben werden. Es bedarf der Beschreibung und strukturalen Auszeichnung/Annotation, nämlich der Markierung von Anfang und Ende von Textpassagen bzw. Kommentarpassagen mit Zuordnung der jeweiligen Funktion, ferner die Zuordnung von Wortarten.
Beide Deutungen - Digitales begreifen und digitales Begreifen - sind eng aufeinander bezogen. Letztlich läuft es auf die Frage hinaus: Wieviel Mensch steckt im Computer? Die Frage ist keineswegs belanglos, da der Computer auf der Grundlage vorgegebener Daten rechnet. Dabei handelt es sich nicht immer um rein objektiv erhobene Daten, wie z.B. Mess-, Erhebungs- oder Logdaten. Vielmehr haben wir es im Bereich der deskriptiven Wissenschaften wie in unserem Fall der Philologie mit subjektiven Beschreibungen einer - wie wir in vorangegangenen Vorlesungen gesehen haben - sehr vielfältigen philologischen Wirklichkeit zu tun. Der Transparenz des Beschreibungsprozesses und der Qualität der Daten hinsichtlich ihrer Nachprüfbarkeit, Genauigkeit und Vollständigkeit kommt bei der digitalen Abbildung der philologischen Wirklichkeit eine entscheidende Bedeutung zu. Die abgebildeten Daten repräsentieren eine Sicht auf die Wirklichkeit (genauer: einen Ausschnitt der Wirklichkeit). Alle weiteren Verknüpfungen und Schlußfolgerungen, die der Computer berechnet, beruhen auf den vorgegebenen Daten.
2. Digitalisierung
2.1. Digitalisierung - eine etymologische Annäherung
Etymologisches Wörterbuch der deutschen Sprache (Kluge u.a. 1989)
digital Adj. 'in Ziffern dargestellt; auf Zahlen-(kodes) basierend', fachsprachl. Im 20. Jh. entlehnt aus gleichbedeutend ne. digital, zu e. digit 'Ziffer', aus l. digitus 'Finger', in Redewendungen auch 'Zahl' (vom Rechnen mit den Fingern).
Morphologisch zugehörig: Digit, digitalisieren;
etymologisch verwandt: binär, Bit.
Bit n. 'Binärzeichen' , fachsprachl. Im 20. Jh. entlehnt aus gleichbedeutend ne. bit, einem Kunstwort aus e. binary digit 'binäre Zahl'.
E. binary geht (wie auch d. binär) zurück auf l. binarius 'zwei enthaltend', zu l. binus 'je zwei';
e. digit 'Ziffer, Zahl' basiert auf l. digitus (der zum Zählen benutze) Finger'.
Ein Bit ist eine Informationseinheit, die genau zwei Zustände einnehmen kann (z.B. "ja/nein").
Das Binärzahlsystem stellt alle Zahlen auf der Basis von zwei Symbolen dar (im Gegensatz zu zehn Symbolen beim Dezimal-, und sechzehn Symbolen im Hexadezimalsystem).
Digitalisierung meint also einen Transformationsprozess von einer Wirklichkeit in eine in Ziffern bzw. Zahlen dargestellte Wirklichkeit, anders gesagt: Die Abbildung der Wirklichkeit/Welt in Zahlenkodes (zum Zweck der Verarbeitung durch eine Rechenmaschine).
Rechnen mit den Fingern - eine uralte Kulturtechnik
- 10 Finger einer Hand (Dezimalsystem)
- 12 Fingerglieder einer Hand (Duodezimalsystem)
- 5 Finger einer Hand, 12 Fingerglieder der anderen Hand (Sexagesimalsystem)
Signalzustände
- Low-Pegel (Strom fließt nicht) vs. High-Pegel (Strom fließt)
- logisch null (0) / FALSE vs. logisch eins (1) / TRUE
Exkurs: Musikautomaten - Luft fließt nicht vs. Luft fließt

Deutsches Museum: Phonoliszt Violina
Zahlensysteme: Stellenwertsystem (gemäß Wikipedia, Artikel Stellenwertsystem) vs. Additionssystem
Ein Stellenwertsystem [...] ist ein Zahlensystem, dessen Zahlzeichen aus Ziffern besteht, deren jeweiliger Beitrag zum Gesamtwert der Zahl von ihrer Position innerhalb des Zahlzeichens abhängt.
Basis, Stelle und Stellenwert
- Basis: Anzahl der Zahlensymbole (2, 8, 10, 16)
- Stelle/Position: Platz einer Ziffer in einer Reihe, gelesen von rechts nach links, beginnend mit 0
- ____ entspricht Stelle3Stelle2Stelle1Stelle0
- Stellenwert: entspricht einer Potenz der Basis
- Wertigkeit = BasisStelle
Binär-/Dualsystem
Blickt man in östlicher Richtung aus dem Fenster des ersten Stocks am LRZ, sieht man eine kunstvoll angelegte Gartenarchitektur, die schon einen tiefere Sicht in das Wesen des Digitalen andeudet: Das binäre Zahlensystem (Zeichenvorrat besteht aus 0 und 1 = Basis 2), dargestellt in Form von Baumreihen (Stellen 0 bis 9 eines Stellenwertsystems) und Stangen mit Ziffern (Basis hoch Stelle = Potenzen der Basis 2). Daraus ergibt sich die Wertigkeit an den Stellen von 0 bis 9: 1 - 2 - 4 - 8 - 16 - 32 - 64 - 128 - 256 - 512.

LRZ: Digitale Kunst
| Wert | Potenz | Stelle |
| 512 | 29 | 9 |
| 256 | 28 | 8 |
| 128 | 27 | 7 |
| 64 | 26 | 6 |
| 32 | 25 | 5 |
| 16 | 24 | 4 |
| 8 | 23 | 3 |
| 4 | 22 | 2 |
| 2 | 21 | 1 |
| 1 | 20 | 0 |
Begriffe der Datenverarbeitung
- Bit - binary digit - Binärzahl
- Byte - binary word - Binärwort, Datenwort
| 4-Bit-Datenwort | binäre Folge aus 4 Bit (Quartett) | Halbbyte | 4-Bit-Architektur |
| 8-Bit-Datenwort | binäre Folge aus 8 Bit (Oktett) | Byte | 8-Bit-Architektur |
| 16-Bit-Datenwort | 2 Byte | Word | 16-Bit-Architektur |
| 32-Bit-Datenwort | 4 Byte | Double Word | 32-Bit-Architektur |
| 64-Bit-Datenwort | 8 Byte | Long Word | 64-Bit-Architektur |
Überblick: 4-Bit-Datenwort (Halbbyte) im Binärsystem mit Umrechnung in das Dezimal- und Hexadezimalsystem
| Hexadezimal | Binär/Dual | Dezimal |
| 0 | 0 0 0 0 | 00 |
| 1 | 0 0 0 1 | 01 |
| 2 | 0 0 1 0 | 02 |
| 3 | 0 0 1 1 | 03 |
| 4 | 0 1 0 0 | 04 |
| 5 | 0 1 0 1 | 05 |
| 6 | 0 1 1 0 | 06 |
| 7 | 0 1 1 1 | 07 |
| 8 | 1 0 0 0 | 08 |
| 9 | 1 0 0 1 | 09 |
| A | 1 0 1 0 | 10 |
| B | 1 0 1 1 | 11 |
| C | 1 1 0 0 | 12 |
| D | 1 1 0 1 | 13 |
| E | 1 1 1 0 | 14 |
| F | 1 1 1 1 | 15 |
Mit einem Halbbyte lassen sich insgesamt 16 Zahlen darstellen, nämlich binär von 0000 bis 1111 = dezimal von 0 bis 15 = hexadezimal von 0 bis F.
Mit einem Byte lassen sich insgesamt 256 Zahlen darstellen, nämlich binär von 00000000 bis 11111111 = dezimal von 0 bis 255 = hexadezimal von 00 bis FF.
2.2. Digitalisierung - eine systematisch-methodische Annäherung
Wikipedia, Artikel Digitalisierung
Unter Digitalisierung (von lateinisch digitus ‚Finger‘ und englisch digit ‚Ziffer‘) versteht man die Umwandlung von analogen, d. h. stufenlos darstellbaren Werten bzw. das Erfassen von Informationen über physische Objekte in Formate, welche sich zu einer Verarbeitung oder Speicherung in digitaltechnischen Systemen eignen. Die Information wird hierbei in ein digitales Signal umgewandelt, das nur aus diskreten Werten besteht.
Digitalisierungsmodell: Lücke, S.: s.v. “Digitalisierung”, in: VerbaAlpina-de 20/1 (Erstellt: 16/1, letzte Änderung: 16/2), Methodologie, https://doi.org/10.5282/verba-alpina?urlappend=%3Fpage_id%3D493%26db%3D201%26letter%3DD%2315
Digitalisierung im engeren Sinn: Eine analoge Vorlage wird in ein digitales Signal überführt. Der Computer kann diese digitalen Signale speichern und verarbeiten und daraus wiederum ein analog erscheinendes Abbild (Digitalisat) erzeugen (visualisieren).
Digitalisierung im weiteren Sinn umfasst auch die Tiefenerschließung, Annotation (Tagging) nach bestimmten Theorien und mit bestimmten Methoden. Die Beschreibung der Wirklichkeit von einem bestimmten Standpunkt aus fliesst in die Daten mit ein.
Genauer gesagt: Digitalisierung meint die Abbildung der Wirklichkeit in Zahlenkodes und darauf aufbauend die Abbildung/Modellierung einer Sicht auf einen Ausschnitt der Wirklichkeit in Datenstrukturen höherer Ordnung.
3. Digitale Abbildung
Zum Gegenstand der Philologie gehören ganz allgemein Schriften, Sprachen und Literaturen, die in den Disziplinen Editions-, Sprach- und Literaturwissenschaft behandelt werden. Die Vielfalt und Komplexität der Gegenstände, Fragestellungen und Methoden haben wir in den Veranstaltungen der Ringvorlesung kennengelenrt.
Auf der anderen Seite haben wir Computer, die nur mit Zahlen rechnen bzw. mit Signalzuständen umgehen können. Den binären Zahlenwerten 0 und 1 entsprechen dabei die Signalzustände High-Pegel und Low-Pegel, Strom und Nicht-Strom.
Wie lassen sich also zunächst Schriftzeichen und darauf aufbauend Wörter, Wortverbindungen, Sätze, Satzverbindungen, Texte oder gar textliche Makrostrukturen in Zahlen und logischen Strukturen darstellen/abbilden?
3.1. Schriftzeichen
Im Laufe der 1950er und 1960er Jahre liefen im wesentlichen drei Technologien zusammen, die dazu führten, dass Computer nicht nur mit Zahlen rechnen, sondern auch mit Schrift rechnen und damit Text verarbeiten konnten:
- Rechentechnologien (Tabelliermaschine, Lochkartentechnik, zunächst mit symbolischer Kodierung, dann Zahlen, später alphanumerische Zeichen)
- Fernkommunikationstechnologien (Signalübertragung, Schreibtelegraph mit Morse-Code, Fernschreiber mit Baudot-Murray-Code)
- Schreibtechnologien (Schreibmaschine)
Diese gingen ein in die sog. elektronische Datenverarbeitung mit Hilfe von Computer-, Transitor- und Digitaltechnik. An den Entwicklungen waren maßgeblich beteiligt:
- Tabulating Machine Company (Herman Hollerith) und International Business Machines Corporation (IBM)
- Remington Typewriter Company und Remington Rand
- American Telephone and Telegraph Company (AT&T) und Bell Laboratories (Claude Shannon)
Die Kodierung der Schriftzeichen erfolgte nach einem einfachen Prinzip: Jedem Zeichen wurde ein eindeutiger Zahlenwert zugeordnet.
3.1.1. ASCII - American Standard Code for Information Interchange
- siehe Wikipedia, Artikel ASCII
- erstmals als Standard eingeführt am 17.06.1963, letzte Aktualisierung 1968
- Zeichenvorrat:
- druckbare Zeichen: lateinisches Alphabet, arabische Ziffern, Interpunktions- und Sonderzeichen
- nicht druckbare Steuerzeichen: Funktionen von Schreibmaschine und Fernschreiber
- 7-Bit-Zeichenkodierung (< 5-Bit-Baudot-Murray-Code), achtes Bit als Prüfbit bei Kommunikationsleitungen
- 27 = 128 Zeichen (Code-Points 0-127)
- Grundlage für
- Sortierung
- Reguläre Ausdrücke (vs. Arithmetische Ausdrücke): Spezifizierung von Zeichenklassen (z.B.: [0-9] oder [A-Z] oder [a-z]), Zeichenmuster
Zeichen für Strukturierung der Daten (Separatoren)
- Zeichen zur Trennung von Wörtern: SPACE (0x20)
- Zeichen zur Trennung von Spalten: TAB (0x09)
- Zeichen zur Trennung von Zeilen: CR (0x0D) und LF (0x0A)
Schreibmaschine: Wagenrücklauf (Carriage Return) und Zeilenvorschub (Line Feed)

Schreibmaschine: Grundposition
MS Word: Digitales Abbild
MS Word: Grundposition
MS Word: Dokument "Speichern unter" im Format "Nur Text" (txt-Format)
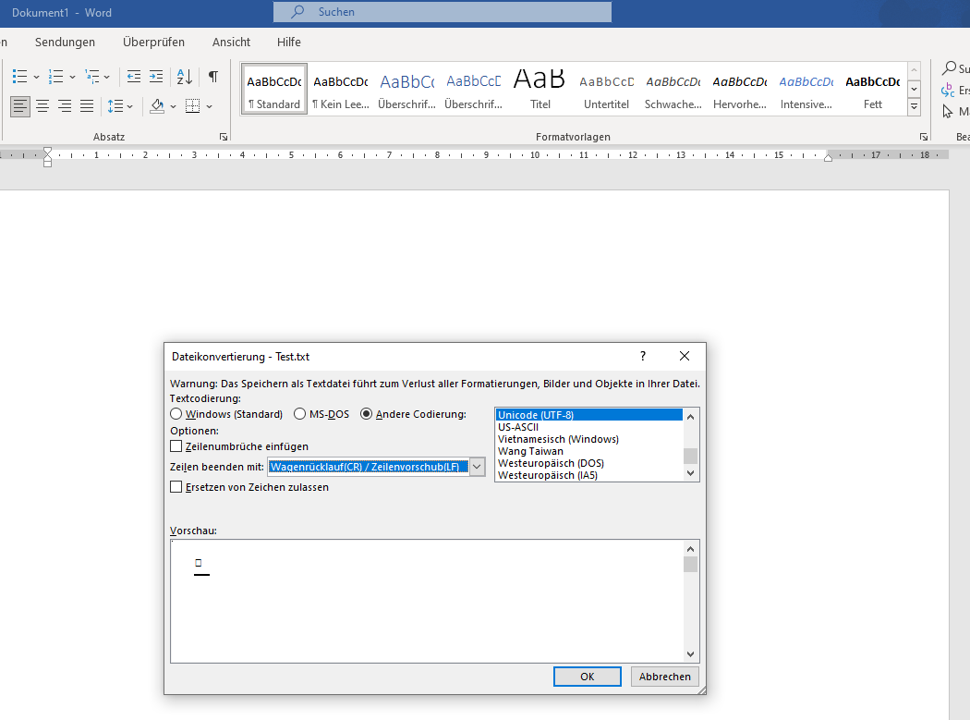
MS Word: Speichern als txt-Format
Busa, Watson und der Index Thomisticus (Masoner 2018):
- Roberto Busa (Pontificias Universitas Gregoriana), 1913-2011: La Terminologia Tomistica dell'interiorità, 1946
- Thomas J. Watson (IBM), 1874-1956
- 1949: Erstes Treffen in New York, Anliegen wird von Ingenieuren geprüft und für unmöglich gehalten
- IBM-Werbebroschüre: "The difficult we do right away, the impossible takes a little longer"
- 1958: IBM-Präsentation auf der Weltausstellung in Brüssel (Rechnen nicht nur mit Zahlen)
- Das Projekt fällt in die Entwicklungszeit von Zeichenkodierungen (Buchstaben im Englischen und Lateinischen identisch):
-
- EBCDIC - Extended Binary Coded Decimal Interchange Code (IBM, Großrechner) < 80-Zeichen-Lochkartenkodierung (8-Bit)
- ASCII (7-Bit)
-
- Website: Index Thomisticus
- Literatur:
-
- Anna Masoner, Ein Jesuitenpater als Computerpionier (Masoner 2018)
- Roberto Busa, The Annals of Humanities Computing: The Index Thomisticus (Busa 1980)
- Kurt Gärtner, Die Anfänge der Digital Humanities (Gärtner 2016)
-
3.1.2. Erweiterung des Zahlenraums I: 8-Bit-Kodierung
- Abbildung weiterer Schriftzeichen erforderlich
- nationale 7-Bit-Varianten: Inkombatibilität
- 8-Bit-Zeichenkodierung (1 Zeichen entspricht 1 Byte)
- 28 = 256 Zeichen (Positionen 128-256)
- Kompatible Zeichenkodierungen: ISO 8859 mit Varianten von ISO 8859-1 bis ISO 8859-16
3.1.3. Erweiterung des Zahlenraums II: UNICODE
Wikipedia, Artikel Unicode (15.08.2018)
Unicode [... ] ist ein internationaler Standard, in dem langfristig für jedes Sinn tragende Schriftzeichen oder Textelement aller bekannten Schriftkulturen und Zeichensysteme ein digitaler Code festgelegt wird. Ziel ist es, die Verwendung unterschiedlicher und inkompatibler Kodierungen in verschiedenen Ländern oder Kulturkreisen zu beseitigen. Unicode wird ständig um Zeichen weiterer Schriftsysteme ergänzt.
32-Bit-Kodierung (4 Byte)
- Erweiterung des Zahlenraums auf theoretisch 4.294.967.296 Codepunkte/Zeichen
- zur Verfügung steht der Bereich (U+0000 bis U+10FFFF) für theoretisch 1.114.111 Codepunkte/Zeichen, tatsächlich verwendet werden können 1.111.998 Codepunkte
- technische Umsetzung: UTF-8 (variable Verwendung von 1 bis 4 Byte, platzsparend)
- Programme und Anwendungen müssen multi-byte-safe sein
- The Unicode Consortium Members
- 1991 Veröffentlichung des Unicode-Standards, Unicode-Version 1.0
- 1996 als ISO 10646 angenommen
The Unicode Standard -> Unicode Code Charts
- Scripts
- Symbols and Punctuation: u.a. Musical Symbols, Ancient Greek Musical Notation, Byzantine Musical Symbols, Znamenny Musical Notation
3.1.4. Betacode
Problem: Wenn man nur ASCII-Zeichen zur Dateneingabe zur Verfügung hat, wie bildet man dann Schriftzeichen ab, die nicht in ASCII enthalten sind?
Betacode: Transliteration von Schriftzeichen (z.B. des Griechischen und Hebräischen) in Zeichen des 7-Bit ASCII-Code (1 Byte ASCII-Code)
Betacode für die griechische Schrift: Thesaurus Lingua Graece (TLG)
Betacode für die hebräische Schrift: Biblia Hebraica Stuttgartensia (BHS)/Michigan-Claremont-Text -> Westminster Leningrad Codex (WLC)
Coding for Transliteration of Hebrew, Greek, Coptic for CCAT/CATSS/TLG materials
3.1.5. Zeichenkodierung und Zeichensatz
Zeichenkodierung bedeutet die eindeutige Zuordnung von Zeichen zu einem Zahlenwert. Die Zuordnung muß bekannt sein.
Zeichensatz meint ein Inventar von Zeichen, aus denen sich Zeichenketten bilden lassen. Im Grunde ist hier eigentlich im typografischen Sinn Satzschrift bzw. Schriftart (font) gemeint, die grafische Gestaltung einzelner Zeichen (Glyphe).
Es gilt also zu unterscheiden:
- abstrakte Idee eines Zeichens: "Latin Capital Letter D"
- Kodierung, eindeutige Zuordnung eines Zeichens zu einem Zeichencode (Zahl): dezimal 68
- Schriftart (mit Schrifttyp und Schriftgröße), grafische Repräsentation eines Zeichens in einer Glyphe:
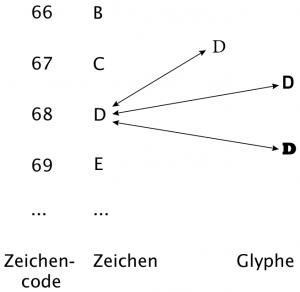
Zeichencode - Zeichen - Glyphe (aus Jannidis 2017, S. 63)
3.2. Transliterationen und Transkriptionen
Bei der Wiedergabe von Texten haben sich wissenschaftlich standardisierte Metazeichensysteme bewährt. In der Hebraistik wurden sie methodologisch grundgelegt von Wolfgang Richter in "Transliteration und Transkription. Objekt- und metasprachliche Metazeichensysteme zur Wiedergabe hebräischer Texte" (Richter 1983). Sie dienen ganz allgemein dazu, "das Verständnis, das der Einzelne vom Text hat, einsichtig darzustellen" (siehe Richter 1983, S. 1).
Unter Transliteration versteht man die Übertragung von einem Schriftsystem in ein anderes, unter Transkription die Wiedergabe von Sprache in der Schrift. Bezugsgröße ist also zunächst eine Objektsprache. (siehe Richter 1983, S. 12)
Wiedergabe der Objektsprache in Metazeichensystemen
- Transliteration
-
- der orthographischen Systeme mit Hilfe zusätzlicher Editionszeichen (z.B. Worttrenner, Zeilengrenzen, Sicherheit der Lesung, undeutbare Zeichenreste, usw.)
- der orthographischen Systeme mit Hilfe zusätzlicher Interpretationszeichen (z.B. Lesart, Konjektur, Struktur des Textes, Grenzzeichen für Morpheme, Silben, Sätze, Kola)
-
- Transkription
-
- der orthographischen Systeme
- der Aussprache (Phonetik)
- der phonologischen Struktur
- morphologischen und syntaktischen Struktur
-
Wiedergabe der Struktur der Objektsprache in metasprachlichen Zeichensystemen
- metasprachliche morphologisch-syntaktische Transkription (Grammatik)
- metasprachliche semantische Transkription (Semantik)
Transliterieren bzw. Transkribieren der Objektsprache bzw. der Struktur der Objektsprache lassen sich hervorragend in einen digitalen Abildungsprozess integrieren. Dies kann manuell, halbautomatisch oder automatisch erfolgen. Wichtig dabei ist, dass man die Daten nicht graphisch strukturiert, sondern logisch, und durch eindeutige Notation bzw. Annotation maschinenlesbare Datenstrukturen verwendet, um seine Urteile explizit darzustellen. Die Möglichkeiten reichen hier von einfachen strukturierten Textdateien und Tabellen über einfache Auszeichnungsstrukturen wie z.B. Markdown bis hin zu komplex geschachtelten Baumstrukturen gängiger Auszeichnungssprachen wie z.B. XML (eXtensible Markup Language). Ziel der Strukturierung ist jeweils die maschinelle Weiterverarbeitung der Daten.
3.3. Datenstrukturen
Die Projekte BHt (Biblia Hebraica transcripta) und DAHPN (Database 'Ancient Hebrew Personal Names') mögen uns im Folgenden als Beispiele dienen.
3.3.1. Text bzw. Objektsprache
Textgrundlage: Biblia Hebraica Stuttgartensia

BHS, 1990 (4): Titelseite

BHS, 1990 (4): Gen 1
BHt: Orthographiebezogene morphologisch-syntaktische Transkription in txt-Format
Gen 1 & 1P3a %b.=r$e%(@)$si%t & PR %bar$a%(@) %@$I%l$o%*h$i%m %@$A%t %ha=$s%amaym %w.=@$A%t %ha=@ar$v & 2a %w.=ha=@ar$v %hay$A%t$a %tuhw %wa=buhw & b %w.=$h%u$s%k $c%al %p$A%n$e %t$I%h$o%m & c %w.=r$uh %@$I%l$o%*h$i%m %m.ra$h%[$h%]$I%pt $c%al %p$A%n$e %ha=maym & 3a %wa=y$o%(@)mir %@$I%l$o%*h$i%m & b %y$I%hy %@$o%r & c %wa=y$I%hy %@$o%r
- eindeutige und logische Strukturierung der Textdaten
- 1. Zeile: Überschrift mit Buch und Kapitel
- 1 Satz pro Zeile, gemäß der theoretischen Annahme: "Ein Satz hat nur ein Prädikat."
- Tabelle mit 2 Spalten (Spaltenseparator=TAB; Zeilenseparator=LineFeed): Stelle mit Vers Satz TAB Text NewLine
- Segmentierung von Tokens durch Leerzeichen, = und LineFeed
- Zeichen im Betacode (2-Byte: Steuerzeichen &, % und $ + Zeichen)
BHt Forschungsdatenbank 3.0: Visualisierung des transkribierten Textes Gen 1
BHS: 1:1 Transliteration des orthographischen Systems (Editionstransliteration) in txt-Format, in der zweiten Hälfte der 1980er Jahre als Software bereitgestellt von J. Alan Groves (Parunak/Whitaker/Groves 1987).
~a"MT"b"001"c"Gen"x1 B.:/R")$I73YT B.FRF74) ):ELOHI92YM )"71T HA/$.FMA73YIM W:/)"71T HF/)F75REC00 ~x1y2 W:/HF/)F81REC? HFY:TF71H TO33HW.03 WF/BO80HW. W:/XO73$EK: (AL-P.:N"74Y T:HO92WM W:/R74W.XA ):ELOHI80YM M:RAXE73PET (AL-P.:N"71Y? HA/M.F75YIM00 ~x1y3 WA/Y.O71)MER ):ELOHI73YM Y:HI74Y )O92WR WA75/Y:HIY-)O75WR00
DAHPN: Visualisierung der transliterierten hebräischen Kontextform der Personennamen
Geeignete Datenstrukturen für die elektronische Erfassung von Texten (z.B. in Transkriptionen der Objektsprache) können demnach eindeutig und logisch strukturierte Textdateien sein. Eindeutige und einheitliche Strukturen lassen sich automatisch in andere Strukturen überführen, z.B. in Tabellenformate. Anhand von regelhaften Merkmalen, ansprechbar durch sog. Reguläre Ausdrücke, lassen sich ausserdem bereits auf dieser Ebene zusätzliche Daten errechnen, wie z.B. eine Satzzählung.
BHt: Textauszug aus der Datenbank, ergänzt um Zeilennummer, Bezug, Fragment, Satznummer und Satzelementnummer, ferner Steuerzeichen
z_nr|buch|kap|vers|satz|bezug|frag|s_nr|se_nr|text ----+----+---+----+----+-----+----+----+-----+------------------------------------------------------------------------------------- 1 |Gen |1 |1 |P |3a |0 |1 |1 |%b%.%=%r$e%(%@%)$s$i%t 2 |Gen |1 |1 |PR | |0 |1 |2 |%b%a%r$a%(%@%) %@$I%l$o%*%h$i%m %@$A%t %h%a%=$s%a%m%a%y%m %w%.%=%@$A%t %h%a%=%@%a%r$v 3 |Gen |1 |2 |a | |0 |2 |0 |%w%.%=%h%a%=%@%a%r$v %h%a%y$A%t$a %t%u%h%w %w%a%=%b%u%h%w 4 |Gen |1 |2 |b | |0 |3 |0 |%w%.%=$h%u$s%k $c%a%l %p$A%n$e %t$I%h$o%m 5 |Gen |1 |2 |c | |0 |4 |0 |%w%.%=%r$u$h %@$I%l$o%*%h$i%m %m%.%r%a$h%[$h%]$I%p%t $c%a%l %p$A%n$e %h%a%=%m%a%y%m 6 |Gen |1 |3 |a | |0 |1 |3 |%w%a%=%y$o%(%@%)%m%i%r %@$I%l$o%*%h$i%m 7 |Gen |1 |3 |b | |0 |5 |0 |%y$I%h%y %@$o%r 8 |Gen |1 |3 |c | |0 |6 |0 |%w%a%=%y$I%h%y %@$o%r
Ein strukturierter Text kann Ausgangspunkt für weitere Analysen der Tiefenstruktur der Sprache auf unterschiedlichen Ebenen sein. Nach dem ebenenspezifischen Grammatikmodell von Wolfgang Richter sind dies die Ebenen Wort, Wortfügung, Satz und Satzfügung. Hier geht es um die oben erwähnte Wiedergabe der Struktur der Objektsprache in metasprachlichen Zeichensystemen. In der Regel geht man in der Korpuslinguistik von einer tokenisierten Wortliste (in Form einer Tabelle, bestehend aus Referenzsystem und Tokens) aus und annotiert manuell aufgrund regelhafter Merkmale der sprachlichen Oberfläche weitere grammatische Werte (z.B. lexikalische und grammatische Morpheme, Wortarten) oder lässt die grammatische Analyse ein Programm durchführen, wie z.B. den treetagger, einem sehr bekannten part-of-speech-Tagger (Wortartzuordnung, Lemmatisierung), oder man nutzt das NLTK-Paket von PYTHON, oder wie im Projekt BHt: Die hebräische Grammatik wird in Programme überführt, die auf die Daten angewendet werden.
Bei der digitalen Abbildung auf der Grundlage eines relationales Datenmodells entspricht je eine Analyseebene je einer Tabelle in der Datenbank. Eine Tabelle repäsentiert jeweils eine Menge von Entitäten mit jeweils gleichen Eigenschaften: Token, Wort, Wortverbindung, Satz, Satzverbindung.
3.3.2. Wortebene
Morphologie und SALOMO
Die grammatischen Regeln der Morphologie (und nur diese, ohne weitere lexikalische Informationen) wurden zunächst in das Programm SALOMO - Searching Algorithm On MOrphology übertragen. Als Programmiersprache wurde PASCAL verwendet. Das Programm ist dokumentiert bei (Eckardt 1987). Es handelt sich im Wesentlichen um einen Vergleichsalgorithmus, der grammatische Informationen in Grammatikdateien vergleicht mit den in Texten enthaltenen Wörtern und für jedes Wort eine Nominal- und Verbalanalyse vorschlägt. Die Wörter werden dabei zugleich tokenisiert. Durch die kontextfreie Analyse kommen für jedes Wort mehrere morphologische Deutungen zustande, die der Experte an einer Benutzerschnittstelle (MOLEX) entscheiden muss. Im Laufe der Bearbeitung (Wort für Wort und Zeile für Zeile) entsteht ein morphologisches Lexikon in Form einer tabellarischen Tokenliste mit den zusätzlichen morphologischen Daten.

Richter 1978, ATS 8: Morphologie

Eckardt 1987, ATS 29: SALOMO
BHt: Automatische Analyse mit SALOMO und Entscheidung des Experten
SALOMO V3.0 File: gen1.rno
Salomos Analysevorschlaege
Gen 1,1P3a
(1) %b%.%=%r$e%(%@%)$s$i%t& Nomen Verb
Praep. %b$.=& Praep. %b$.=&
Rumpf: %r%i%@$s& Mit GRM-File
f s a f s c nicht erfasst
Basis: %R%@$S&
NF: qitl
Wz. nicht gef.
Kritz.: 1
-- oder --
Rumpf: %r%i%@$s&
f s a f s c
Basis: %R%@$S&
NF: qitl
i-Suffix
Wz. nicht gef.
Kritz.: 1
Gen 1,1PR
(1) %b%a%r$a%(%@%)& Nomen Verb
Rumpf: %b%a%r%a%@& Rumpf: %b%a%r%a%@&
m s a m s c 3. m sg SK Stamm: G
Basis: %B%R%@& Basis: %B%R%@&
NF: qatal Wz. nicht gef.
Wz. nicht gef. Kritz.: 1
Kritz.: 1
Ablage in der Datenbank (Tabelle beleg)
Bei BHt sind die Ergebnisse der morphologischen Analyse in der Datenbanktabelle beleg gespeichert. Hier ein kleiner Ausschnitt von 11 Datensätzen aus der insgesamt 54-spaltigen Tabelle:

Eine geeignete Datenstruktur für die Abbildung von Daten der morphologischen Analyse kann also eine Tabelle sein, die die einzelnen Tokens durch ein Referenzsystem in der Tabelle (und zugleich im Text) identifiziert und die grammatischen Kategorien in jeweils einer Spalte abbildet.
BHt Forschungsdatenbank 3.0: Visualisierung der morphologischen Analyse Gen 1,1PR.0 (5)
Experimente bei BHt (Stefanie Schneider): Statistisch-linguistische Analyse alttestamentlicher Textkorpora, Bachelorarbeit, Ludwig-Maximilians-Universität München: (Schneider 2016b).
3.3.3. Wortfügungsebene
Morphosyntax und AMOS
Die grammatischen Regeln der Morphosyntax (und wiederum nur diese) wurden in einfachen Formeln notiert und in sog. Hornklauseln (Formeln mit einer oder mehreren Bedingungen und einer Folgerung daraus) übersetzt. Für das auf diese Weise entstandene Logikprogramm boten sich zwei Auswertungsstrategien an: Entweder die Top-down Auswertung, bei der die Horn Klauseln nach entsprechender Transformation als PROLOG-Programm abgearbeitet wurden, oder die mengenorientierte, am relationalen Datenmodell anknüpfende Bottom-up Auswertung, bei der die Horn Klauseln automatisch in ein Programm der relationalen Algebra, implementiert in einem erweiterten LISP, übersetzt wurden. Umfangreiche Tests beider Varianten wiesen die nach der Bottom-up Strategie verfahrende deduktive Datenbanktechnik als die weit effizientere aus, da "eine ganze Menge zu einer Zeit" ableitbar ist und vorhandene Linksrekursionen und quadratische Rekursionen automatisch auflösbar sind.
Das Programm AMOS - A MOrphosyntactical ExpertSystem ist dokumentiert bei (Specht 1990). In der Informatik war die Entwicklung von Logikprogrammen und sog. deduktiver Datenbanken eingebettet in den Rahmen der AI-Forschung der späten 1980er Jahre: Aus Fakten und Regeln sollte neues Wissen abgeleitet werden.

Richter 1979, ATS 10: Morphosyntax

Specht 1990, ATS 35: AMOS
AMOS baut auf die Ergebnisse von SALOMO auf, aber nur ein Teil der morphologischen Daten bildet die Faktenbasis, nämlich Stelle, Wortart und grammatische Morpheme:
( PRAEP "Gen1,1P:3a.0" 1 "%b%." ) ( SUB "Gen1,1P:3a.0" 2 "%r$e%(%@%)$s$i%t" C F S 0 ) ( VB "Gen1,1PR.0" 1 "%b%a%r$a%(%@%)" 3 M S SK G ) ( SUB "Gen1,1PR.0" 2:x "%@$I%l$o%*%h$i%m" A M P 0 ) ( PRAEP "Gen1,1PR.0" 3 "%@$A%t" ) ( ATK "Gen1,1PR.0" 4 "%h%a" ) ( SUB "Gen1,1PR.0" 5 "$s%a%m%a%y%m" A M D 0 ) ( KONJ "Gen1,1PR.0" 6 "%w%." ) ( PRAEP "Gen1,1PR.0" 7 "%@$A%t" ) ( ATK "Gen1,1PR.0" 8 "%h%a" ) ( SUB "Gen1,1PR.0" 9 "%@%a%r$v" A M S 0 )
Formelnotation
| Sub/abs/ |
AtkV := Atk + { EN/abs/ }
| Adj/abs/ |
| Ptz/abs/ |
| DPron |
| Num |
Hornklauseln
atkv(Satz, Von, Bis, Worte, Status, Genus, Numerus, det,
atkv(atk(W1),sub(W2))) <-
atk(Satz, Von, Pos, W1)
sub(Satz, Pos, Bis, W2, Status, Genus, Numerus, _)
concat(W1, W2, Worte).
atkv(Satz, Von, Bis, Worte, abs, Status, Genus, Numerus, Determ,
atkv(atk(W1),S_EN)) <-
atk(Satz, Von, Pos, W1)
sub(Satz, Pos, Bis, W2, Status, Genus, Numerus, Determ, S_EN)
concat(W1, W2, Worte).
atkv(Satz, Von, Bis, Worte, Status, Genus, Numerus, det,
atkv(atk(W1),adj(W2))) <-
atk(Satz, Von, Pos, W1)
sub(Satz, Pos, Bis, W2, Status, Genus, Numerus)
concat(W1, W2, Worte).
atkv(Satz, Von, Bis, Worte, abs, Genus, Numerus, det,
atkv(atk(W1),ptz(W2))) <-
atk(Satz, Von, Pos, W1)
sub(Satz, Pos, Bis, W2, _, Genus, Numerus, _)
concat(W1, W2, Worte).
atkv(Satz, Von, Bis, Worte, abs, Genus, Numerus, det,
atkv(atk(W1),dpron(W2))) <-
atk(Satz, Von, Pos, W1)
sub(Satz, Pos, Bis, W2, Genus, Numerus)
concat(W1, W2, Worte).
atkv(Satz, Von, Bis, Worte, Status, Genus, Numerus, det,
atkv(atk(W1),num(W2))) <-
atk(Satz, Von, Pos, W1)
sub(Satz, Pos, Bis, W2, Status, Genus, Numerus, _, _)
concat(W1, W2, Worte).
Ergebnis in Baumstruktur
(
("Gen1,1P:3a.0" 0 2
(PV (PRAEP "%b%.")
(NOM (SUB "%r$e%(%@%)$s$i%t"))))
("Gen1,1PR.0" 2 5
(PV (PRAEP "%@$A%t")
(ATKV (ATK "%h%a") (SUB "$s%a%m%a%y%m"))))
("Gen1,1PR.0" 6 9
(PV (PRAEP "%@$A%t")
(ATKV (ATK "%h%a") (SUB "%@%a%r$v"))))
("Gen1,2a.0" 1 3 (ATKV (ATK "%h%a") (SUB "%@%a%r$v")))
("Gen1,2b.0" 2 5
(PV/R (PRAEP "$c%a%l")
(CSV (SUB "%p$A%n$e") (NOM (SUB "%t$I%h$o%m")))))
("Gen1,2c.0" 1 3X (CSV (SUB "%r$u$h") (NOM (SUB "%@$I%l$o%h$i%m"))))
("Gen1,2c.0" 4 8
(PV/R (PRAEP "$c%a%l")
(CSV (SUB "%p$A%n$e")
(ATKV (ATK "%h%a") (SUB "%m%a%y%m"))))
("Gen1,3a.0" 0 2 (KONJV (KONJ "%w%a%=") (VB/PK/ "%y$o%(%@%)%m%i%r")))
("Gen1,3c.0" 0 2 (KONJV (KONJ "%w%a%=") (VB/PKK/ "%y$I%h%y")))
)
Auch auf Wortfügungsebene ergeben sich durch die kontextfreie Analyse für jede Wortverbindung mehrere morphosyntaktische Deutungen, die der Experte an einer Benutzerschnittstelle entscheiden muss.
Alle Analysergebnisse werden in einer Klammernotation in Form von Baumstrukturen als String in der Datenbanktabelle wv gespeichert. Hier ein Ausschnitt von 9 Datensätzen:
Ebenso sind die von AMOS berechneten Varianten in der Datenbanktabelle wvvar abgelegt und werden über die Benutzerschnittstelle visualisiert. Ein besonders schönes Beispiel ist Koh 1,1:
BHt Forschungsdatenbank 3.0: Visualisierung der morphosyntaktischen Analyse Koh 1,1x.0 (0 7)
Kooperation mit Informatik: AMOS

IBM Deutschland GmbH: Anwendungsbrief Nr. 54, 1989
Kooperation mit Informatik: Venona

Argenton: Venona, 1998
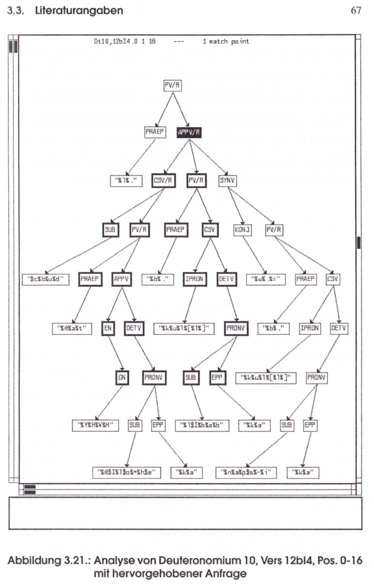
Argenton: Venona, Baumsuche in Dt 10,12bI4 0-16
Die Entwicklung des Retrievalsystems Venona war Gegenstand der 1997 angenommenen Dissertation von Hans Argenton (Argenton 1998). Damit konnten erstmals komplexe Baumstrukturen nach Teilbäumen abgesucht werden. Im Laufe der Arbeit gelang die Erweiterung um Feature-Formalismen, die komplexe Attribuierungen von Baumknoten zuließen und sehr gut für die Abbildung der syntaktischen Analyse geeignet gewesen wären (Beispiel Feature-Strukturen). Zeitlich relativ parallel (Februar 1998) wurde XML veröffentlicht.
Kooperation mit Informatik: MultiBHT

Specht, Zirkel: Multimap/2
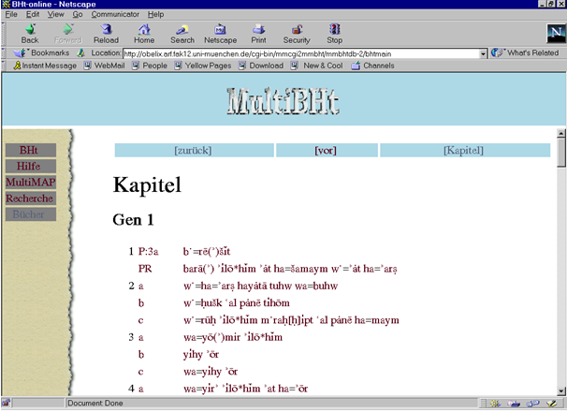
Website mit Datenbank: MultiBHT
Das Projekt BHt war im DFN-geförderten Projekt "MultiMAP/2 - Netzzugang und Netzbetrieb für das muldimediale Datenbanksystem MulitMAP" (siehe Specht/Zirkel 1999) von 1996 bis 1998 Teil der Entwicklung von multimedialen, datenbankgestützten Webanwendungen. Eine erste Webapplikation MultiBHT präsentierte Text- und Analysedaten mehrerer sprachlicher Ebenen und stellte Such- und Kommentarfunktionen bereit. Damit war erstmals ein Online-Zugang nicht nur zu den transkribierten Texten, sondern zugleich - auch durch die User kommentierbar - ein Lexikon mit Satzkonkordanz geschaffen.
Experimente bei BHt (Tschugnall/Specht/Riepl 2016): Methoden der intrinsischen Plagiatserkennung zur literaturwissenschaftlichen Auswertung
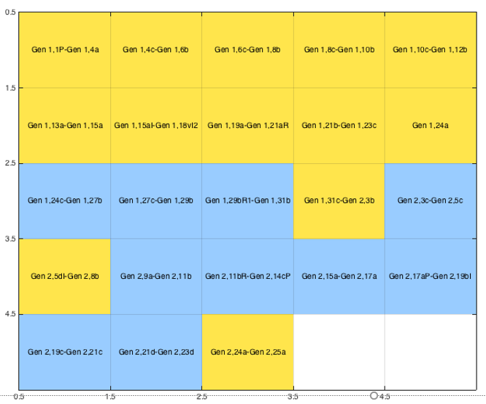
Tschugnall: Versuch 1 Literarkritik Gen 1-2
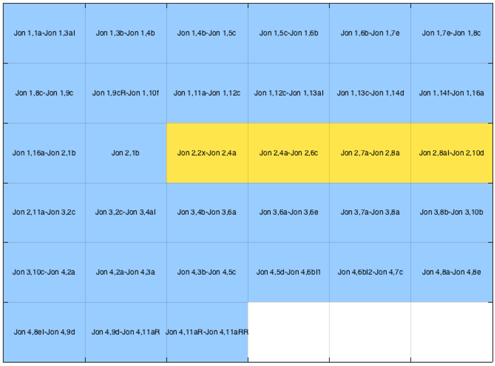
Tschugnall: Versuch 2 Literarkritik Jon 1-4
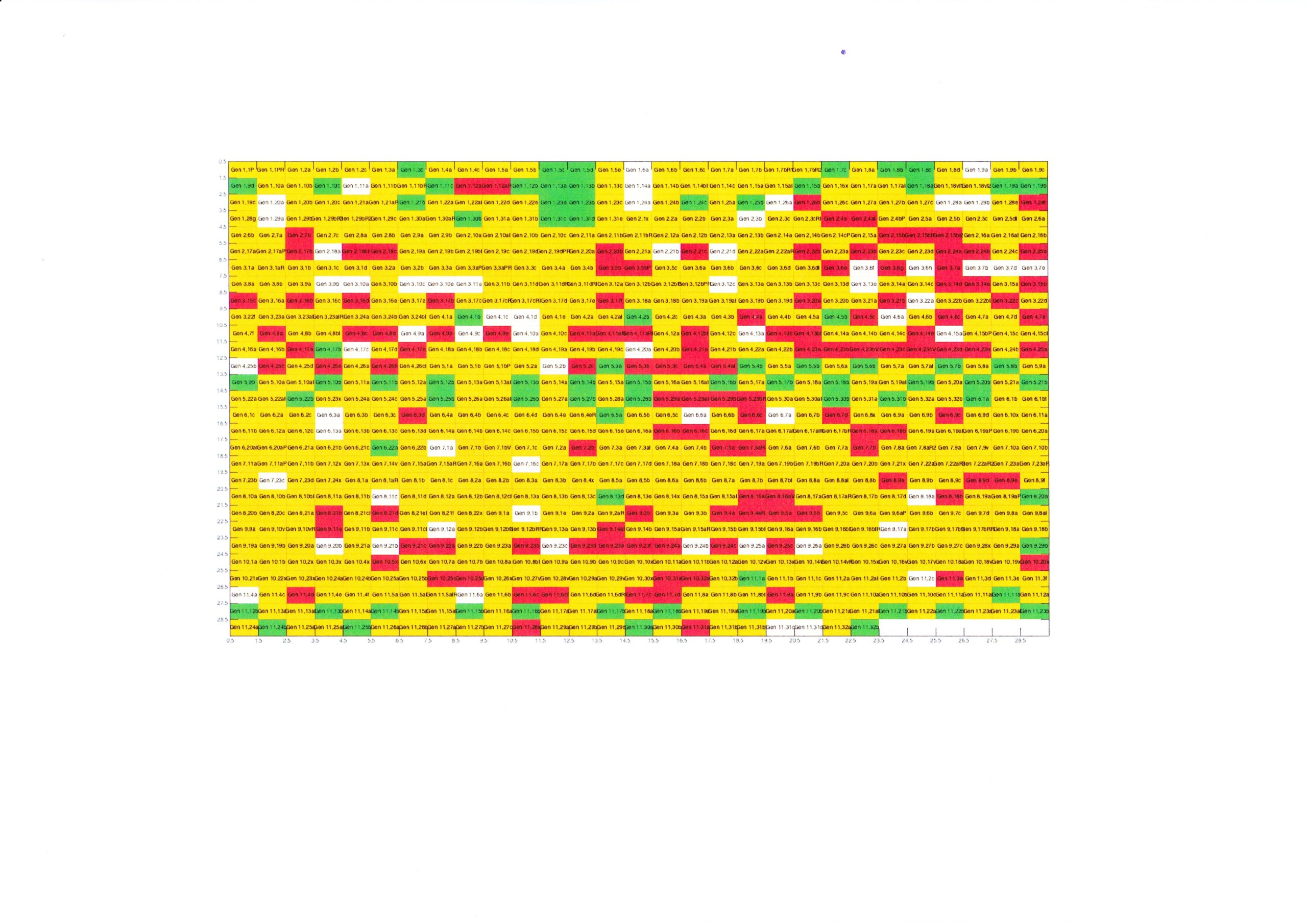
Tschugnall: Versuch 3 Literarkritik Gen 1-11
Experimente bei BHt (David Englmeier mit Teilnehmern am Bonusprojekt "Informationsvisualisierung" im Wintersemester 2019/2020): Visualisierung morphosyntaktischer Analysen
SALOMO und AMOS sind "Expertensysteme"
Bei den Programmen SALOMO und AMOS handelt es sich um sog. Expertensysteme. Die Analyse erfolgt regelbasiert und liefert alle Ergebnisse, die auf Grund der Regeln berechnet werden. Die Ergebnisse können eindeutig sein, oder oft auch mehrdeutig. Eine endgültige Entscheidung für oder gegen ein Ergebnis (gar verbunden mit einer Handlungsanweisung-/ausführung) trifft die Software nicht. Eine Entscheidung, welches Ergebnis im Einzelfall zutrifft, also "richtig" oder "wahrscheinlich" ist, trifft der Experte, der anhand der Kriterien der nächsthöheren Analyseebenen und/oder lexikalischer Kriterien und/oder seines allgemeinen Inhaltswissens eine wohlbegründete Auswahl trifft. Die Entscheidung ist transparent.
3.3.4. Satz- und Satzfügungsebene, Personennamen
Satzebene
An die Arbeiten mit AMOS schloss sich Mitte der 1990er der Versuch an, die Analyse von sog. Kernsätzen nach Teil 3 der Grundlagen einer althebräischen Grammatik (Richter 1980) mit einer erweiterten AMOS-Technik (XAmos) durchzuführen. U.a. wegen der Komplexität der bisher entstandenen Wissensbasis und der Regeln der Syntax gelang dies mit den zur Verfügung stehenden Ressourcen nicht. In langwieriger halbautomatischer Handarbeit konnte Wolfgang Richter nach seiner Emeritierung 1995 bis zu seinem Tod im Jahr 2015, unterstützt von Theo Seidl (Würzburg) und Hans Rechenmacher (Würzburg), die Satzanalysen abschliessen. Nur ein kleiner Teil des Psalmenbuches konnte von Richter nicht mehr Korrektur gelesen werden.

Richter 1980, ATS 13: Satztheorie

Heumel: XAmos
Neben (Richter 1980) bildeten die Arbeiten von Walter Groß zum Satzanfang (Groß 1987) die theoretische Grundlage der Analysen. Bei der halbautomatischen Vorgehensweise wurden zunächst die vorhandenen und für die Syntax relevanten Grunddaten von Morphologie und Morphosyntax aus der Datenbank extrahiert und in einem 10-zeiligen Schema um die weiteren Kategorien ergänzt:
1: Stelle [Stamm-Basis] (von bis) Tokens mit Intervallen (aus DB) 2: Satzart, Satzbauplan, Kernsatzerweiterungen/Partikel (Art/Anzahl, ausgedrückt/getilgt) 3: Syntagmen und Position 4: Syntagmarelationen, semantische Funktionen und Kernseme 5: = 3: Tiefenstruktur 6: = 4: Tiefenstruktur 7: Satzhafte, den Kernsatz erweiternde Elemente (Vokativ, Interjektion) 8: Partikel: Subklassen und Position 9: Partikel: Funktion 10: Kommentar ~
Die Analyseergebnisse wurden in die (noch experimentelle) Datenbanktabelle satzanalyse_in eingelesen. Hier ein kleiner Auszug:
BHt Forschungsdatenbank 3.0: Visualisierung der syntaktischen Analyse Gen 1,3a.0 (0 3)
Satzfügungsebene
Die Beschreibung von sog. Großsatzformen hat im Wesentlichen Hubert Irsigler seit 1977 vorangetrieben. Auf (Irsigler 1977) folgten eine Reihe von Publikationen, die die Großsatzformen schießlich differenzierten je nach Art der Ersparungskonstruktion in "Erweiterter Satz (ES)", "Satzbund (SB)" und "Satzgefüge (SG)", sodann in "Satzreihe", "Satzparallele" und "Satzzuordnung" falls syntaktische Gleichrangigkeit bei ES und SB vorliegt. Ein D-A-CH-Antrag von Thomas Hieke (Mainz), Hans Rechenmacher (Würzburg), Christian Riepl (München) und Günther Specht (Innsbruck), um das Regelwerk genauer und formaler zu fassen und auch mit Mitteln der AI auf die sehr umfangreichen und komplexen Daten anzuwenden, war im Jahr 2018 leider nicht erfolgreich.
Personennamen
Auf den Datenbestand von BHt aufbauend wurden in den Jahren 2015 bis 2021 die onomastischen Forschungen im Rahmen eines DFG-Projektes von Hans Rechenmacher (Würzburg) und Victor Golinets (Heidelberg) mit Beteiligung der ITG weitergeführt. Die Daten wurden strukturiert eingegeben und relational modelliert. Wo erforderlich, wurde eine projektinterne Notation für die Auszeichnung von z.B. Schriftarten und Links verwendet. Die Ergebnisse sind veröffentlicht im Webportal DAHPN - Database 'Ancient Hebrew Personal Names'. Ein Folgeprojekt "Datenbankmodul 'Nordwestsemitische Personennamen in Babylonien'" wurde von Annemarie Frank (München) bei der DFG beantragt.
3.4. Tools und Datenbanksysteme
Seit dem Einsetzen der Förderung der Digital Humanities, die etwa mit der Gründung des Verbandes DHd - digital dumanities im deutschsprachigen Raum im Jahr 2013 einhergeht, sind eine Vielzahl von Tools, die bei der Digitalisierung, Strukturierung, Analyse und Visualisierung von Daten helfen, entstanden. Ferner sind Erfahrungen aus der Forschung in die Gestaltung der DH-Curricula eingeflossen und haben sich in BA- und MA-Studiengängen bewährt. Einen ersten Überblick über Methoden, Ressourcen und Tools bietet die Website forText.
An der ITG hat sich zur Transliteration/Transkription, Annotation und Edition historischer Dokumente das System Squirrel bewährt. Mit Squirrel können historische, meist handschriftliche Dokumente transliteriert/transkribiert und mit editions- und dokumentspezifischen Tags annotiert werden. Ferner ist die Auszeichnung sog. Named Entities (Personennamen, Ortsnamen, Zeitangaben) möglich. Mit Squirrel lässt sich außerdem ein Bildausschnitt mit einem transliterierten/transkribierten Wort verknüpfen. Durch einen im Hintergrund ablaufenden Algorithmus unterstützt Squirrel die Deutung schwer lesbarer Handschriften durch Vorschläge. Die entstehenden Daten werden in einer relationalen Datenbank abgelegt und zugleich mit XML-Tags versehen. Dadurch lassen sich die Daten einerseits als XML-Dokumente nach den Standards der Editionswissenschaften bereitstellen, andererseits stehen eine Fülle weiterer Verarbeitungs-, Auswertungs- und Visualisierungsmöglichkeiten zur Verfügung.
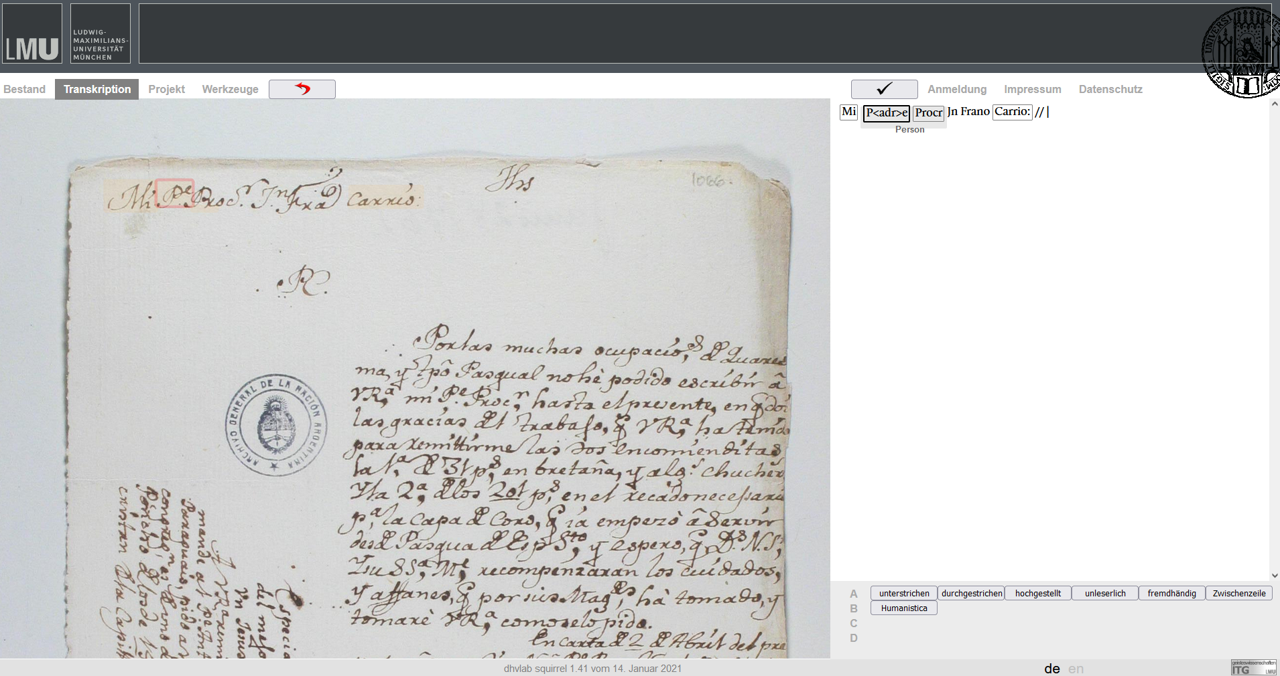
Gerhard Schön: Squirrel
Die Squirrel-Technologie fand u.a. Anwendung in den Projekten Briefedition Leopold Wilhelm und Geld-Kunst-Netz. In Kooperation der Abteilung "Geschichte der frühen Neuzeit" (Mark Hengerer) mit dem CIS (Maximilian Hadersbeck) und der ITG (Gerhard Schön) wurde Squirrel ferner in die von Maximilian Hadersbeck und seinem Team am CIS entwickelte Suchmaschinentechnologie WiTTFind integriert und für historische Anwendungen als HistoFind bereitgestellt.
Im Bereich der Zeichenerkennung (Optical Character Recognition) bei Handschriften und Drucken haben sich mittlerweile die Programme bzw. Systeme tessarect, transkribus und OCR4all durchgesetzt.
Im Bereich der Programmierung bietet die Programmiersprache PYTHON schier ungeahnte Möglichkeiten. Je nach Bedarf und Anforderung kann PYTHON um weitere optionale Programmpakete u.a. zur Entwicklung von webbasierten Anwendungen, GUIs oder zur Datenanalyse und -visualisierung erweitert werden.
Im Bereich der Datenbanksysteme werden neben den klassischen relationalen Datenbanksystemen (SQL) insbesondere bei Big-Data-Anwendungen der data sciences sog. NoSQL-Datenbanksysteme verwendet. Davon sind in den Digital Humanities beliebt sog. Document Stores wie z.B. MongoDB oder Graphdatenbanken wie z.B. Neo4j oder XML-Datenbanken wie z.B. eXist.
Die an der ITG realisierten Systeme basieren in der Regel auf einer einheitlichen Client-Server-Architektur mit einer MySQL-Datenbank im Backend und einer webbasierten Oberfläche im Frontend, der meist das CMS WordPress zugrundeliegt.
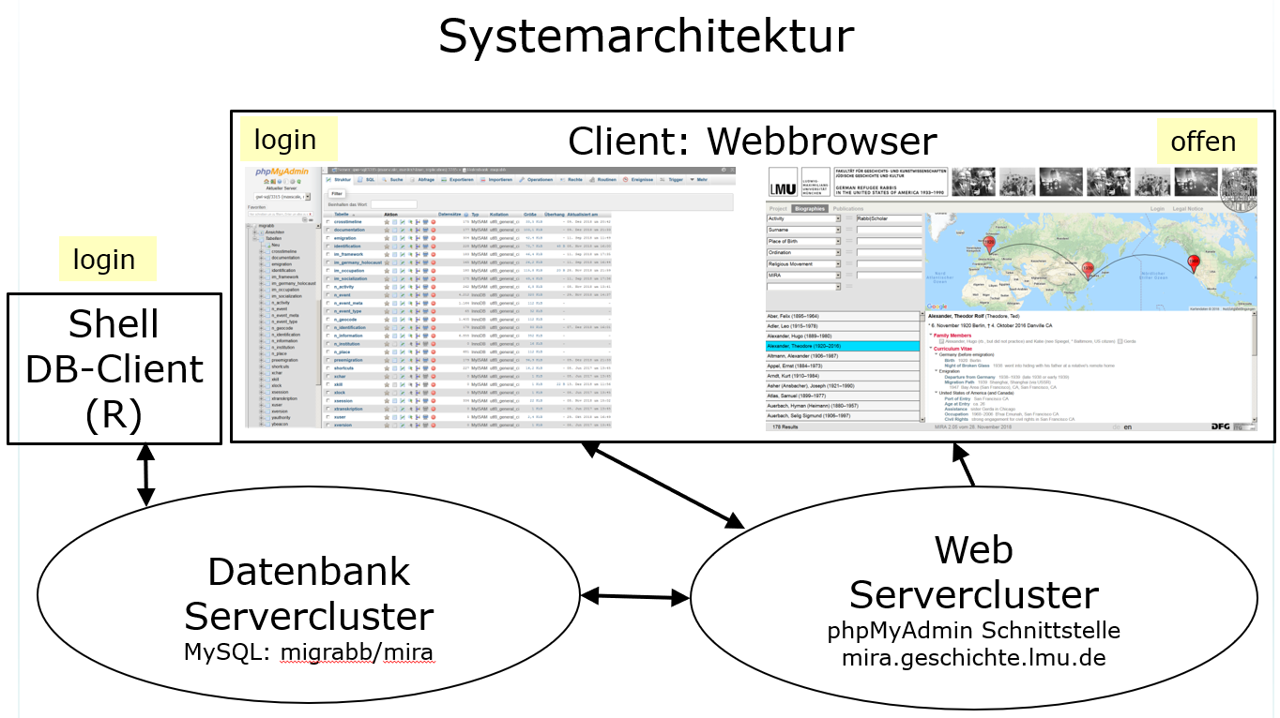
ITG: Systemarchitektur Webanwendungen
3.5. Digialisierung, Interdisziplinarität und Nachhaltigkeit
Die Frage der Nachhaltigkeit von Forschungssoftware und Forschungsdaten sowie deren interdisziplinärer Wiederverwendbarkeit beschäftigt die ITG schon seit vielen Jahren beim Betrieb der IT-Infrastruktur wie auch bei der Konzeption und Beantragung von Drittmittelprojekten. Eine einheitliche Strukturierung der Daten und ihre systematisch geordnete Ablage auf geeigneten Servern war immer schon Grundlage jeder Empfehlung für eine langfristige Erhaltung der Daten.
Digitalisierung fördert Teamarbeit und Interdisziplinarität
Interdisziplinarität
Eine weitere Idee kam etwa um das Jahr 2013 auf: Wie können Daten aus den an der ITG vorhandenen Datenbanken verschiedener Disziplinen in einer Art Metadatenbank verknüpft werden? - Leider war damals der Antrag "MetaDB1.0 – Entwicklung einer interdisziplinären Metadatenbank zur integrativen Erschließung strukturierter Forschungsdaten geisteswissenschaftlicher Disziplinen" auf Fördermittel aus dem LMUExcellent Investitionsfonds nicht erfolgreich. Die Fragen aber blieben:
Wie liessen sich literarische Motive des Alten Testaments wie z.B. Am 9,11a "die zerfallene Hütte Davids" in kunsthistorischen Datenbeständen finden?

Kunstgeschichte: Artigo
Wie liesse sich die Rezeption literarischer Themen und Werke wie z.B. Texte aus den Psalmen und dem Hohelied in musikwissenschaftlichen Datenbeständen nachweisen?
Musikwissenschaft: BMLO
Liesse sich der Bedeutungsgehalt fester Wendungen wie z.B. Ps 8,7b "... alles hast du unter seine Füße gelegt ..." mit einer Referenz auf ägyptologische Datenbestände aus der Bilderwelt Ägyptens erklären?

Ägyptologie: Mudira
4. Forschungsdatenmanagement
Die ITG ist seit 5 Jahren Teil des Modellvorhabens Forschungsdatenmanagement Bayern und kooperiert im Projekt eHumanities interdisziplinär sehr eng mit den Universitätsbibliotheken der FAU Nürnberg und der LMU München. An der LMU ist daraus die Servicestelle FDM-DH - Forschungsdatenmanagement für Digitale Geisteswissenschaften hervorgegangen. In einer Kooperationsvereinbarung zwischen ITG und UB der LMU sind die jeweils angebotenen Basisdienste und erweiterten Dienste beschrieben. Sie umfassen die Vorbereitung, Antragstellung und Durchführung von Projekten wie auch die Aufbereitung und Überführung der Forschungsdaten in ein institutionalisiertes Forschungsdatenrepositorium.
Bei den Forschungsdaten ist darauf zu achten, dass sie den FAIR-Prinzipien entsprechen, also auf nachhaltige Weise Findable (auffindbar), Accessible (verfügbar), Interoperable (interoperabel, im Sinne von maschinenlesbar und austauschbar) und Reusable (wiederverwendbar) sind. Forschungsdaten werden in der Regel mit der Creative Commons Lizenz CC-BY-SA veröffentlicht. Sie erhalten eine standardisierte Beschreibung mit formalen Metadaten im DataCite-Format. Sie können weiter durch inhaltliche und ontologische Metadaten angereichert und klassifiziert werden. Die Granularität ist dabei abhängig von den Anforderungen des Forschungsprojekts. Die Zuweisung persistenter Identifikatoren (u.a. DOIs), die Verwendung von Normdaten (wie z.B. der GND oder der Wikidata QID) und ihre Verknüpfung auch mit Hilfe von RDF-Tripeln (Aussagen mit Subjekt+Prädikat+Objekt) führen schliesslich zur Bildung eines semantischen Netzes (Semantic Web) über weltweite Datenbestände (Linked Open Data).
Das DFG-Langzeitprojekt VerbaAlpina (Thomas Krefeld und Stephan Lücke) hat auch auf dem Gebiet des Forschungsdatenmanagements und der Nachhaltigkeit Pionierarbeit geleistet und wiederum andere Projekte an der ITG beeinflußt. VerbaAlpina ist vollständig digital konzipiert und erfüllt in jeder Hinsicht die FAIR-Prinzipien. Sämtliche Software- und Datenversionen (Rohdaten, Lexikon, Methodologie, Beiträge) sind versioniert und damit dauerhaft zitierbar. Für den maschinellen Datenaustausch existieren APIs. Die streng strukturierten und mit Normdaten versehenen Daten werden regelmäßig in sehr hoher Granularität in das Forschungsdatenrepositorium der UB der LMU (Open Data LMU) eingespeist und sind u.a. über den neuen FDM-Dienst der UB der LMU Discover auffindbar.
Die am Projekt eHumanities interdisziplinär beteiligten Einrichtungen wirken als Partner der NFDI-Konsortien NFDI4Culture, NFDI4Memory und Text+ am Aufbau der NFDI - Nationale Forschungsdateninfrastruktur mit.
Vielleicht wird das oben erwähnte Verknüpfen von Datenbeständen und das Suchen von Forschungsdaten über wissenschaftliche Disziplinen und Domänen hinweg mit den Mitteln der in den NFDI-Konsortien zu erarbeitenden Standards in Zukunft möglich sein.
Von 13. bis 17. Februar 2023 findet die Aktionswoche zum liebevollen Umgang mit Daten statt: Love Data Week 2023 (FDM-Bayern) und Love Data Week 2023 (forschungsdaten.info).
5. Digitales Publizieren und digitales Lehren
5.1. KiT - Korpus im Text
Digital konzipiert ist auch die Publikationsplattform KiT - Korpus im Text. Innovatives Publizieren im Umfeld der Korpuslinguistik, mit der die Herausgeber (Thomas Krefeld, Stephan Lücke, Christian Riepl) seit 2015 alle Möglichkeiten des genuin digitalen Publizierens ausprobieren und Erfahrungen sammeln möchten.
Ein besonderes Augenmerk liegt dabei nicht nur auf der Vielfalt der darstellbaren Medien (Karte, Bild, Video, Audio), sondern auch auf den vielfältigen Verknüpfungsmöglichkeiten im Netz, allem voran aber der Möglichkeit, Belege aus einem digitalen Textkorpus direkt in die Argumentation einzubinden, indem Daten und deren Auswertungen aus den jeweiligen Projektdatenbanken abgefragt werden.
Beispiel: Anzahl und prozentualer Anteil der Wortartklassen im Buch Gen:
Beispiel: Anzahl und prozentualer Anteil der Haupt- und Funktionswortarten im Buch Gen:
Veröffentlicht werden können unter "Bände" umfangreichere Monographien, unter "Artikel" kürzere Beiträge. Alle Publikationen sind versioniert, wodurch die Zitierung älterer Versionen nicht verlorengeht. Die Seitenzählung ist aufgegeben und durch eine Paragraphenreferenzierung ersetzt worden. Es kann also exakt ein bestimmter Paragraph einer bestimmten Version einer Publikation referenziert werden.
Beispiel mit Referenz auf den gesamten Beitrag:
Schließlich kann über die Kommentarfunktion jeder Beitrag kommentiert werden.
Während also die Publikation in Papierform ein read-only-Prozess ist, eröffnet sich mit Hilfe der Webtechnologie eine digitale und vernetzte Publikationsform mit read-write-execute-Prozessen.
5.2. DHVLab - Digital Humanities Virtual Laboratory
Die digitale Lehr- und Forschungsumgebung für die Geisteswissenschaften ist erreichbar unter (Registrierung für ein Labor erforderlich): https://dhvlab.gwi.uni-muenchen.de/
5.3. Studi.DH - Service- und Beratungsstelle
Studi.DH ist eine Service- und Beratungsstelle für studentische Forschungsprojekte in den Digital Humanities (Fakultäten 13, 09 und 12).
Digitale Unterstützung bietet die Webplattform Studi.DH (Login mit LMU-Kennung): https://www.studidh.gwi.uni-muenchen.de/
Bibliographie
- Argenton 1998 = Argenton, Hans (1998): Indexierung und Retrieval von Feature-Bäumen am Beispiel der linguistischen Analyse von Textkorpora, in: DISBIS, vol. 40, St. Augustin, infix Verlag [Dissertation Universität Tübingen].
- Busa 1980 = Busa, Roberto (1980): The Annals of Humanities Computing: The Index Thomisticus, in: Computers and the Humanities, vol. 14, North-Holland Publishing Company, 83-90 (Link).
- Eckardt 1987 = Eckardt, Walter (1987): Computergestützte Analyse althebräischer Texte. Algorithmische Erkennung der Morphologie., in: ATSAT, vol. 29, St. Ottilien, EOS Verlag.
- Gärtner 2016 = Gärtner, Kurt (2016): Die Anfänge der Digital Humanities, in: Schwerpunkt Digital Humanities. Mehr als Geisteswissenschaften mit anderen Mitteln. Akademie Aktuell., vol. 56, München, Zeitschrift der Bayerischen Akademie der Wissenschaften, S. 18-23 (Link).
- Groß 1987 = Groß, Walter (1987): Die Pendenskonstruktion im Biblischen Hebräisch, in: ATSAT, vol. 27, St. Ottilien, EOS Verlag.
- Irsigler 1977 = Irsigler, Hubert (1977): Gottesgericht und Jahwetag. Die Komposition Zef. 1,1-2,3, untersucht auf der Grundlage der Literarkritik des Zefanjabuches, in: ATSAT, vol. 3, St. Ottilien, EOS Verlag.
- Jannidis u.a. 2017a = Jannidis, Fotis / Kohle, Hubertus / Rehbein, Malte (2017): Digital Humanities. Eine Einführung, Stuttgart (Link).
- Kluge u.a. 1989 = Kluge, Friedrich / Bürgisser, Max / Gregor, Bernd / Seebold, Elmar (221989): Etymologisches Wörterbuch der deutschen Sprache, Berlin, New York, Walter de Gruyter [22. Auflage völlig neu bearbeitet von Elmar Seebold].
- Masoner 2018 = Masoner, Anna (2018): Ein Jesuitenpater als Computerpionier, Wien, Österreichischer Rundfunk, Ö1-Wissenschaft [Veröffentlicht am 02.04.2018] (Link).
- Parunak/Whitaker/Groves 1987 = Parunak, H. van Dyke / Whitaker, Richard E. / Groves, J. Alan (1987): Michigan-Claremont BHS, Philadelphia.
- Richter 1978 = Richter, Wolfgang (1978): Grundlagen einer althebräischen Grammatik. A. Grundfragen einer sprachwissenschaftlichen Grammatik. B. Die Beschreibungsebenen: I. Das Wort (Morphologie), in: ATSAT, vol. 8, St. Ottilien, EOS Verlag.
- Richter 1979 = Richter, Wolfgang (1979): Grundlagen einer althebräischen Grammatik. B. Die Beschreibungsebenen: II. Die Wortfügung (Morphosyntax), in: ATSAT, vol. 10, St. Ottilien, EOS Verlag.
- Richter 1980 = Richter, Wolfgang (1980): Grundlagen einer althebräischen Grammatik. B. Die Beschreibungsebenen: III. Der Satz (Satztheorie), in: ATSAT, vol. 13, St. Ottilien, EOS Verlag.
- Richter 1983 = Richter, Wolfgang (1983): Transliteration und Transkription. Objekt- und metasprachliche Metazeichensysteme zur Wiedergabe hebräischer Texte., in: ATSAT, vol. 19, St. Ottilien, EOS Verlag.
- Schneider 2016b = Schneider, Stefanie (2016): Statistisch-linguistische Analyse alttestamentlicher Textkorpora (Link).
- Specht 1990 = Specht, Günther (1990): Wissensbasierte Analyse althebräischer Morphosyntax. Das Expertensystem AMOS., in: ATSAT, vol. 35, St. Ottilien, EOS Verlag.
- Specht/Zirkel 1999 = Specht, Günther / Zirkel, Martin (1999): MultiMAP/2: Netzzugang und Netzbetrieb fuer das multimediale Datenbanksystem MultiMAP, vol. TUM-I9920, München, Technische Universtität München [Technical Report] (Link).
- Tschugnall/Specht/Riepl 2016 = Tschugnall, Michael / Specht, Günther / Riepl, Christian (2016): Algorithmisch unterstützte Literarkritik. Eine grammatikalishe Analyse zur Bestimmung von Schreibstilen, in: ATSAT, vol. 100, St. Ottilien, EOS Verlag, 415-428 [In Memoriam Wolfgang Richter, Hg. v. Hans Rechenmacher].