Die Edition von Texten kann auch unter Einsatz einer relationalen Datenbank erfolgen. Das Wesen einer relationalen Datenbank besteht darin, dass Gegenstände in Gestalt von Tabellen abgebildet werden. Jede Zeile einer Tabelle nimmt dabei einen Repräsentanten einer Objektgruppe auf, die sich über eine spezifische Art und Anzahl von Eigenschaften (= Attribute) definiert. Die Eigenschaften o. Attribute werden durch die Spalten einer Tabelle repräsentiert. So könnte z.B. die Objektgruppe "Fahrzeuge" folgendermaßen in Tabellenform abgebildet werden:
| Fahrzeug-ID | Art | Farbe | Anzahl_Raeder | motorisiert | Kennzeichen |
| 1 | LKW | schwarz | 6 | ja | F-AB 1234 |
| 2 | PKW | grau | 4 | ja | M-CD 5678 |
| 3 | Fahrrad | rot | 2 | nein | - |
Jeder Eintrag in eine Tabelle muss immer eindeutig zugeordnet werden können. Um dies zu gewährleisten werden Keys oder zu Deutsch Schlüssel verwendet. Im Beispiel stellt die Spalte "Fahrzeug-ID" den Primärschlüssel der Tabelle dar. Ein Schlüssel kann sich auch aus mehreren Spalten zusammensetzen.
Eine relationale Datenbank besteht meist aus mehreren Tabellen (Relationen), die miteinander verbunden sind. Um Tabellen miteinander zu verknüpfen, dienen nun die Primärschlüssel der einen Tabelle als Fremdschlüssel in der Anderen. Mit dem obigen Beispiel (Relation "Fahrzeuge") könnte etwa eine Relation "Mitfahrer" verknüpft werden, um anzugeben, welche Personen in einem Fahrzeug fahren.
Demnach muss zunächst mit einer weiteren Tabelle die Relation "Person" modelliert werden:
| Person-ID | Vorname | Nachname | Adresse |
| 1 | Peter | Mueller | Vogelgasse 27 |
| 2 | Henriette | Obermeier | Adenauerstraße 72 |
| 3 | Claudia | Kunze | Mühlfeldstraße 19 |
Um nun die Tabelle "Mitfahrer" darzustellen, wird eine dritte Tabelle benötigt, die jeder Fahrzeug-ID eine Person-ID zuweist:
| Fahrzeug-ID | Person-ID |
| 1 | 1 |
| 1 | 2 |
| 2 | 3 |
Die Tabelle "Mitfahrer" gibt demnach an, dass im ersten Wagen die Personen Peter Mueller (1,1) und Henriette Obermeier (1,2) sitzen, während im zweiten Auto Claudia Kunze (2,3) alleine fährt.
Da beide Spalten in dieser Tabelle von anderen Tabellen stammen, bezeichnet man sie als Fremdschlüssel oder foreign keys. Der Primärschlüssel der Tabelle "Mitfahrer" setzt sich somit aus den beiden Fremdschlüsseln "Fahrzeug-ID" und "Person-ID" zusammen.
Wenn "Mitfahrer" noch um ein Attribut "Datum" erweitert werden würde, es also festgehalten würde, wann welche Person in einem bestimmten Auto sitzt, kann es passieren, dass der Schlüssel aus "Fahrzeug-ID" und "Person-ID" Einträge nicht mehr eindeutig identifizieren kann:
| Fahrzeug-ID | Person-ID | Datum |
| 1 | 1 | 2017-07-01 |
| 1 | 2 | 2017-07-01 |
| 2 | 3 | 2017-07-01 |
| 1 | 1 | 2017-07-02 |
Da Peter Mueller nun nochmals mit dem ersten Wagen gefahren ist, müsste sich der Primärschlüssel nun aus allen drei Spalten zusammensetzen oder es würde ein weiteres Attribut "Mitfahrer-ID" eingeführt, das eindeutig anzeigt, welche Person wann in welchem Wagen saß:
| Mitfahrer-ID | Fahrzeug-ID | Person-ID | Datum |
| 1 | 1 | 1 | 2017-07-01 |
| 2 | 1 | 2 | 2017-07-01 |
| 3 | 2 | 3 | 2017-07-01 |
| 4 | 1 | 1 | 2017-07-02 |
Als Relations-Diagramm skizziert sähe die Datenbank so aus:
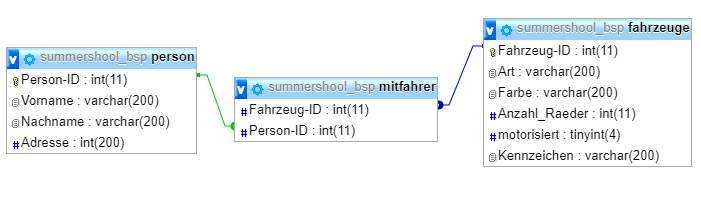
/var/cache/html/dhlehre/html/wp content/uploads/2017/08/1504534303 Summerschool2017 bsp uml
0.1. Aufbau der relationalen Datenbank
Dieses hier kurz skizzierte Verfahren soll nun auf die Edition eines Briefes des Erzherzogs Leopold Wilhelm von Österreich (1614-1662) angewendet werden, den dieser am 6. April 1657 an seine Schwester Maria Anna (1610-1665), seit 1635 Gemahlin des Bayerischen Kurfürsten Maximilians I., schrieb.
 Von David Teniers der Jüngere - 1. bilddatenbank.khm.at2. gallerix.ru, Gemeinfrei, https://commons.wikimedia.org/w/index.php?curid=4602141 - Archduke Leopold Wilhelm of Austria by David Teniers d. J. 1650s |
 /var/cache/html/dhlehre/html/wp content/uploads/2017/08/1502455775 Joachim von Sandrart Erzherzogin Maria Anna 1610 1665 Kurfurstin von Bayern |
Die entsprechende Prozedur beginnt mit der Anfertigung eines Scans:

/var/cache/html/dhlehre/html/wp content/uploads/2017/08/1502446863 Leopold wilhelm scan
Anschließend erfolgt die manuelle Transkription des Textes in Gestalt eines elektronischen Fließtextes:
Durchleuchtigste Churfürstin freundlich vielgeliebte Frau schwester // mit der letzten Post habe ich E.L. khürzlich parte geben von Ihr M saling // unzeitigen hintritt; und weilen in dem ganzen laidt khein gressre consolation // hat, als von der persohn, welche man lieb hat gehabt, ausfierlich als // perichten. habe ich es hiermit thun wollen. die gehabte unpeslichkhait // Ihro K.M. saling und die greilichen vomitio welche sie gehabt haben, in // dem sie ein schwarze gal, mit grünlichem schleim continue geprochen // haben, ist E.L. schon pekhant. welchs sie also abgewartett hatt, das // sie von tag zue tag seindt schwecher worden. am heiligen sambstag // in dem wir die greber besuechten, ließ es sich zue einer pesserung an // als wir zue den capucinern khamen, war aldort der pater guardian mit // namen Pater Gregori. ein heiliger man, welchen vielleicht E.L. khenen mechten. er // ist vor viel jaren zue Passau gewesen. dieser sagt mir khlar // das er selben morgen wie ein oculation gehabt habe. das, wen ihr // M# selben tag noch nit mitt unsern Herrn versehen und ihre dispositiones // machen werden, den anderen tag sie nit mehr desselben werden perichten // khinen. und er gespiers nun sie werden, und die handt darob zue halten. // ich hab die profecei an sein ort lassen gesteldt sein, doch alspald
Die Transkription kann nur von einem Experten durchgeführt werden und stellt bereits eine Stufe der Interpretation dar. Die automatische Texterkennung mittels OCR (optical character recognition) ist aufgrund der nicht standardkonformen Kursive (noch?) nicht möglich. Eine ganze Reihe von Informationen, die in der analogen Vorlage vorhanden sind, wie etwa das X-förmige Kreuz am oberen Blattrand oder die kleine "2" am unteren sind ebenso verloren wie Eigenschaften des Papiers (Farbe, Größe, etc.).
0.1.1. Schritt 1: Anlegen der Tabelle `objects`
Bevor der transkribierte Text in die Datenbank eingelesen wird, soll in einem ersten Schritt eine Tabelle angelegt werden, die die Metadaten des Briefes, bzw. auch die Metadaten aller anderen Dokumente, die ediert werden sollen, beinhaltet. Der Name dieser Tabelle lautet `objects`.
Die Tabelle soll folgende Spalten beinhalten:
- Id (Int) => Identifier für jeden Datensatz in der Tabelle, Primärschlüssel der Tabelle
- Absender (Varchar 200) => Name des Absenders, wenn Dokument ein Brief
- Empfänger (Varchar 200) => Name des Empfängers, wenn Dokument ein Brief
- Datum (Date) => Datum, an dem das Dokument verfasst wurde
- Ort (Varchar 200) => Ort, an dem das Dokument verfasst wurde
- Beschreibstoff (ENUM) => Auswahl des Materials
Das Anlegen der Tabelle lässt sich entweder direkt per SQL-Anweisung durchführen:
DROP TABLE IF EXISTS objects;
CREATE TABLE objects (
id INT NOT NULL PRIMARY KEY AUTO_INCREMENT,
absender VARCHAR(200),
empfaenger VARCHAR(200),
datum DATE,
ort VARCHAR(200),
beschreibstoff ENUM('Papier','Papyrus','Pergament')
) DEFAULT CHARACTER SET utf8 COLLATE utf8_general_ci;
Oder die Tabelle wird mit Hilfe, des dafür vorhandenen Interfaces von phpMyAdmin angelegt:
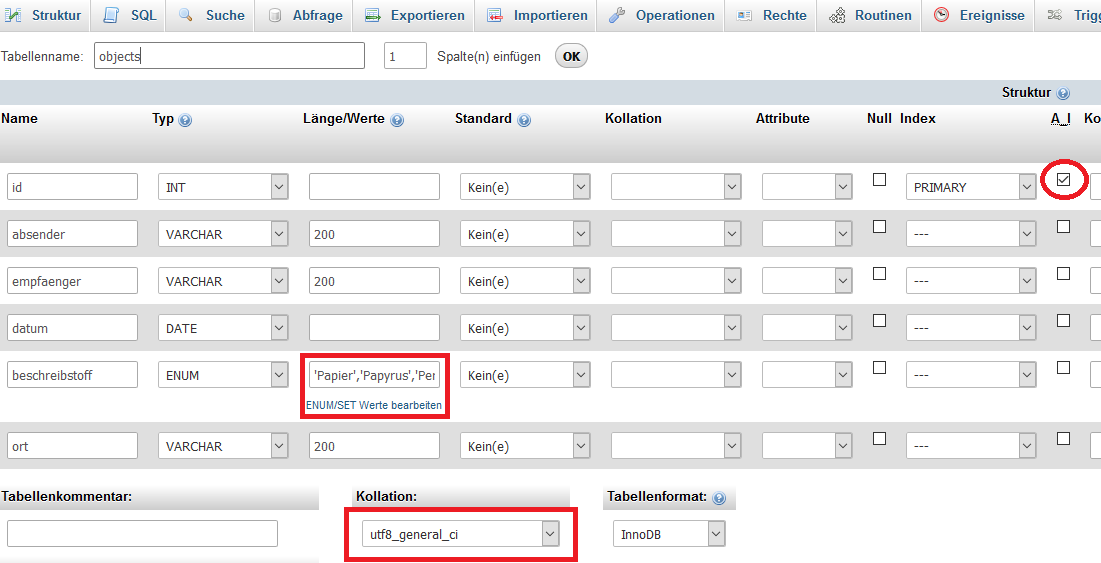
/var/cache/html/dhlehre/html/wp content/uploads/2017/08/1504625121 Summerschool 2017 create table
Um einen Datensatz hinzuzufügen kann in SQL folgender Befehl gegeben werden:
INSERT INTO objects (absender,empfaenger,datum,ort,beschreibstoff)
VALUES ("Leopold Wilhelm von Österreich","Maria Anna von Österreich","1657-04-06","Wien",
"Papier");
Alternativ kann gleichermaßen auch phpMyAdmin genutzt werden:
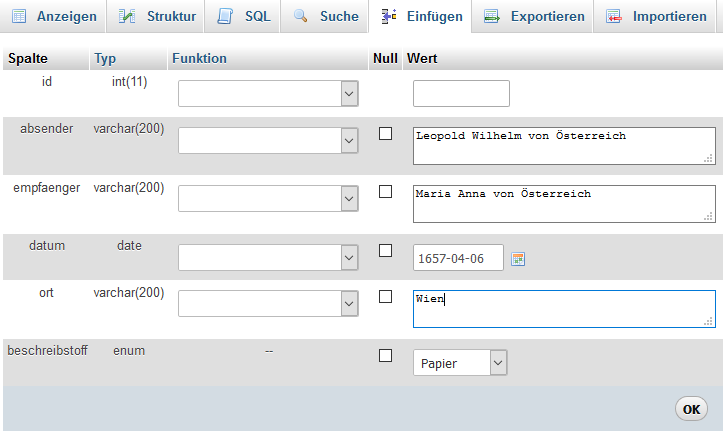
/var/cache/html/dhlehre/html/wp content/uploads/2017/08/1504625296 Summerschool 2017 insert
Wenn das Einfügen erfolgreich war, kann der hinzugefügte Eintrag in der Tabelle angesehen werden:
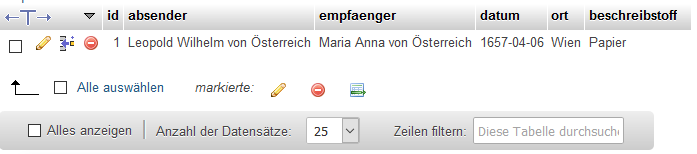
/var/cache/html/dhlehre/html/wp content/uploads/2017/08/1504625499 Summerschool 2017 inserted
0.1.1.1. Zusammenfassung der SQL-Befehle:
1. Create Table (Erzeugen einer neuen Tabelle):
CREATE TABLE Tabellenname (
Spalte1 Datentyp PRIMARY KEY AUTO_INCREMENT,
Spalte2 Datentyp,
Spalte3 Datentyp,
....
);
2. Drop Table (Löschen einer Tabelle):
DROP TABLE Tabellenname;
3. Insert Into (Einfügen von Datensätzen):
INSERT INTO Tabellenname (Spalte1, Spalte2, Spalte3) VALUES (Wer1, Wert2, Wert3);
0.1.2.
0.1.3. Schritt 2: Tokenisierung des Textes und Einlesen der Daten in die Tabelle `tokens`
Um den Text (Brief) in die Datenbank einzulesen, muss dieser zunächst noch umformatiert werden. Grundsätzlich gilt, dass ein Gegenstand umso präziser beschrieben werden kann, in je kleinere Einheiten er zerlegt wird. Im Fall von Texten hat es sich bewährt, diese in einzelne Tokens zu zerlegen. Ein Token ist dabei definiert als eine Zeichenkette zwischen Leerzeichen (Spatien, Blanks). Ein Token ist somit in den allermeisten Fällen identisch mit einem Wort, jedoch nicht immer: Ein Gedankenstrich beispielsweise ist normalerweise durch ein Leerzeichen von dem vorangehenden und dem nachfolgenden Wort getrennt; insofern handelt es sich um ein Token, nicht jedoch um ein Wort.
Beispiel: Ein Satz aus dem Märchen "Die zwei Brüder" von Jacob und Wilhelm Grimm:
er schaute umher , konnte aber nichts bemerken .
Der selbe Satz in tokenisierter Form:
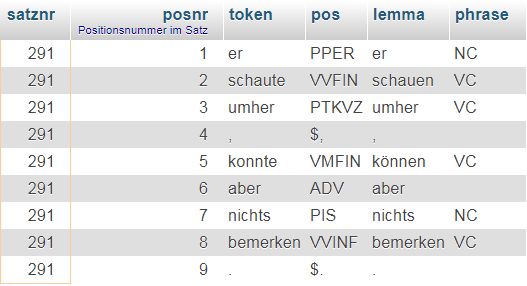
/var/cache/html/dhlehre/html/wp content/uploads/2017/08/1502445772 Tokens grimm
Bei der Zerlegung eines Fließtextes in einzelne Tokens spricht man von Tokenisierung. Jedem Token sind zusätzliche Eigenschaften zugewiesen. So ermöglichen die Satznummer und die Positionsnummer innerhalb des Satzes das gezielte Auffinden eines Tokens im Originaltext. Man spricht in diesem Zusammenhang vom sog. "Referenzsystem". Die Eigenschaften "POS" (= Part of speech = Wortart) und lemma sind morphsyntaktische Eigenheiten, die eine sprachwissenschaftliche Analyse erlauben. Eine bestehende Tabelle kann jederzeit um zusätzliche Zeilen und Spalten erweitert werden.
- Erläuterung Tabelle `tokens` (http://dhvlab.gwi.uni-muenchen.de/sql/index.php?#PMAURL-2:sql.php?db=lab_dhmucschool17&table=tokens&server=1)
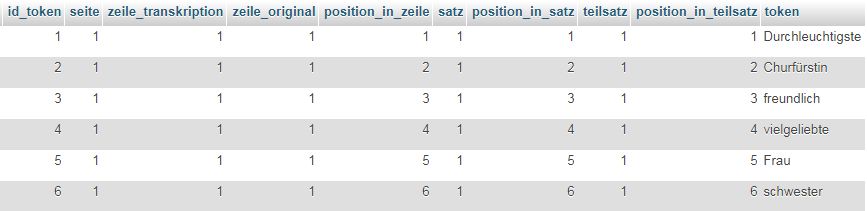
/var/cache/html/dhlehre/html/wp content/uploads/2017/08/1502701651 Summerschool2017 tokens
Die Spalte ganz rechts enthält sämtliche Tokens des Textes. Der Text ist hier gleichsam von oben nach unten zu lesen, man spricht daher auch von einem "Vertikaltext". Bei der Tokenisierung sind verschiedene Dinge zu beachten. So müssen u.a. Satzzeichen, die in Horizontaltexten üblicherweise direkt mit den Wörtern verbunden, also nicht durch Leerzeichen von diesen abgesetzt sind, von durch Einfügung von Leerzeichen von den Wörtern isoliert werden:
hintritt; -> hintritt ;
Ferner muss eine semantische Disambiguierung der im Text vorkommenden Punkte vorgenommen werden. Ein Punkt kann entweder als Satzzeichen oder als Abkürzungszeichen auftreten. Für die automatische Verarbeitung ist eine diesbezügliche Unterscheidung speziell im Hinblick auf die Identifizierung von Satzenden unerlässlich. Im Text begegnet z.B. folgende Abkürzung: E.L. Die Punkte in dieser Abkürzung werden durch Gitterkreuze (auch: Hashes - #) ersetzt, um bei der automatischen Tokenisierung durch eine kleines Computerprogramm die Punkte als Satzbegrenzer auswerten zu können.
E.L. -> E#L#
Wichtig ist, dass das Gitterkreuz im Text ansonsten nicht auftritt, also eindeutig ist - was im gegebenen Beispiel der Fall ist.
Bei der Tokenisierung werden jedem einzelnen Token Informationen beigegeben, die dessen ursprüngliche Position innerhalb des Horizontaltextes dokumentiert. Die Summe all dieser Informationen wird als Referenzsystem bezeichnet. Die wichtigsten Größen dieses Referenzsystems sind:
- Die (Papier-)Seite, auf der sich das Token befindet (`seite`)
- Die Position in Transkriptionsdatei (`zeile_transkription`)
- Die Textzeile auf dieser Seite (`zeile_original`)
- Die Position innerhalb dieser Textzeile (`position_in_zeile`)
- Die Nummer des Satzes bezogen auf den Gesamttext (`satz`)
- Die Position innerhalb eines Satzes (`position_in_satz`)
- Die Nummer eines Teilsatzes innerhalb eines Satzes (`teilsatz`)
- Die Position innerhalb eines Teilsatzes (`position_in_teilsatz`)
Die fehlerfreie Erzeugung des entsprechenden Nummernsystems ist manuell praktisch nicht möglich und wird daher mit Hilfe eines kleinen Computerprogramms erledigt. Als Programmiersprachen kommen z.B. Perl oder Python in Betracht. Im vorliegenden Fall wurde die Aufgabe mit folgendem Skript in der Programmiersprache AWK erledigt:
# awk-script
# ITG/slu, 2017-08
# aufruf: gawk -f tokenize.awk ../in/Transkription_1657.txt > ../out/Transkription.csv
BEGIN {
OFS="\t";
id_object=1; # ID des aktuellen Briefs
seite=1;
zeile_original=1;
j=1;
satz=1;
teilsatz=1;
position_in_satz = 1;
position_in_teilsatz = 1;
position_in_zeile = 1;
# print "id_object",
# "seite", # Kolumnentitel
# "zeile_transkription",
# "zeile_original",
# "position_in_zeile",
# "satz",
# "position_in_satz",
# "teilsatz",
# "position_in_teilsatz",
# "token";
}
{
zeile_transkription = NR;
$0=gensub(/([.,!?;])/," \\1 ","g",$0); # Abtrennung von Satzzeichen
for (i=1;i<=NF;i++) {
token=$i;
if (token=="[/]") { # Zählung der Seitenwechsel
seite++;
}
if (token=="//") { # Zählung der Zeilenwechsel
zeile_original++;
position_in_zeile=1; # Zählung der Wörter innerhalb einer Zeile
}
else {
print id_object,
seite,
zeile_transkription,
zeile_original,
position_in_zeile++,
satz,
position_in_satz++,
teilsatz,
position_in_teilsatz++,
token;
}
if (token~/[.;!?]/) { # Zählung der Sätze - Punkt, Semikolon, Ausrufe- und Fragezeichen definieren Satzende
satz++;
position_in_satz = 1;
}
if (token~/[,]/) { # Zählung der Teilsätze - Komma definiert Teilsatzende
teilsatz++;
position_in_teilsatz = 1;
}
}
}
END {
}
Die Zählung der unterschiedlichen Kategorien (Seite, Satz, Teilsatz) orientiert sich ausschließlich an Formalia, die bei der Anfertigung der Transkription akribisch beachtet worden sein müssen. Es gelten folgende Konventionen:
[/] -> Zählung der Seitenwechsel // -> Zählung der Zeilenwechsel im Original .;!? -> Zählung der Sätze , -> Zählung der Teilsätze
Die Zählung der Sätze und Teilsätze ist rein mechanisch und bildet keinerlei Hierarchien oder Zusammenhänge ab.
Die erste Spalte der Tabelle `tokens` enthält die Id (id), die jede einzelne Zeile der Tabelle eindeutig identifiziert. Die zweite Spalte (id_object) ist ein Fremdschlüssel, der angibt, aus welchem Dokument ein Token stammt. Durch das Definieren von Fremdschlüssel-Beziehnungen wird die referenzielle Integrität der Datenbank gewährleistet.
Der SQL Befehl zum Anlegen der Tabelle stellt sich folgendermaßen dar:
CREATE TABLE tokens ( id int NOT NULL PRIMARY KEY AUTO_INCREMENT, id_object int NOT NULL, seite int, zeile_transkription int, zeile_original int, position_in_zeile int, satz int, position_in_satz int, teilsatz int, position_in_teilsatz int, token varchar(50), FOREIGN KEY (id_object) REFERENCES objects(id) ON DELETE CASCADE ON UPDATE CASCADE ) DEFAULT CHARACTER SET utf8 COLLATE utf8_general_ci;
Soll der Fremdschlüssel nach dem Erstellen der Tabelle angelegt werden, kann folgende SQL-Anweisung abgesetzt werden:
ALTER TABLE tokens ADD CONSTRAINT fk_object FOREIGN KEY (id_object) REFERENCES objects (id) ON DELETE CASCADE ON UPDATE CASCADE;
In phpMyAdmin lässt sich ein Fremdschlüssel mit Hilfe der Beziehungsansicht realisieren:

/var/cache/html/dhlehre/html/wp content/uploads/2017/08/1504647325 Summerschool 2017 fk constraint
Achtung: Es lassen sich nur Spalten als Fremdschlüssel auswählen, auf die ein Index angelegt wurde!
Mit phpMyAdmin können Indizes auch in der Beziehungsansicht hinzugefügt werden:
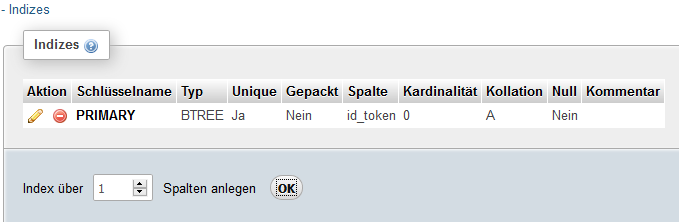
/var/cache/html/dhlehre/html/wp content/uploads/2017/08/1504647643 Summerschool 2017 index 1
Nachdem die Anzahl der Spalten angegeben und der OK-Button geklickt wird, kann der Index spezifiziert werden:
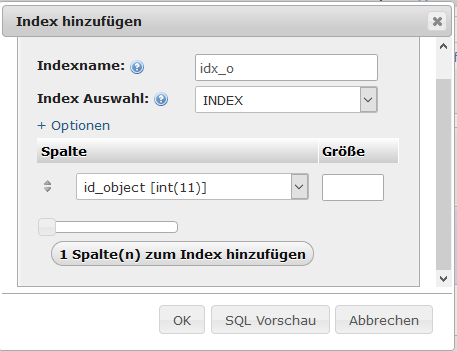
/var/cache/html/dhlehre/html/wp content/uploads/2017/08/1504648071 Summerschool 2017 index 2
Alternativ könnte der Index direkt per SQL-Anweisung hinzugefügt werden:
CREATE INDEX idx_o ON tokens (id_object);
Wenn der Index erfolgreich angelegt wurde, kann die Spalte als Fremdschlüssel genutzt werden und die neue Fremdschlüsselbeziehung ist in der Design-Ansicht sichtbar:
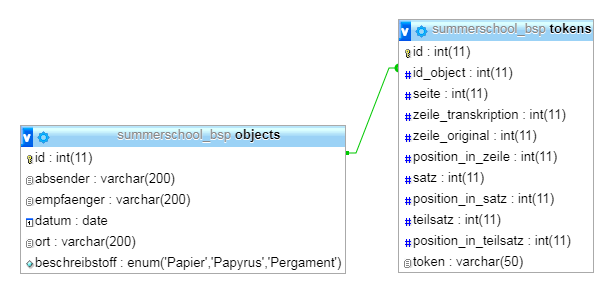
/var/cache/html/dhlehre/html/wp content/uploads/2017/08/1504996321 Summerschool2017 contraint inserted
0.1.3.1. Import der Daten
Nachdem die Tabelle erstellt wurde, wird sie nun mit den Daten aus der .csv - Datei, die das AWK-Skript erstellt hatte befüllt. Hierzu kann in MySQL das Kommando "Load Data Infile" eingegeben werden:
LOAD DATA INFILE '/step1/Transkription_Brief_1.csv INTO TABLE tokens (id_object,seite,zeile_transkription,zeile_original,position_in_zeile,satz,position_in_satz,teilsatz,position_in_teilsatz,token) FIELDS TERMINATED BY '\t' LINES TERMINATED BY '\n';
Einfacher geht der Import und das "Importieren"-Feature von phpMyAdmin:
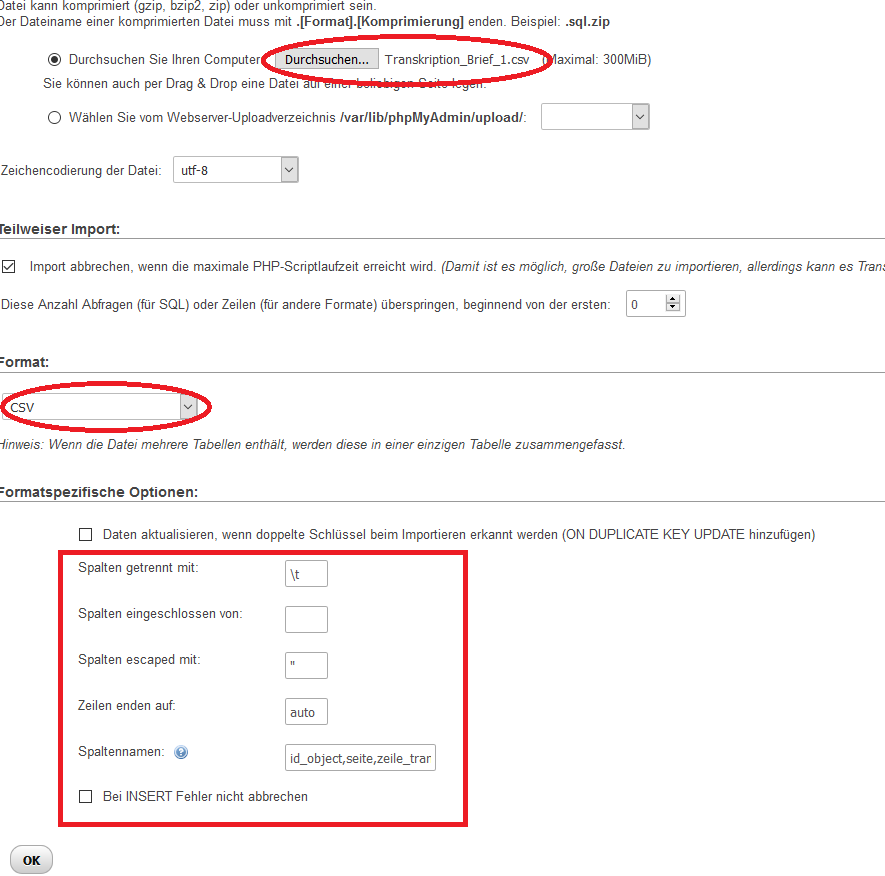
/var/cache/html/dhlehre/html/wp content/uploads/2017/08/1504968905 Summerschool2017 import tokens
Es genügt alle Spalten, bis auf "id" anzugeben, denn diese wird ja automatisch erhöht:
id_object,seite,zeile_transkription,zeile_original,position_in_zeile,satz,position_in_satz,teilsatz,position_in_teilsatz,token
0.1.3.2. Zusammenfassung der SQL-Befehle
1. Alter Table Add Contraint (Erweitern einer Tabelle um einen Fremdschlüssel):
ALTER TABLE tokens ADD CONSTRAINT fk_object FOREIGN KEY (id_object) REFERENCES objects (id) ON DELETE CASCADE ON UPDATE CASCADE;
2. Create Index (Hinzufügen eines Index für eine oder mehrere Spalten):
CREATE INDEX Indexname ON Tabellenname (Spalte1, Spalte2, ..);
3. Load Data Infile (Einlesen einer externen Datei in eine Tabelle):
LOAD DATA INFILE 'Pfad zur Datei/Dateiname' INTO TABLE Tabellenname (Spalte1,Spalte2,..) FIELDS TERMINATED BY 'Field-Terminator' LINES TERMINATED BY 'Line-Terminator';
0.1.4.
0.1.5. Schritt 3: Erweiterung `tokens` mittels Part-of-speech tagging
Unter Part-of-speech tagging (POS-tagging) versteht man die Zuweisung lexikalischer Kategorien (Wortarten) zu den einzelnen Tokens eines Textes. Auf Basis der getaggten Tokens lassen sich dann eine Vielzahl von Auswertung und Analysen vornehmen.
Mit Hilfe computerlinguistischer Verfahren kann das POS-tagging automatisch durchgeführt werden. Ein bewährtes Programm für diesen Zweck ist der "TreeTagger": Hierbei handelt es sich um einen POS-Tagger, der mit unterschiedlichen Sprachmodellen trainiert werden kann. Eine große Anzahl von bereits trainierten Sprachmodellen steht ebenfalls zum Download bereit.
Allerdings kann der TreeTagger nicht direkt von MySQL aus aufgerufen werden. Somit müssen die Daten aus der Tabelle `tokens` nun erst wieder exportiert werden, um das POS-tagging durchzuführen1.
Das Exportieren der Daten lässt sich schnell und bequem mit phpMyAdmin erledigen:
/var/cache/html/dhlehre/html/wp content/uploads/2017/08/1502889187 Summerschool2017 export
Die Verarbeitung der exportierten .csv Datei übernimmt nun ein Python Skript2:
# -*- coding: utf-8 -*-
# ITG/te, 2017-08
import codecs, os
from nltk.corpus import stopwords
import csv
import treetaggerwrapper
def importdata():
result = []
stops = set(stopwords.words('german'))
tagger = treetaggerwrapper.TreeTagger(TAGLANG='de')
filename = "./import/tokens.csv"
with open(filename, newline="\n") as csvfile:
tokenreader = csv.reader(csvfile, delimiter=',', quotechar='\"')
for row in tokenreader:
id = row[0]
word = row[10]
tag = tagger.tag_text(word)
tag2 = treetaggerwrapper.make_tags(tag)
for tag in tag2:
word = tag.word
pos_tag = tag.pos
lemma = tag.lemma
resultstring = []
resultstring.append("UPDATE tokens_step2 SET pos = \"" + pos_tag + "\" where id = "+id+";")
resultstring.append("UPDATE tokens_step2 SET lemma = \"" + lemma + "\" where id = "+id+";")
if word.lower() in stops:
resultstring.append("UPDATE tokens_step2 SET stop = 1 where id = "+id+";")
else:
resultstring.append("UPDATE tokens_step2 SET stop = 0 where id = "+id+";")
resultstring = "\n".join(resultstring)
result.append(resultstring)
file = codecs.open(os.path.normpath("./result/token_step2.sql"), "w", "utf-8")
for item in result:
file.write(item + "\n")
file.close()
if __name__ == '__main__':
importdata()
Um das POS-tagging durchführen zu können, wird die Python-Bibliothek treetaggerwrapper genutzt, die es erlaubt, das zuvor installierte Programm "TreeTagger" von Python aus anzusteuern.
Bevor das Tagging starten kann, muss jedoch die zuvor exportierte .csv Datei eingelesen werden. Dies geschieht mittels der Python-Bibliothek csv. Das Programm iteriert anschließend über alle Zeilen und führt dabei das POS-Tagging aus. Zudem wird auch das Lemma jedes Tokens gespeichert und es wird vermerkt, ob es sich bei dem aktuell verarbeiteten Token um ein Stopwort handelt. Letzteres lässt sich durch den Stopwords Corpus des Natural Language Toolkit (NLTK) bewerkstelligen.
Die Ausgabe dieses Skripts ist nun eine .sql Datei, die die zuvor angelegte Tabelle anhand ihrer IDs (id) um die Spalten "pos" = Part of speech tag, "lemma" = Lemma eines Tokens und "stop" = Boolscher Wert, ob das Token in der Stopwortliste ist erweitert:
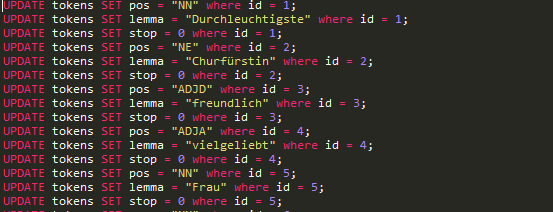
/var/cache/html/dhlehre/html/wp content/uploads/2017/08/1505146086 Summerschool2017 sql skript
Die .sql Datei kann nun einfach wieder mit phpMyAdmin importiert werden. Zuvor müssen allerdings noch die dafür benötigten Spalten angelegt werden. Das Erweitern einer Tabelle mit neuen Spalten geschieht entweder direkt per SQL-Anweisung:
ALTER TABLE tokens ADD pos VARCHAR(25) NOT NULL ; ALTER TABLE tokens ADD lemma VARCHAR(50) NOT NULL ; ALTER TABLE tokens ADD stop TINYINT NOT NULL ;
Oder die neuen Spalten werden wieder mit phpMyAdmin angelegt:
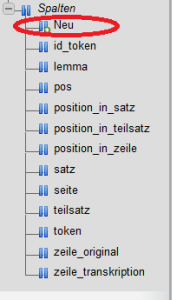
/var/cache/html/dhlehre/html/wp content/uploads/2017/08/1503327867 Summerschool2017 new column1
Wurden die neuen Spalten angelegt, kann nun das SQL-Skript (tokens_step2.sql) importiert werden:
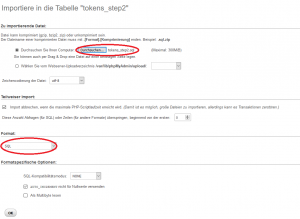
/var/cache/html/dhlehre/html/wp content/uploads/2017/08/1503328581 Summerschool2017 import
War der Import erfolgreich, sind die drei neuen Spalten mit ihren passenden Werten gefüllt. Da es sich bei dem Textbeispiel um ein historisches Dokument handelt, kommt es beim Pos-tagging und der Lemmatisierung natürlich zu Fehlern.
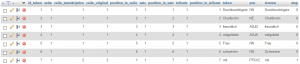
/var/cache/html/dhlehre/html/wp content/uploads/2017/08/1503329290 Summerschool2017 tokens step2
0.1.5.1. Zusammenfassung der SQL-Befehle:
1. Alter Table Add (Erweitern einer Tabelle um eine Spalte):
ALTER TABLE Tabellenname ADD Spaltenname DATENTYP ;
2. Update Statement (Verändern eines bestehenden Datensatzes):
UPDATE Tabellenname SET Spaltenname = Wert WHERE Id-Spalte = X ;
0.1.6.
0.1.7. Schritt 4: Erweiterung der Datenbank um Personen und Orte
Das Auszeichnen von Personen und Orten ist in vielen Texteditionen ein wichtiger und sinnvoller Arbeitsschritt. Zum Beispiel lassen sich so alle Textstellen finden, die auf eine bestimmte Person verweisen oder in den Texten erwähnte Lokalitäten könnten mittels Georeferenzierung verortet werden.
Somit sollte zunächst eine Tabelle angelegt werden, die Personen aufnimmt und ihnen zusätzliche Attribute zuweist, was etwa bei der Verknüpfung der Daten mit anderen Repositorien sehr hilfreich sein kann.
Die Tabelle `persons` soll demnach folgende Spalten beinhalten:
- Id (Int) => Identifier für jeden Datensatz in der Tabelle, Primärschlüssel der Tabelle
- Name (Varchar 200) => Name der Person
- Funktion (Varchar 200) => Wichtigste Funktion, die die Person ausgeübt hat
- Geburtsdatum (Date) => Datum, an dem die Person geboren wurde
- Sterbedatum (Date) => Datum, an dem die Person verstorben ist
- Geburtsort (Varchar 200) => Ort, an dem die Person geboren wurde
- Sterbeort (Varchar 200) => Ort, an dem die Person verstorben ist
- GND (Int) => Identifikator in der Gemeinsamen Normdatei (GND) der Deutschen Staatsbibliothek
Der entsprechende Create Table Befehl sieht so aus:
DROP TABLE IF EXISTS persons;
CREATE TABLE persons(
id INT NOT NULL PRIMARY KEY AUTO_INCREMENT,
name VARCHAR(200),
funktion VARCHAR(200),
geburtsdatum DATE,
sterbedatum DATE,
geburtsort VARCHAR (200),
sterbeort VARCHAR (200),
gnd int
) DEFAULT CHARACTER SET utf8 COLLATE utf8_general_ci;
Da in der Tabelle `objects` mit den Feldern "absender" und "empfaenger" aber ebenfalls auf Personen referenziert wird lohnt es sich hier nun eine weitere Fremdschlüssel-Beziehung zwischen den Tabellen ` objects` und ` persons` anzulegen.
Zunächst müssen dazu die beiden bereits eingefügten Personen (Leopold Wilhelm von Österreich u. Maria Anna von Österreich) in die Datenbank eingefügt werden:
INSERT INTO persons (name,funktion,geburtsdatum,sterbedatum,geburtsort,sterbeort,gnd)
VALUES ("Leopold Wilhelm von Österreich","Erzherzog","1614-01-05","1662-11-20","Wiener Neutstadt","Wien",118727664);
INSERT INTO persons (name,funktion,geburtsdatum,sterbedatum,geburtsort,sterbeort,gnd)
VALUES ("Maria Anna von Österreich","Kurfürstin","1610-01-13","1665-09-25","Graz","München",118893289);
Wie in der Tabelle ` objects` werden die Ids wieder automatisch inkrementiert:

/var/cache/html/dhlehre/html/wp content/uploads/2017/08/1504711774 Summerschool2017 persons inserted
Um nun ` objects` mit ` persons` zu verknüpfen, muss zunächst der Datentyp der Felder "empfaenger und "absender" verändert werden:
ALTER TABLE objects MODIFY empfaenger INT; ALTER TABLE objects MODIFY absender INT;
Da die referenzielle Integrität gewahrt werden muss, müssen die beiden zu verknüpfenden Ids nun manuell in die Tabelle `objects` eingetragen werden. Durch das Modifizieren der Datentypen stehen "absender" und "empfänger" nämlich nun auf 0. Der Wert 0 kann aber nicht mit einer der Personen-Ids referenziert werden, denn in der Tabelle `persons` befinden sich nur Einträge mit 1 und 2.
Die fehlenden Ids lassen sich aber in phpMyAdmin einfach per Mausklick in die gewünschten Felder eintragen:

/var/cache/html/dhlehre/html/wp content/uploads/2017/08/1504734173 Summerschool 2017 objects updated
Alternativ kann natürlich auch wieder ein Update-Statement in SQL verfasst werden.
Bevor "empfaenger" und "absender" in Fremdschlüssel umgewandelt werden können, müssen wieder Indizes angelegt werden:
CREATE INDEX idx_e ON objects (empfaenger); CREATE INDEX idx_a ON objects (absender);
Nachfolgend können die Fremdschlüssel angelegt werden.
ALTER TABLE objects ADD CONSTRAINT fk_e FOREIGN KEY (empfaenger) REFERENCES persons (id) ON DELETE CASCADE ON UPDATE CASCADE; ALTER TABLE objects ADD CONSTRAINT fk_a FOREIGN KEY (absender) REFERENCES persons (id) ON DELETE CASCADE ON UPDATE CASCADE;
Ein Blick in die Design-Ansicht zeigt, dass alles erwartungsgemäß geklappt hat:
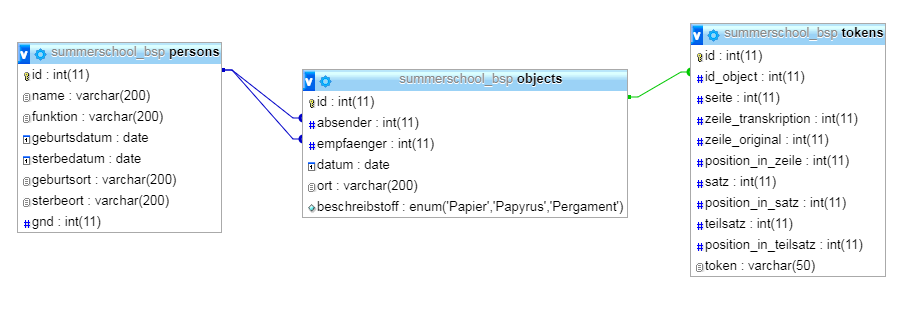
/var/cache/html/dhlehre/html/wp content/uploads/2017/08/1504996596 Summerschool2017 persons created
0.1.7.1. Auszeichnung von Personen innerhalb des Texts
Nach der Verknüpfung der Personentabelle mit der Metadaten-Tabelle soll erstere nun mit der Tokens-Tabelle gekoppelt werden, was es ermöglicht, Personennennungen innerhalb des Briefes in die Datenbank aufzunehmen. Ähnlich zum obigen Beispiel der Tabelle "Mitfahrer", die anzeigte wer in welchem Auto saß kann hier nun eine Tabelle `persons_tokens` (der Unterstrich wird oft als "to" gesprochen) angelegt werden.
Die neue Tabelle enthält somit lediglich zwei Spalten, die jeweils eine Fremdschlüsselbeziehung modellieren:
DROP TABLE IF EXISTS persons_tokens;
CREATE TABLE persons_tokens(
id INT PRIMARY KEY NOT NULL AUTO_INCREMENT,
id_person INT,
id_token INT,
FOREIGN KEY (id_person) REFERENCES persons(id) ON DELETE CASCADE ON UPDATE CASCADE,
FOREIGN KEY (id_token) REFERENCES tokens(id) ON DELETE CASCADE ON UPDATE CASCADE
) DEFAULT CHARACTER SET utf8 COLLATE utf8_general_ci;
Wurde die neue Relationstabelle korrekt erstellt, sieht die Datenbank in der Übersicht so aus:
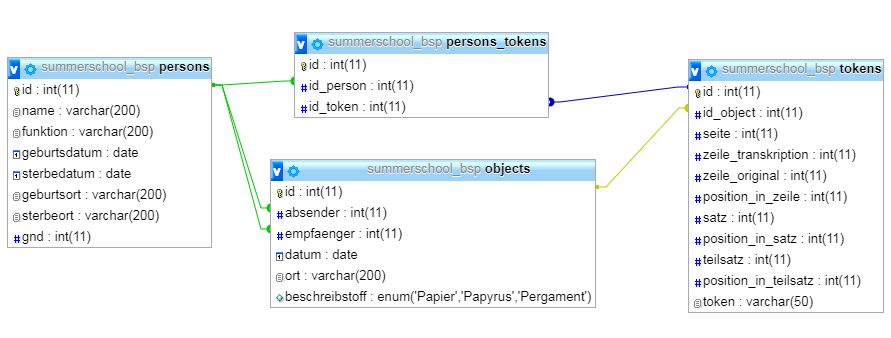
/var/cache/html/dhlehre/html/wp content/uploads/2017/08/1505064651 Summerschool2017 persons tokens created
Ein Eintrag in `persons_tokens` besteht aus einer Personen-Id und einer Token-Id. In einem Eintrag wird ein Token also mit einer Person in Verbindung gebracht.
Dementsprechend müssen für einen Eintrag in die Relationstabelle die Id eines Tokens und die Id einer Person bekannt sein.
Das zweite Token in unserem Brief lautet "Churfürstin":
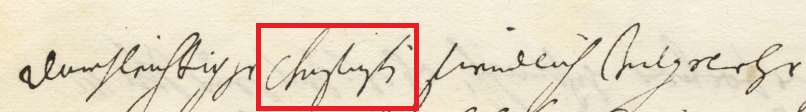
/var/cache/html/dhlehre/html/wp content/uploads/2017/08/1504999632 Token churfurstin
Damit ist die zweite Person in der Personentabelle gemeint, Kurfürstin Maria Anna von Österreich. Also kann, um das Token mit dieser Person zu verbinden folgende SQL-Query formuliert werden:
INSERT INTO persons_tokens (id_person,id_token) VALUES (2,2);
Der Eintrag in die Tabelle zeigt nun die beiden eigenfügten Ids:

/var/cache/html/dhlehre/html/wp content/uploads/2017/08/1504999867 Token 2 inserted
Im Brief zeigt das Token "kaiser" auf Kaiser Ferdinand III und "kaiserin" auf dessen dritte Ehefrau, Eleonora Magdalena Gonzaga von Mantua-Nevers.
 /var/cache/html/dhlehre/html/wp content/uploads/2017/08/1505000832 Ferdinand III Holy Roman Emperor |
 /var/cache/html/dhlehre/html/wp content/uploads/2017/08/1505000860 Eleonora Gonzaga by Frans Luyckx |
Wir fügen also wieder beide Personen der Personentabelle hinzu:
INSERT INTO persons (name,funktion,geburtsdatum,sterbedatum,geburtsort,sterbeort,gnd)
VALUES ("Ferdinand III","Kaiser","1608-07-13","1657-04-02","Graz","Wien",118532529);
INSERT INTO persons (name,funktion,geburtsdatum,sterbedatum,geburtsort,sterbeort,gnd)
VALUES ("Eleonora Magdalena Gonzaga von Mantua-Nevers","Kaiserin","1628-11-18","1686-12-06","Mantua","Wien",118883542);
Und verknüpfen nun das Token "kaiser" mit der Personen-Id 3 und "kaiserin" mit der Personen-Id 4. Im Gegensatz zum Token "Churfürstin" tauchen diese beiden Tokens nun aber öfter auf. Es kann aber einfach die Datenbank selbst genutzt werden, um alle Vorkommen der Tokens herauszusuchen. Im Falle von "kaiserin" kann folgendes geschrieben werden:
SELECT * FROM tokens WHERE token = "kaiserin";
Die Abfrage liefert 12 Vorkommen des Tokens "kaiserin" zurück. Zum Glück kann aber das Insert Into Statement auch verwendet werden, um mehrere Zeilen auf einmal einzufügen:
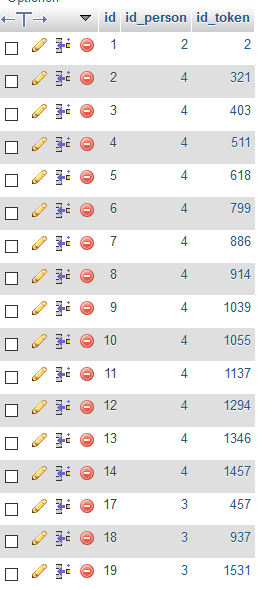
INSERT INTO persons_tokens (id_person,id_token) VALUES (4,321),(4,403),(4,511),(4,618), (4,799),(4,886),(4,914),(4,1039),(4,1055),(4,1137),(4,1294),(4,1346),(4,1457);
Kaiser Ferdinand wird im Brief nur drei mal als "kaiser" erwähnt:
SELECT * FROM tokens WHERE token = "kaiser";
Was das Schreiben des Insert-Statements erleichtert:
INSERT INTO persons_tokens (id_person,id_token) VALUES (3,457),(3,937),(3,1531);
Somit erhalten wir für die drei Tokens "Churfürstin", "kaiser und "kaiserin" folgende Einträge in `persons_tokens`:
/var/cache/html/dhlehre/html/wp content/uploads/2017/08/1505144764 Summerschool2017 persons tokens inserted
Alternative :
INSERT INTO persons_tokens (id_person,id_token) SELECT (Select id from persons where funktion = 'kaiserin') as id_person, id from tokens WHERE token like 'kaiserin'
Auf die gleiche Art und Weise könnten noch mehrere Tokens in die Relationstabelle eingefügt werden, so verweist das Token "kinig" ("König") zum Beispiel auf Leopold I., den Nachfolger von Kaiser Ferdinand, von dessen Ableben im Beispielbrief gesprochen wird. Offen bleibt für den Moment noch die Frage, wie Syntagmen behandelt werden, die gemeinsam auf eine Person zeigen. Zum Beispiel verweisen die Tokens "first von Auersperg", auf den Fürsten Johann Weikhard Fürst von Auersperg, der in Leopold's Regierung eine gewisse Rolle spielte. Diese Problem wird jedoch erst im nächsten Schritt bearbeitet.
0.1.7.2. Erweiterung um Orte sowie Beziehungen von Orten und Tokens
Eine Erweiterung der Datenbank um eine Tabelle für Örtlichkeiten kann analog zur hier beschrieben Vorgehensweise durchgeführt werden. Die Orts-Tabelle `locations` könnte folgende Attribute enthalten:
- Id (Int) => Identifier für jeden Datensatz in der Tabelle, Primärschlüssel der Tabelle
- Name (Varchar 200) => Name des Orts
- Land (Varchar 200) => Land, in dem sich der Ort befindet
- Adresse (Varchar 200) => Adresse des Ortes als String
- Lat (Float) => Breitengrad des Ortes
- Lng (Float) => Längengrad des Ortes
- GND (Int) => Identifikator in der Gemeinsamen Normdatei (GND) der Deutschen Staatsbibliothek (Wenn vorhanden)
Eine dazugehörige Relations-Tabelle `locations_tokens` enthielte wieder zwei Fremdschlüssel, die zusammen den Primärschlüssel bilden:
- Id_location (Int) => Fremdschlüssel aus `locations`
- Id_token (Int) => Fremdschlüssel aus `tokens`
0.1.7.3. Zusammenfassung der SQL-Befehle:
1. Alter Table Modify (Modifizieren des Datentyps einer Spalte):
ALTER TABLE Tabellenname MODIFY Spalte1 Datentyp;
2. Select Statement (Auswählen bestimmter Datensätze):
SELECT Spalte1,Spalte2,Spalte3 FROM Tabellenname WHERE Spalte1 = "XY";
0.1.8.
0.1.9. Schritt 5: Editorische Kategorien und deren Abbildung im relationalen Datenmodell
Neben der Auszeichnung von Personen oder Orten spielen andere editorische Kategorien natürlich ebenso eine große Rolle. Tilgungen bzw. Durchstreichungen oder Einfügungen des Autors sollen ebenso im textkritischen Apparat vermerkt werden wie unleserliche Tokens oder Varianten, die aufgrund von Unsicherheiten bei der Transkription des Dokuments auftreten.
In unserem Beispiel-Brief finden sich etwa auf der dritten Seite eine Durchstreichung und zwei Stellen die bei der Transkription nicht entziffert werden konnten.
Im Original sehen diese Stellen so aus:

/var/cache/html/dhlehre/html/wp content/uploads/2017/08/1504789600 Summerschool2017 bsp brief seite 3
In der entsprechenden Transkription der Briefseite sind diese Stellen korrekt vermerkt:
[/] khinder ihm lassen pefolhn sein und pegert, wir sollen uns alle retirieren. // der kinig retirierte sich auff ein seiten. ich mich mit der kaiserin in ihr // zimerl, sie zue consolieren, den sie im moment nichts getrest hatt, // als wan ich ihr zue gesprochen habe. sie war glaub ich der hungert, wan ich sie // mit gueter manier nit hett machen was essen. nach geschener Beicht, haben Ihr // M. seling sponte als pald mich ruffen lassen. so pin ich pei dem pett // nider gekhniet und gefragt, was sie mir schaffen. [den anderen tag] darauff // sie mich starkh angeschautt und angehebt: sie werden mir erstlich den kinig // über als recomendiert, das ich denselben mit word und thatt asisitieren wollte. // 2ndo die kaiserin mir als sein allerliebste und teuer gemahel zum hechsten anpefohlen. // und ihr über das, was sie vorhin gehabt noch 40/m R. jarlich vermacht. // desgleichen die khlainen schulden von Ihrer ministros und anderer pedienten. wegen // des first von Auersperg diese verba formalia verwendet, das ich ihm khain // unrecht woldte widerfaren lassen. dies habe ich in peisein des gehaimen radt, // welchen man zue samen gerufft hatt, aus firlicher lassen auff sezen. und nach dem // Ihr kais. M. etwas wenigs geweint hetten, gegen […] Ihr […], die gehaim rad // lassen herein g[h]en. Ihren lezten will in peisein ihrer lassen ablesen, welchen sie // in peisein aller pestatigt haben. doch gar schwarlich mehr reden khinden.
Das Tokenisierungsskript (AWK-Skript) erkennt jedoch diese Stellen nicht automatisch3, was bedeutet, dass diese Felder nachträglich gefüllt werden müssen.
Bevor diese Stellen markiert werden können, wird noch eine Tabelle benötigt, die die Informationen zu diesen Tokens abspeichert. Diese Tabelle bekommt den Namen `textcritics` und soll somit alles beinhalten, was in den textkritischen Apparat kommen soll. Für's erste besitzt sie diese Attribute:
- Id_token (Int) => Fremdschlüssel aus `tokens`
- Category (ENUM) => Auswahl einer Kategorie, die angibt um welche Art von Auszeichnung es sich handelt, etwa "d" für "deletion" => Tilgung, "u" für "unreadable" => unleserlich, "v" für "variant" => "Variante" etc.
Allerdings besteht die Tilgung, die wir eintragen wollen aus drei Tokens, ein Problem, das bereits bereits beim Markieren der Personen im Text aufgefallen war. Zur Lösung kann eine neue Tabelle `tokengroups` erstellt werden, deren Zweck es ist mehrere Tokens zu Gruppen zusammenzufassen. Die neue Tabelle besteht somit aus zwei Spalten:
- id (Int) => Identifikator jeder Tokengruppe
- id_token (Int) Fremdschlüssel aus der Tabelle `tokens`
DROP TABLE IF EXISTS tokengroups;
CREATE TABLE tokengroups(
id INT,
id_token INT,
FOREIGN KEY (id_token) REFERENCES tokens(id) ON DELETE CASCADE ON UPDATE CASCADE,
PRIMARY KEY (id,id_token)
) DEFAULT CHARACTER SET utf8 COLLATE utf8_general_ci
Der Eintrag für die Tilgung "den anderen Tag" sollte also so aussehen:
| id | id_token |
| 1 | 710 |
| 1 | 711 |
| 1 | 712 |
Um an die eigentlichen Ids der Tilgung "den anderen tag" zu kommen kann wieder das Select-Statement genutzt werden. Zum Beispiel können wir nach dem Token "schaffen" suchen und dann die folgenden Einträge ansehen, um festzustellen welche Ids die gesuchten Tokens besitzen.
SELECT * FROM tokens WHERE token = "schaffen";
Als Ergebnis erhalten wir die Id Nummer 584. Um die nachfolgenden Ids ausfindig zu machen sagen wir:
SELECT * FROM tokens WHERE id > 584;
An dieser Stelle wurde der Punkt als eigenes Token gespeichert, weshalb die gesuchten Ids 588,589 und 590 sind.
Wir nutzen wieder das Insert-Into Statement und fügen die Token-Ids in die Tabelle ein. Der erste Wert bleibt stets auf 1 gesetzt, da es sich um die erste Tokengruppe handelt:
INSERT INTO tokengroups (id,id_token) VALUES (1,586),(1,587),(1,588);
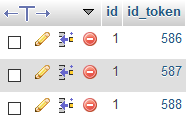
/var/cache/html/dhlehre/html/wp content/uploads/2017/08/1505144963 Summerschool2017 tokengroups inserted
Die Tabelle `textcritics` erhält damit neben dem Fremdschlüssel, der direkt auf eine Token-Id verweist eine Spalte, die eine Tokengruppe referenziert. Damit können entweder einzelne Tokens oder Tokengruppen in die Tabelle aufgenommen werden:
DROP TABLE IF EXISTS textcritics;
CREATE TABLE textcritics(
id INT PRIMARY KEY NOT NULL AUTO_INCREMENT,
id_token INT,
id_tokengroup INT,
category ENUM ('d','u','v'),
FOREIGN KEY (id_token) REFERENCES tokens(id) ON DELETE CASCADE ON UPDATE CASCADE,
FOREIGN KEY (id_tokengroup) REFERENCES tokengroups(id) ON DELETE CASCADE ON UPDATE CASCADE
) DEFAULT CHARACTER SET utf8 COLLATE utf8_general_ci;
Nun kann per Insert-Statement wiederum die Id der Tokengruppe zusammen mit der Kategorie eingefügt werden:
INSERT INTO textcritics (id_tokengroup,category) VALUES (1,'d');
Wenn eine Tokengruppe hinzugefügt wird, bleibt der Wert der Spalte "id_token" leer (null) und umgekehrt. Beispielweise können so die Stellen, die als Unsicherheiten erkannt wurden so in der Tabelle hinzugefügt werden:
INSERT INTO textcritics (id_token,category) VALUES (713,'u'); INSERT INTO textcritics (id_token,category) VALUES (715,'u');
0.1.9.1. Ergänzung Tokengruppen für `persons_tokens`
Mit der Tabelle, die Tokens zu Gruppen zusammenfasst kann nun nach dem gleichen Muster wie gerade auch die Tabelle `persons_tokens` um den Fremdschlüssel für die Tokengruppe erweitert werden.
ALTER TABLE persons_tokens ADD COLUMN id_tokengroup INT; ALTER TABLE persons_tokens ADD CONSTRAINT fk_tokengroup FOREIGN KEY (id_tokengroup) REFERENCES tokengroups (id) ON DELETE CASCADE ON UPDATE CASCADE;
Also Beispiel für einen Eintrag einer Tokengruppe in `persons_tokens` kann nun etwa der, obig bereits erwähnte Ausdruck "first von Auersperg" dienen, dessen Token ids 661,662 und 663 sind:
INSERT INTO tokengroups (id,id_token) VALUES (2,658),(2,659),(2,660);
Da der Fürst von Auersperg noch in der Personen Tabelle fehlt wird auch er schnell hinzugefügt:
INSERT INTO persons (name,funktion,geburtsdatum,sterbedatum,geburtsort,sterbeort,gnd)
VALUES ("Johann Weikhard von Auersperg","Fürst","1615-03-11","1677-11-11","Seisenberg","Laibach",104270136);
Zu guter letzt wird die Beziehung zwischen der neuen Tokengruppe und der neu eingfügten Person (Id 5) hinzugefügt.
Zum Abschluss dieses Schritts ist die Datenbank auf insgesamt 6 Tabellen angewachsen, wobei alle untereinander mit Fremdschlüsseln verknüpft worden sind:
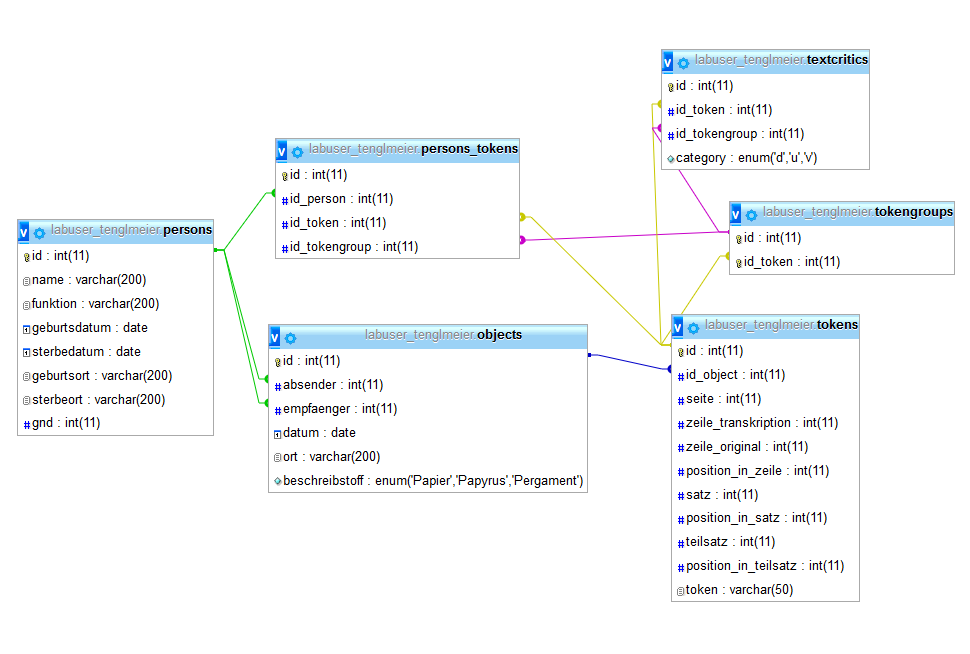
/var/cache/html/dhlehre/html/wp content/uploads/2017/08/1505145397 Summerschool2017 step5 overview
0.1.9.2. Erweiterung um Varianten
Sollen bei unsicheren Tokens nun Alternativen angegeben werden, was ein Token oder eine Tokengruppe geheißen haben könnte wird ein Eintrag in `text_critics` gemacht werden, der mit einen "v" als Kategorie markiert ist. Ähnlich wie eben bei der Erweiterung der Tabelle `persons_tokens` kann, um anzugeben welche Variante gemeint gewesen sein könnte eine Tabelle verknüpft werden, die eben solche Varianten speichert beziehungweise sie mit einem Eintrag in `text_critics` verknüpft.
Hierzu müsste `text_critics` nun wieder um einen Fremdschlüssel erweitert werden, der auf eine neue Relationstabelle zeigt, die alle möglichen Varianten zu diesem Eintrag kodiert. Die Tabelle könnte `text_critics_variants` heißen und folgende Spalten beinhalten:
- id (Int) => Primärschlüssel der Tabelle
- id_variants (Int) => Fremdschlüssel aus `variants`
Zudem müsste eine neue Tabelle `variants` angelegt werden, die wieder alle möglichen Varianten speichert:
- id (Int) => Id der gespeicherten Variante
- token (Varchar 200) => Ein Token in einer Schreibvariante
0.1.10. SQL-Statements
-- Orthographisch unterschiedliche Tokens und deren Anzahl select token, count(*) from tokens group by token ; -- Korrelatsnamen select token, count(*) as anzahl from tokens group by token ; -- Sortierung select token, count(*) from tokens group by token order by anzahl desc ; -- Ausschluss von Stopwörtern select token, count(*) from tokens where stop = 0 group by token order by anzahl desc ; -- Unterschiedliche POS-Tags und deren Anzahl select token, count(*) from tokens group by pos order by anzahl desc ; -- Funktionen select reverse(token), token from tokens ; -- Funktion char_length() select token, char_length(token) from tokens ; -- Ersetzungsfunktion select id, token, replace(token,':','') from tokens where token like '%:' ; /* Rechnen mit MySQL */ -- Arithmetische Operatoren select (1 + 2) / 2 * 5; -- Arithmetische bzw. mathematische Funktionen select round((1 + 2) / 2 * 5 , 2); -- Rundung select pow(2,3); -- Potenz select sqrt(pow(3,2)); -- Quadratwurzel -- Durchschnittliche Wortlänge; geschachtelter Funktionsaufruf -- Möglichkeit 1: select avg(char_length(token)) as `Durchschnittliche Wortlänge` from tokens ; -- Möglichkeit 2: SET group_concat_max_len = 10000000; /* Erweiterung der maximalen Gruppenlänge auf 10 Millionen Zeichen */ select (select char_length(group_concat(token separator '')) from tokens) -- Gesamtlänge aller konkatenierten Tokens / -- arthmetischer Operator: Divisionszeichen (select count(*) from tokens) -- Gesamtanzahl von Tokens as `Durchschnittliche Wortlänge` ; -- Durchschnittliche Satzlänge (Anzahl der Tokens dividiert durch Anzahl der Sätze) select (select count(*) from tokens) -- Anzahl der Tokens / -- Divisionszeichen (select max(satz) from tokens) /* Anzahl der Sätze; die Gruppierungsfunktion max() *ohne* Gruppierungsstatement ermittelt den höchsten Wert im Feld satz */ /* Update */ -- Ersetzung aller Abkürzungszeichen (#) durch Punkte update tokens set token = replace(token,'#','.'); /* Joins */ - Verknüpfung zweier oder mehrerer Tabellen select * from objects join persons; /* Kreuzprodukt, kartesisches Produkt; objects = linke Tabelle persons = rechte Tabelle */ -- Verknüpfung der Tabellen tokens und objects select * from tokens join objects on tokens.id_object = objects.id; /* Synoptische Darstellung der Daten aus den Tabellen objects und persons, zunächst begrenzt auf den Absender */ select persons.name, -- [Tabellenname].[Feldname] persons.funktion, objects.id, objects.empfaenger, objects.ort, objects.beschreibstoff from objects join persons on objects.absender = persons.id ; -- Vereinfachung durch Korrelatsnamen für die Tabellen select b.name, b.funktion, a.id, a.empfaenger, a.ort, a.beschreibstoff from objects as a join persons as b on a.absender = b.id ; -- Join mit Subabfrage, um auch den Namen des Empfängers einbinden zu können SELECT sq1.name as absender, sq1.funktion as `Funktion des Absenders`, c.name as empfaenger, c.funktion as `Funktion des Empfaengers`, sq1.ort, sq1.beschreibstoff, sq1.datum FROM ( select b.name, b.funktion, a.id, a.empfaenger, a.ort, a.beschreibstoff, a.datum from objects as a join persons as b on a.absender = b.id ) as sq1 -- sq steht für "Subabfrage" (Bezeichnung frei wählbar) JOIN persons as c on sq1.empfaenger = c.id ; -- Erzeugung einer Konkordanz select c.id, c.id_object, c.satz, c.vorher, c.token, group_concat(d.token order by d.id separator ' ') nachher -- concat_ws(' ', c.vorher, '>>', c.token, '<<', group_concat(d.token order by d.id separator ' ')) fliesstext from ( select group_concat(a.token order by a.id separator ' ') as vorher, b.id, b.id_object, b.satz, b.token from tokens a right join ( select id, id_object, satz, token from tokens where token like '%' -- HIER SUCHWORT EINTRAGEN collate utf8mb4_general_ci and pos not like '$%' -- Ausschluss von Satzzeichen and token not rlike '.*[0-9].*' -- Ausschluss von Tokens, die Zahlen enthalten -- and posnr = 1 -- HIER WEITERE SUCHKRITERIEN ANFUEGEN ) b on (a.satz=b.satz and a.id<b.id) group by b.id, a.satz ) c left join tokens d on (c.satz=d.satz and d.id>c.id) group by c.id, d.satz order by c.token limit 100 -- Beschränkung auf die ersten 100 Ergebniszeilen ; /* Self-Join: Verknüpfung der Tabelle Tokens mit sich selbst zur Erzeugung von Token- und POS-Triplen */ select count(*) as Anzahl, GROUP_CONCAT(concat_ws(' ',a.token, b.token, c.token) separator ' | ') as Tokens, a.pos, b.pos, c.pos from tokens as a join tokens as b on a.id = b.id-1 join tokens as c on b.id = c.id-1 group by a.pos, b.pos, c.pos order by Anzahl desc ;
-- Textausgabe in XML SELECT -- id_object, -- zeile_original as Zeile_original_Nummer, concat('<zeile_original nr="', zeile_original, '">\n', group_concat( '\t<token pos="', pos, '" lemma="', lemma, '">', token, '</token>' order by id separator '\n'), '\n</zeile_original>') as zeile_original_text FROM `tokens` group by id_object, zeile_original ;
0.1.11. Verschiedenes
Backticks, Hochkommata, Anführungszeichen … (ITG/slu)
Datenmodellierung und relationale Datenbanken (ITG/slu)